







概述
排序主要内部排序和外部排序,即将一个未有序的一组数组,使之成为有序的一组数据。其中内部排序指待排序的记录放在计算机随机存储器中进行的排序过程;而外部排序指待排序的的记录数量很大,以致于内存一次不能容纳全部的记录,在排序过程中尚需对外存进行访问的排序过程。[1]内部排序常用的主要要有8种,分为5类,即如下图:
 [2]
[2]
1. 插入排序
核心思想:将未排序的元素插入一个已经有序的数组中去,使得整个数组变得有序。
过程如图所示:

代码:
void insertSorting(int *arr, int n) {
int i, j;
int tmp;
for (i = 1; i < n; ++i) {
j = i - 1;
tmp = arr[i];
while (j >= 0 && arr[j] > tmp) {
arr[j + 1] = arr[j];
--j;
}
arr[++j] = tmp;
}
}2.希尔排序
核心思想:将一个序列分成若干个子序列,分别对子序列进行插入排序,待所有子序列有序后,再对整个序列进行插入排序。
过程如图所示:
 [3]
[3]
代码:
/******************************************
*
* 希尔排序
*/
void gapSorting(int *arr, int gap, int n) {
int m;
int i, j;
int k;
int temp;
for (m = 0; m < gap; ++m) {
for (i = m + gap; i < n; i += gap) {
for (j = i - gap; j >= m; j -= gap) {
if (arr[i] >= arr[j] || j == m) {
temp = arr[i];
// j == m && arr[j] >= arr[i]
if (arr[j] > arr[i]) {
j -= gap;
}
// copy
for (k = i - gap; k > j; k -= gap) {
arr[k + gap] = arr[k];
}
arr[j + gap] = temp;
break;
}
}
}
}
}
void shellSorting(int *arr, int n) {
int i;
for (i = n / 2; i > 0; i /= 2) {
gapSorting(arr, i, n);
}
}3.简单选择排序
核心思想:每次从未有序的序列中选择一个最大的(最小的)放入到有序的序列中最前面(最后面)。
过程如图:
过程如图:

代码:
/*******************************************************
*
* simple select sorting
*
*******************************************************/
void selectSorting(int *arr, int n) {
int i, j;
// record the pos of min elem
int pos;
// used for swap
int temp;
for (i = 0; i < n - 1; ++i) {
temp = arr[i];
// select one min elem
for (j = i + 1; j < n; ++j) {
if (arr[j] < temp) {
pos = j;
temp = arr[j];
}
}
//swap
arr[pos] = arr[i];
arr[i] = temp;
}
}4堆排序
核心思想:通过二叉堆将一组未有序的数,排序成有序序列。这里主要使用大顶堆。
大顶堆:父节点不比两个子节点小。
如图是一个大顶堆:
 [4]
[4]
我们总是将s+1 - m为
已知一个未有序数组:
{16,7,3,20,17,8}
有一棵完全二叉树:
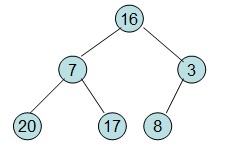 [4]
[4]
已知[s..m]中记录的关键字除s的关键字不满足堆的定义,将其调整为满足堆。
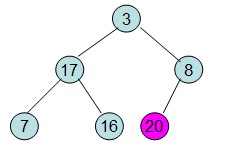 [4]
[4]
红色节点,代表已排好序的, 而现在{3, 17, 8, 7, 16}由于3不满足对的定义即s,故需要调整,调整过程如下(箭头是值为3的节点,移动方向):
 [4]
[4]

代码如下:
/**
* 生成一个大顶堆
* */
void heapAdjust(int *arr, int s, int m) {
int rc = arr[s];
int j;
for (j = 2 * s; j <=m; j *= 2) {
// find index of bigger one
if (j + 2 <= m) {
if (arr[j + 1] < arr[j + 2]) {
j += 2;
} else {
j += 1;
}
} else if (j + 1 <= m) {
j = j + 1;
} else {
break;
}
if(rc >= arr[j]){
break;
}
arr[s] = arr[j];
s = j;
}
arr[s] = rc;
}代码如下:
void heapSort(int *arr, int n) {
int i;
// 将原数组调成大顶堆
for (i = n / 2 - 1; i >= 0; --i) {
heapAdjust(arr, i, n - 1);
}
int temp;
// swap arr[0] and the last elem of unsorting
for (i = n - 1; i > 0; --i) {
temp = arr[i];
arr[i] = arr[0];
arr[0] = temp;
heapAdjust(arr, 0, i - 1);
}
}
5冒泡排序
核心思想:排序因排序类似于水泡上升的过程。
排序如图:
 [1]
[1]
代码:
/*******************************************************
*
* Bubble sorting
*
*******************************************************/
void bubbleSorting(int *arr, int n) {
int i, j;
int temp;
for (i = n - 1; i > 0; --i) {
for (j = 0; j < i; ++j) {
if (arr[j] > arr[j + 1]) {
temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
}
}6快速排序
核心思想:是对冒泡排序的一种改进。它的基本思想,通过一趟排序将待排记录分割成两个独立的两部分,其中一部分记录的关键字均比另一部分记录的关键字小,则可分别对这两部分记录进行排序,已达到整个序列有序。[1]
排序过程如图:
 [1]
[1]
代码如下:
// 将一个从low到high的待排序列找出arr[low]关键字在待排序列中的位置,并返回
int partition(int *arr, int low, int high) {
int pivokey = arr[low];
while (low < high) {
while (low < high && pivokey <= arr[high]) {
--high;
}
arr[low] = arr[high];
while (low < high && arr[low] <= pivokey) {
++low;
}
arr[high] = arr[low];
}
arr[low] = pivokey;
return low;
}
// 快排
void quickSorting(int *arr, int low, int high) {
if (low < high) {
int pt = partition(arr, low, high);
quickSorting(arr, low, pt - 1);
quickSorting(arr, pt + 1, high);
}
}7归并排序
核心思想:利用分治的思想,将两个有序的子序列通过合并使之整个序列有序。
排序如图:

