







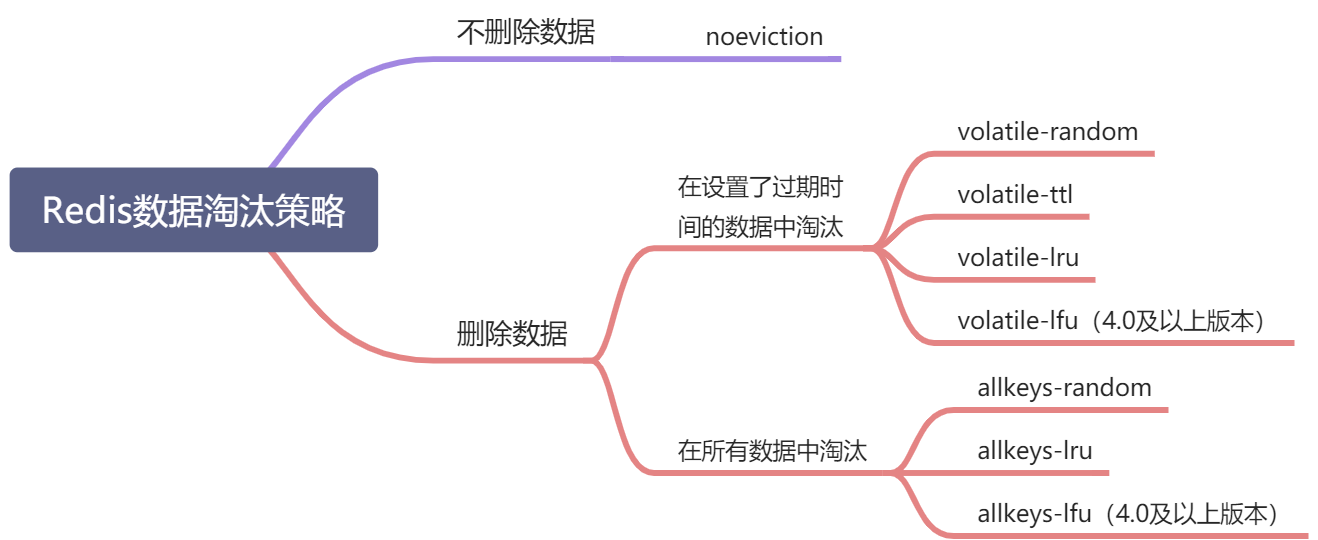
8种淘汰策略
volatile-lru,针对设置了过期时间的key,使用lru算法进行淘汰。
allkeys-lru,针对所有key使用lru算法进行淘汰。
volatile-lfu,针对设置了过期时间的key,使用lfu算法进行淘汰。
allkeys-lfu,针对所有key使用lfu算法进行淘汰。
volatile-random,从所有设置了过期时间的key中使用随机淘汰的方式进行淘汰。
allkeys-random,针对所有的key使用随机淘汰机制进行淘汰。
volatile-ttl,删除生存时间最近的一个键。
noeviction(默认),不删除键,值返回错误。
主要是4种算法,针对不同的key,形成的策略。
算法:
lru 最近很少的使用的key(根据时间,最不常用的淘汰)
lfu 最近很少的使用的key (根据计数器,用的次数最少的key淘汰)
random 随机淘汰
ttl 快要过期的先淘汰
key :
volatile 有过期的时间的那些key
allkeys 所有的key
内存淘汰算法的具体工作原理
客户端执行一条新命令,导致数据库需要增加数据(比如set key value)
Redis会检查内存使用,如果内存使用超过 maxmemory,就会按照置换策略删除一些 key
新的命令执行成功
lru算法
原生lru算法
LRU是Least Recently Used的缩写,也就是表示最近很少使用,也可以理解成最久没有使用。也就是说当内存不够的时候,每次添加一条数据,都需要抛弃一条最久时间没有使用的旧数据。标准的LRU算法为了降低查找和删除元素的时间复杂度,一般采用Hash表和双向链表结合的数据结构,hash表可以赋予链表快速查找到某个key是否存在链表中,同时可以快速删除、添加节点,如图所示。
