




 本文介绍如何使用 SQL 的 GROUP_CONCAT 函数解决多行数据在一行为显示的问题,并演示了去重、排序及设置分隔符的方法。
本文介绍如何使用 SQL 的 GROUP_CONCAT 函数解决多行数据在一行为显示的问题,并演示了去重、排序及设置分隔符的方法。
进公司做的第一个项目就是做一个订单追踪查询,里里外外连接了十一个表,作为公司菜鸡的我麻了爪.
其中有一个需求就是对于多行的数据在一行显示,原谅我才疏学浅 无奈下找到了项目组长 在那学来了这个利器 (他就是我心目中的小SQL王)
完整语法如下
group_concat([DISTINCT] 要连接的字段 [Order BY ASC/DESC 排序字段] [Separator '分隔符'])
SELECT * FROM testgroup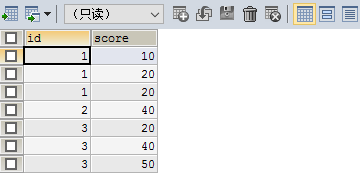
表结构与数据如上
现在的需求就是每个id为一行 在前台每行显示该id所有分数
group_concat 上场!!!
SELECT id,GROUP_CONCAT(score) FROM testgroup GROUP BY id
可以看到 根据id 分成了三行 并且分数默认用 逗号 分割 但是有每个id有重复数据 接下来去重
SELECT id,GROUP_CONCAT(DISTINCT score) FROM testgroup GROUP BY id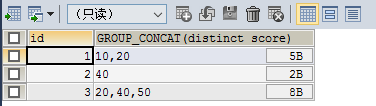
排序
SELECT id,GROUP_CONCAT(score ORDER BY score DESC) FROM testgroup GROUP BY id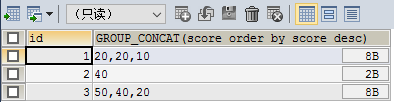
最后可以设置分隔符
SELECT id,GROUP_CONCAT(score SEPARATOR ';') FROM testgroup GROUP BY id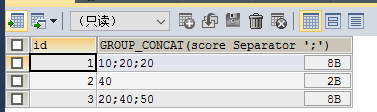
这样我们的数据就根据id 不同分隔符 放在了一行 前台可以根绝对应的分隔符 对score 字段进行分割 但是有可能存在score 数据类型过大问题
达到需求目的!!!

















 4137
4137

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









