







1. 一颗索引树有多高
我们知道在B+树的非叶节点和叶节点上都是用页的方式存储数据,页是InnoDB存储引擎中最小的存储单元,一页的大小默认是16K。
mysql > show variables like ‘innodb_page_size’
可以通过这个命令来查看,当然这个大小也是可以通过参数配置。
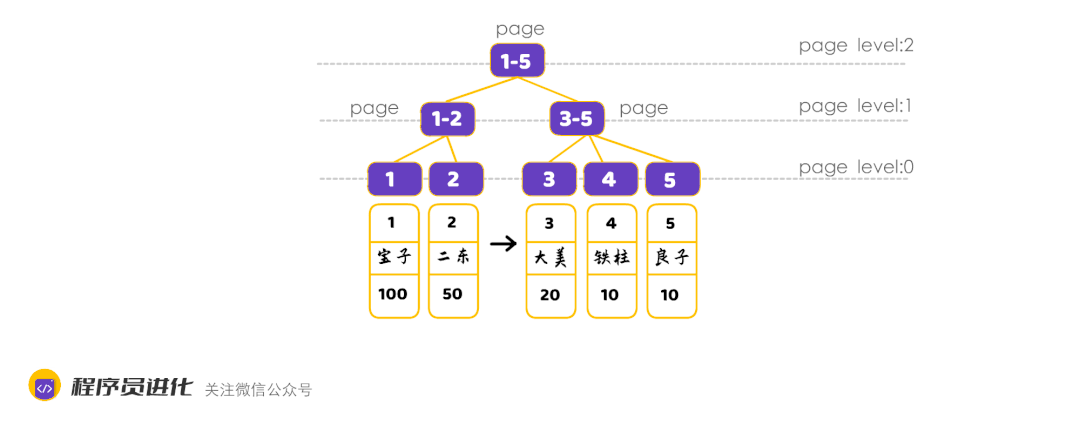
在叶子节点上页可以用来存放记录数据,而非叶子节点上用来存放键值和指针。
我们通过索引组织在查找数据时,指针指在哪个页上,就要进行I/O加载数据。
所以,我们可以得出第一个结论:
B+树索引结构作为一个平衡树,每个叶子节点到根节点的高度都是一样的,索引树越高,I/O的请求次数越多,而我们使用索引的目标就是降低I/O请求次数。
非叶子节点存储指针和主键,主键ID设置bigint类型,长度为8字节,而指针在InnoDb源码中设置为6字节,一共14个字节,那一个页中就能存储 16*1024/(8+6) = 1170.
叶子节点存储数据记录,我们假设一行数据的大小是1K左右,那16K就可以存16条数据。
那么如果B+索引树的高度为2,那能存放的记录为1170*16 = 19720条。
那么如果树的高度为3,那存放的记录为1170117016 = 21902400,虽然这只是估算,但3层高度就可以达到2千万级的数据存储,在一些大厂里要求数据超过2千万即要分库分表,也是为了保证索引效率。
2. mysql为什么建议自增id
- 因为id自增占用的空间比uuid要小,mysql存储是页为单位,主键占用的空间越小,存储的数据越多,这样减少树的高度.
- 自增id,在添加数据的时候直接放到末尾,如果超过了16k,新添加页,如果非自增id,需要比较大小后找合适的位置,因为uuid一般都
会存放到页的中间某个位置,如果恰巧超过了16k,这个时候就要页分裂,导致效率变低.。
说说什么是页分裂吧
当我们向某个索引对应的B+树插入记录,需要先定位到这条记录应该被插入到哪个叶子节点对应的数据页中,确定之后有两种情况:
①该页恰好空间足够,能直接插入数据
②该页空间不足,不能直接插入数据
我们把该页称为页A
对于第一种情况,数据可以直接插入页A而不会产生其他影响;
对于第二种情况,页A空间不足,但数据需要插入页A,那就需要进行页分裂;
页分裂过程
创建一个新页B,将页A中的部分数据转移到页B中,这样就页A能空出多余的空间存储新纪录,再将页B添加到叶子节点的链表中;
但这还没完,由于叶子节点链表发生了变化,记录叶子节点情况的上一层,也需要发生一些变化,来记录这个新插入的页B,也就是在内节点添加一条目录项记录,来指向这个新创建的页B;
当然,如果作为内节点的页剩余空间也不足够容纳新增一条目录记录项,那么该内节点也会发生页分裂;
显而易见,插入数据时发生页分裂会降低性能;
3. mysql中的页
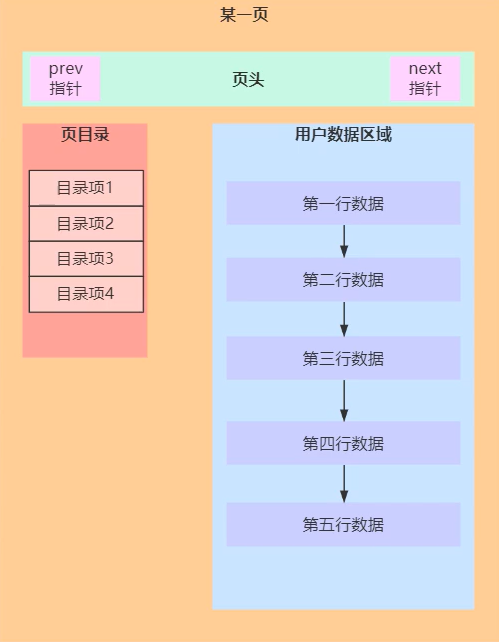
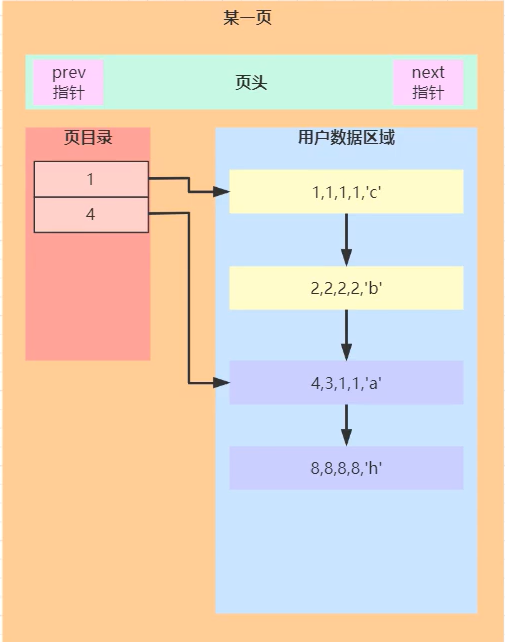
页目录
用户数据区域数据查询的时候复杂度是O(n),为了提交检索效率,增加了页目录。
类似文章的目录
第一章 1 (第一章存储了1-101数据)
第二章 102 (第二章存储了102-255数据)
第三章 256
4. mysql索引叶子节点为什么是双向指针(范围查找是否走索引)
select * from t1 where a>5;