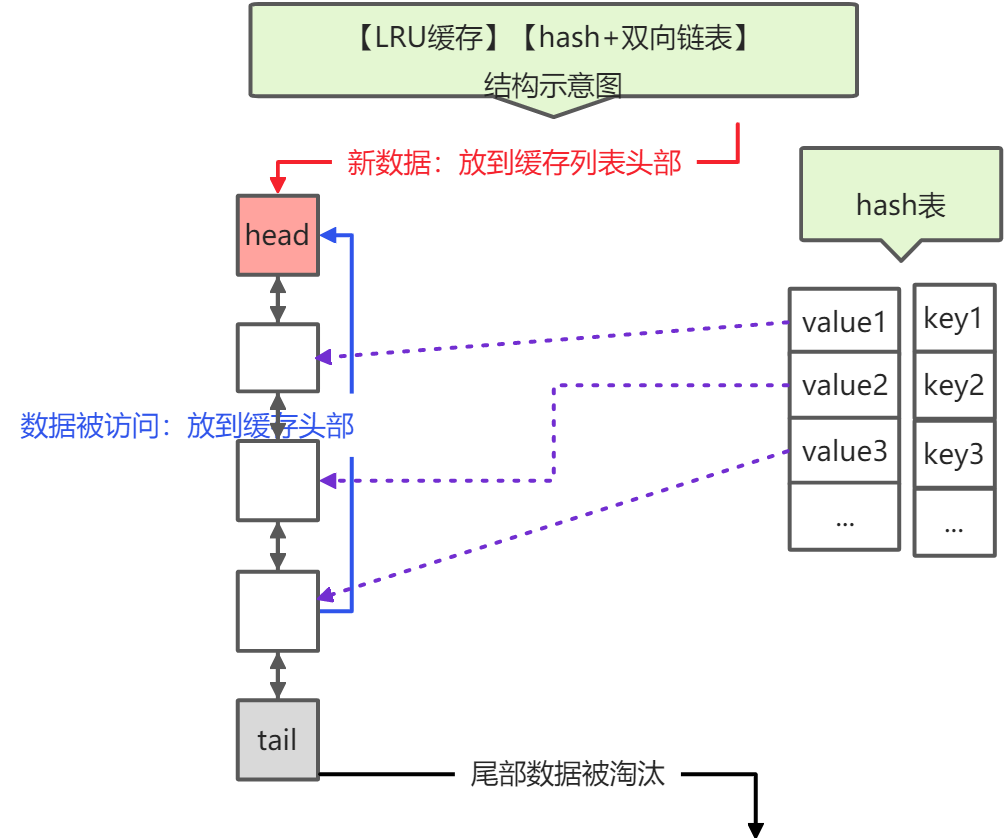
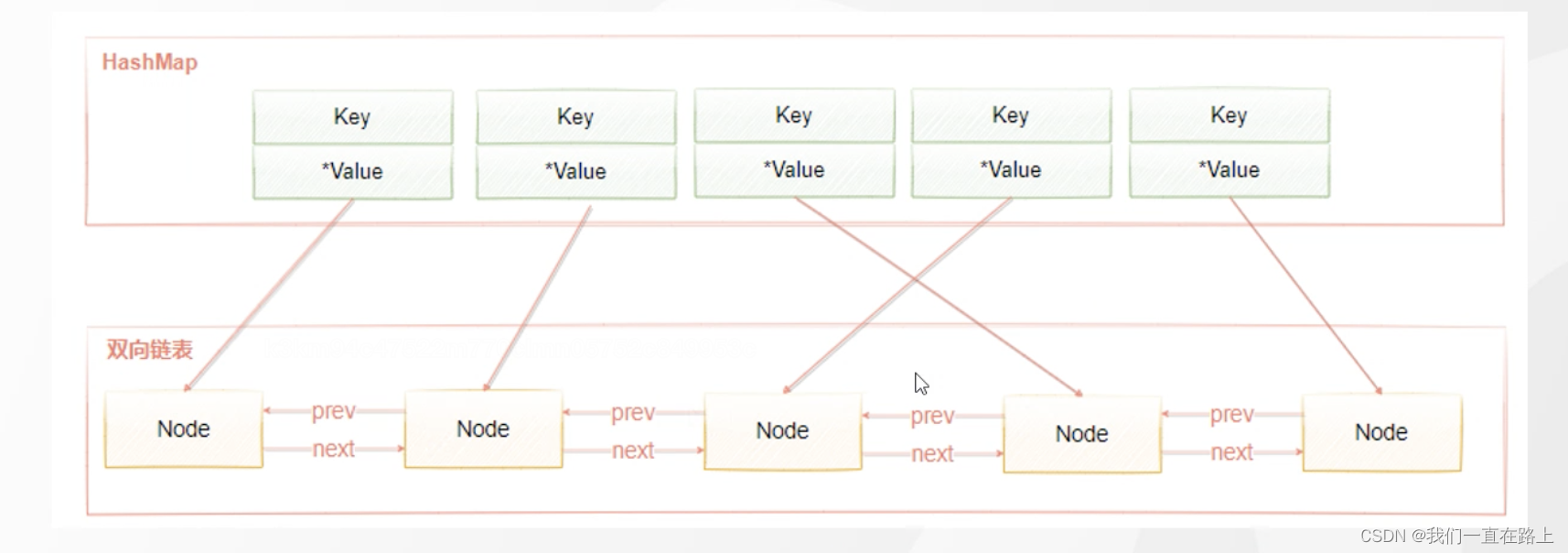
双向链表的查找时间复杂度是O(n),删除和插入是O(1),借助HashMap结构,可以使得查找的时间复杂度变成O(1),Hash表用来查询在链表中的数据位置,链表负责数据的插入。
为什么是 双向链表而不是单链表呢?单链表可以实现头部插入新节点、尾部删除旧节点的时间复杂度都是O(1),但是对于中间节点时间复杂度是O(n),因为对于中间节点c,我们需要将该节点c移动到头部,此时只知道他的下一个节点,要知道其上一个节点需要遍历整个链表,时间复杂度为O(n)。
当新数据插入到链表头部时有两种情况
- 当链表中没有这个key,且链表满了,把链表尾部的数据丢弃掉,新加入的缓存直接加入到链表头中。
- 当链表中的某个缓存被命中时,直接把数据移到链表头部,原本在头节点的缓存就向链表尾部移动
这样,经过多次Cache操作之后,最近被命中的缓存,都会存在链表头部的方向,没有命中的,都会在链表尾部方向,当需要替换内容时,由于链表尾部是最少被命中的,我们只需要淘汰链表尾部的数据即可。
Redis为什么不使用原生LRU算法?
原生LRU算法需要 双向链表 来管理数据,需要额外内存;
数据访问时涉及数据移动,有性能损耗;
Redis现有数据结构需要改造;
redis中的lru算法