代码:
// 两个有序数组arr[low, mid] 和 arr[mid + 1, high] 将其合并
void merge(int *arr, int low, int mid, int high) {
int len = high - low + 1;
int src[len];
int i, j = 0;
// copy the array
for (i = low; i <= high; ++i) {
src[j++] = arr[i];
}
int low_src = 0;
int mid_src = low_src + mid - low;
int high_src = low_src + high - low;
int k = low;
i =0, j = mid_src + 1;
// copy the src into the arr in sequence
while ( i <= mid_src && j <= high_src) {
if (src[i] <= src[j]) {
arr[k] = src[i++];
} else {
arr[k] = src[j++];
}
++k;
}
// copy the rest
while (i <= mid_src) {
arr[k++] = src[i++];
}
while(j <= high_src) {
arr[k++] = src[j++];
}
}
//归并排序
void mergeSorting(int *arr, int low, int high) {
if (low < high) {
int mid = (high + low) / 2;
mergeSorting(arr, low, mid);
mergeSorting(arr, mid + 1, high);
merge(arr, low, mid, high);
}
}8基数排序
核心思想:利用LSDF(Least Significant Digit first)思想,通过对每一层关键字distribute(分配)和 (collect)收集使得每一层有序(排序要稳定),最终通过所有层distribute和collect,是整个序列有序。
排序过程:

 [1]
[1]
代码:
// 基数
#define RADIX 10
// 数字的位数
#define MAX_BITS 5
// 得到一个数的第time位的数字
int getTime(int key, int time) {
key /= pow(10, time - 1);
return key % 10;
}
// data unit
typedef struct Cell{
int key;
struct Cell *next;
}Cell;
// cell head:just a list
typedef struct CellHeader{
//head node
Cell *next;
// tail node
Cell *tail;
// len of this list
int len;
} *CellList;
//used for collect
struct CellHeader arrayCollection[RADIX];
// print Cell List
void printCellList(CellList l) {
Cell * p = l->next;
while(p) {
printf("%d ", p->key);
p = p->next;
}
printf("\n");
}
// transform an array into a CellList
void transform(CellList *l, int *arr, int len) {
//init List
*l = (CellList)malloc(sizeof(struct CellHeader));
if(*l == NULL) {
printf("allocation failed!\n");
exit(0);
}
(*l)->len = len;
(*l)->next = NULL;
(*l)->tail = NULL;
// add elem of arr into the list
// use tail insert
if(len > 0) {
Cell *cell = (Cell *) malloc(sizeof(Cell));
if (!cell) {
printf("allocation failed\n");
exit(0);
}
cell->next = NULL;
cell->key = arr[0];
(*l)->next = cell;
(*l)->tail = cell;
}
int i;
for (i = 1; i < len; ++i) {
Cell *cell = (Cell *) malloc(sizeof(Cell));
if (!cell) {
printf("allocation failed\n");
exit(0);
}
cell->key = arr[i];
(*l)->tail->next = cell;
cell->next = NULL;
(*l)->tail = cell;
}
}
int count = 0;
// distribute
void distribue(CellList l, int time) {
Cell * p = l->next;
Cell * cur;
int bitkey;
while (p) {
cur = p;
p = cur->next;
bitkey = getTime(cur->key, time);
if(arrayCollection[bitkey].next == NULL) {
arrayCollection[bitkey].next = cur;
arrayCollection[bitkey].tail = cur;
cur->next = NULL;
} else {
arrayCollection[bitkey].tail->next = cur;
cur->next = NULL;
arrayCollection[bitkey].tail = cur;
}
}
l->next = NULL;
l->tail = NULL;
}
// 收集
void collect(CellList l) {
l->tail = NULL;
l->next = NULL;
int i;
Cell *p;
Cell * cur;
for(i = 0; i < RADIX; ++i) {
p = arrayCollection[i].next;
while(p) {
cur = p;
p = cur->next;
if(l->tail == NULL) {
l->next = cur;
l->tail = cur;
cur->next = NULL;
} else {
l->tail->next = cur;
cur->next = NULL;
l->tail = cur;
}
}
arrayCollection[i].next = NULL;
arrayCollection[i].tail = NULL;
}
}
// 基数排序
void RadixSorting(int *arr, int len) {
CellList l;
// transform arr into the list
transform(&l, arr, len);
int i;
for(i = 0; i < MAX_BITS; ++i) {
distribue(l, i + 1);
collect(l);
}
//output
Cell *p = l->next;
printf("output result:\n");
while (p) {
printf("%d ", p->key);
p = p->next;
}
}总结
时间和空间复杂度
 [5]
[5]
参考:
[1]严蔚敏 《数据结构(c语言版)》
[2]http://blog.csdn.net/hguisu/article/details/7776068
[3]http://www.cnblogs.com/jingmoxukong/p/4303279.html
[4]http://blog.csdn.net/cdnight/article/details/11650983
[5]http://www.jianshu.com/p/7d037c332a9d
参考遗漏的,请留言















 2200
2200

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