从执行计划可以看出是走索引的,其实是根据a=5这个索引值去查找数据,当在叶子页面找到数据以后,跳过a=5这行数据,后面的就是a>5的数据。
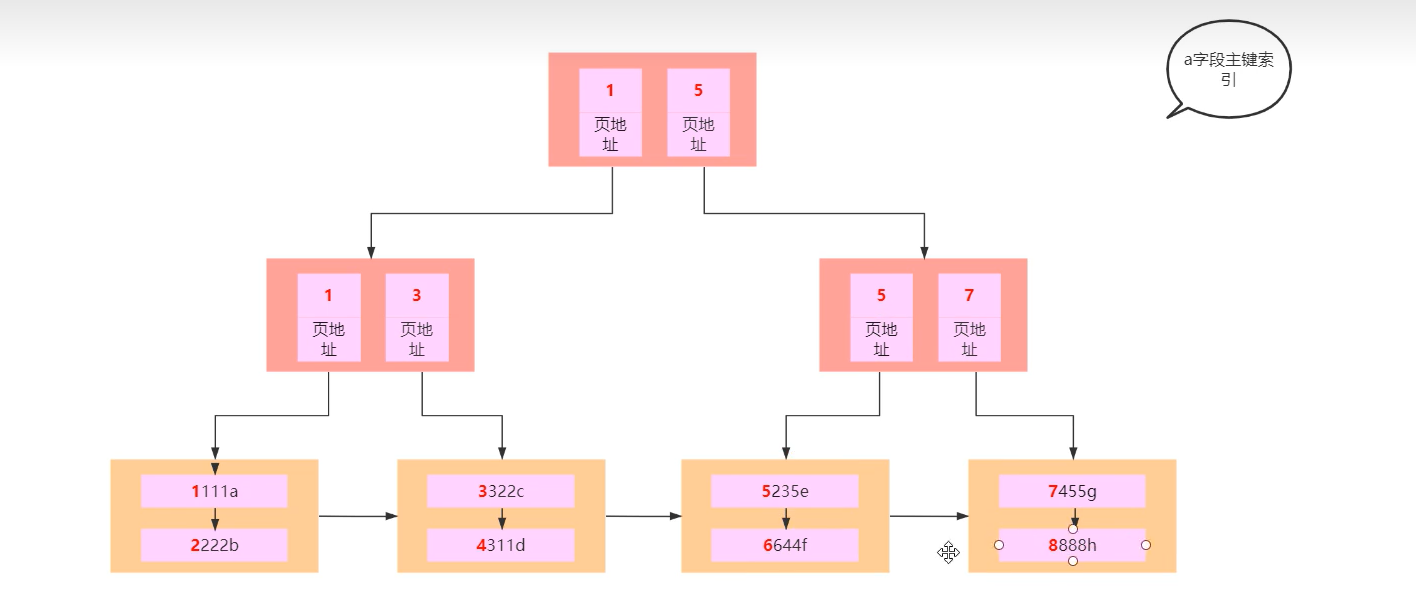
select * from t1 where a<5;

从执行计划可以看出是走索引的,其实是根据a=5这个索引值去查找数据,当在叶子页面找到数据以后,跳过a=5这行数据,前面的就是a>5的数据。【叶子节点之前是双向链表】
来源:视频链接:https://www.bilibili.com/video/BV1w34y1m7MM?p=16&vd_source=b901ef0e9ed712b24882863596eab0ca
一颗索引树有多高:https://www.modb.pro/db/194137
mysql为什么建议自增id:https://www.jianshu.com/p/730a117f4375
页分裂:https://www.cnblogs.com/TBAGC/p/17044918.html















 415
415











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