首次淘汰:随机抽样选出【最多N个数据】放入【待淘汰数据池 evictionPoolEntry】;
数据量N:由 redis.conf 配置的 maxmemory-samples 决定,默认值是5,配置为10将非常接近真实LRU效果,但是更消耗CPU;
samples:n.样本;v.抽样;
再次淘汰:随机抽样选出【最多N个数据】,只要数据比【待淘汰数据池 evictionPoolEntry】中的【任意一条】数据的 lru 小,则将该数据填充至 【待淘汰数据池】;
evictionPoolEntry 的容容量是 EVPOOL_SIZE = 16;
详见 源码 中 evictionPoolPopulate 方法的注释;
执行淘汰: 挑选【待淘汰数据池】中 lru 最小的一条数据进行淘汰;
Redis为了避免长时间或一直找不到足够的数据填充【待淘汰数据池】,代码里(dictGetSomeKeys 方法)强制写死了单次寻找数据的最大次数是 [maxsteps = count*10; ],count 的值其实就是 maxmemory-samples。从这里我们也可以获得另一个重要信息:单次获取的数据可能达不到 maxmemory-samples 个。此外,如果Redis数据量(所有数据 或 有过期时间 的数据)本身就比 maxmemory-samples 小,那么 count 值等于 Redis 中数据量个数。
缺点:
LRU算法有一个弊端,加入一个key值访问频率很低,但是最近一次被访问到了,那LRU会认为它是热点数据,不会被淘汰。同样,
经常被访问的数据,最近一段时间没有被访问,这样会导致这些数据被淘汰掉,导致误判而淘汰掉热点数据,于是在Redis 4.0中,新加了一种LFU算法。
lfu算法
LFU(Least Frequently Used),表示最近最少使用,它和key的使用次数有关,其思想是:根据key最近被访问的频率进行淘汰,比较少访问的key优先淘汰,反之则保留。
LRU的原理是使用计数器来对key进行排序,每次key被访问时,计数器会增大,当计数器越大,意味着当前key的访问越频繁,也就是意味着它是热点数据。 它很好的解决了LRU算法的缺陷:一个很久没有被访问的key,偶尔被访问一次,导致被误认为是热点数据的问题。
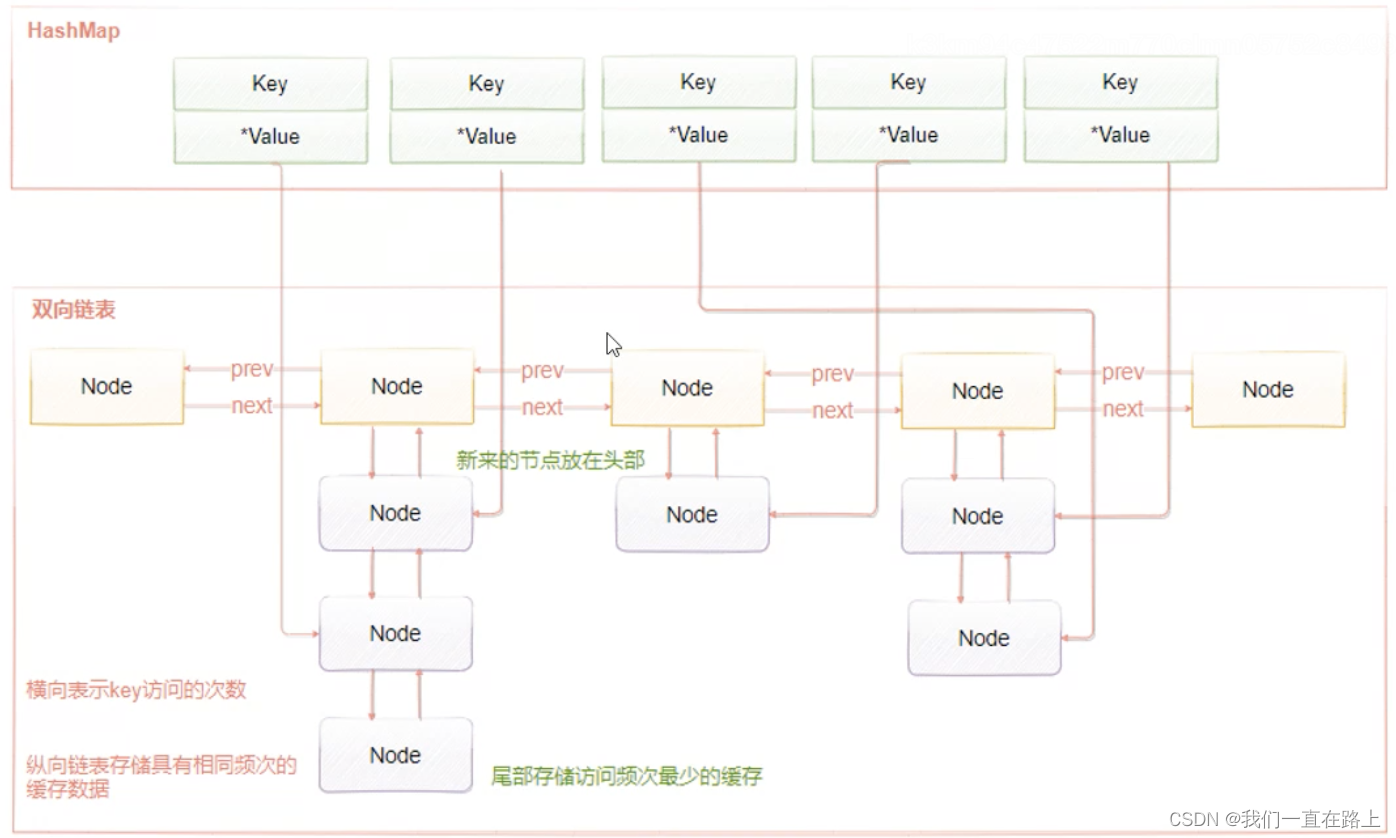
LFU维护了两个链表,横向组成的链表用来存储访问频率,每个访问频率的节点下存储另外一个具有相同访问频率的缓存数据。具体的工作原理是:
当添加元素时,找到相同访问频次的节点,然后添加到该节点的数据链表的头部。如果该数据链表满了,则移除链表尾部的节点当获取元素或者修改元素是,都会增加对应key的访问频次,并把当前节点移动到下一个频次节点。
添加元素时,访问频率默认为1,随着访问次数的增加,频率不断递增。而当前被访问的元素也会随着频率增加进行移动。
来源:https://blog.csdn.net/weixin_40980639/article/details/125446002
https://zxiaofan.blog.csdn.net/article/details/110357096















 1945
1945











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









