






一、跟Solr Cloud、ElasticSearch区别
谈到YDB的索引技术,相信很多同学都会想到Solr、ElasticSearch。他们俩真可谓是大名鼎鼎,是两个顶级项目,最近有些同学经常问我,“开源世界有Solr、ElasticSearch为什么还要使用YDB?”
在回答这个问题之前,大家可以思考一个问题,既然已经有了Oracle、MySQL等数据库为什么大家还要使用Hadoop下的Hive、Spark? Oracle和Mysql也有集群版,也可以分布式,那Hadoop与Hive的出现是不是多余的?
YDB的出现,并不是为了替代Solr、ES的,就像Hadoop的出现并不是为了干掉Oracle和Mysql一样。而是为了满足不同层面的需求。
1.延云Ydb与 Solr/ES 的几点对比
1)分词
solr/ES:
对于邮箱、手机号、车牌号码、网址、IP地址、程序类名、含有字母与数字的组合之类的数据会匹配不完整,导致数据查不全,因分词导致漏查以及缺失数据,对于模糊检索有精确匹配要求的场景下,业务存在较大的风险。
YDB:
内置的分词类型会确保查询准确度,不会出现漏查,内置的分词类型,很好的解决了lucene默认分词导致的查询数据缺失的问题。另外YDB可以自定义拓展任意的luene分词类型。如词库分词,语义分词,拼音分词等。
2)排序
solr/ES:
采用lucene的Sort接口实现,本质是借助docvalues的暴力扫描,如果数据量很大排序过程耗费非常多的内存与IO,并且排序耗时很高。
YDB:
按照时间逆序排序可以说是很多日志系统的硬指标。在延云YDB系统中,我们改变了传统的暴力排序方式,通过索引技术,可以超快对数据进行单列排序,不需要全表暴力扫描,这个技术我们称之为blockSort,目前支持tlong,tdouble,tint,tfloat四种数据类型。
由于blockSort是借助搜索的索引来实现的,所以,采用blockSort的排序,不需要暴力扫描,性能有大幅度的提升。
详细测试请参考 http://blog.csdn.NET/qq_33160722/article/details/54447022
3)模糊匹配
solr/ES:
基于lucene的分词来实现,但并不考虑单词的匹配顺序,也不保证匹配词语的连续性,中间可以穿插其他单词。
YDB:
1.除了常规lucene的分词匹配外,YDB还支持类似SQL中的like匹配。
即考虑到了单词之间的匹配顺序,也保证了匹配词语的连续性,也可以通过*进行模糊查询。
这个like也使用了lucene倒排索引,并非采用暴力扫描实现,故like性能比常规实现高很多,
2.除了常规匹配外,YDB也提供了额外的近似文本匹配与近似特征匹配。
近似文本匹配适合对长文本(如文章)进行匹配,可能中间相差几个字不或者局部的字顺序前后颠倒都没关系,只要大部分相似就可以匹配上。
近似特征匹配适合我指定一系列的特征,如高矮,胖瘦,年龄段,性别,时间等一系列目击者看到的嫌疑人特征,但是有可能有些目击者描述的不准确,所以不能进行精确匹配,如果能与大部分的匹配条件都相似,一两个条件没匹配上,但已经足以相似了,那么也要返回匹配结果。
4)用户接口
solr/es:
采用Java API的方式,用户学习成本高。
因不是通用的通讯协议,与其他大数据系统集成对接麻烦。
YDB:
采用SQL的方式,用户学习陈本低。
支持HIVE的JDBC接入(编程),可以命令行接入(定时任务),http方式接入。
Hive的JDBC协议,已经是大数据的事实标准。
与常规大数据系统可无缝对接(如hive,spark,kafka等),也提供了拓展接口。
海量数据导入导出灵活方便,也可与常见的支持jdbc的报表工具、SQL可视化工具集成。
5)函数与功能
solr/es:
只支持简单的检索过滤,sum,max,min,avg等统计函数,单列group by
YDB:
除了solr/ES的简单功能外,内置了HIVE上百个函数,支持复杂的SQL,可以嵌套,多表关联,自定义udf,udaf,udtf,开源界已经有的函数库如Hivemall等也可以直接集成进来使用。
相对于solr/ES除了基本的数据检索外,还能做更复杂的分析。如:数据碰撞分析\同行车辆分析\陌生车辆分析\昼伏夜出、落脚点分析\ OLAP之多维分析\指数分析\人群画像\嫌疑车辆分析等。
6)数据导出
solr/es:
数据如若想导出到其他系统很难,大数据量原始数据的导出基本是不可行的,更别提还要将原始数据经过各种复杂计算后的清洗后的导出了。
YDB:
支持原始数据的任意维度导出
可以全表,也可以通过过滤筛选局部导出
支持数据经过各种组合计算过滤后的导出
可以将YDB中的多个表与其他系统的多个表,进行组合筛选过滤计算后在导出
可以将多个数据从ydb的一张表导入到YDB的另外一张表
可以将YDB里面的数据导出到别的系统里面(如hive,Hbase,数据库等)
也可以将其他系统的数据导入到YDB里面。
可以导出成文件,也可以从文件导入。
可以从kafka流式导入,也可以写插件,导出到kafka。
7)数据导入
solr/es:
采用API的方式导入数据
1.支持实时导入,在千万数据规模下导入性能较好。
2.数据过亿后,生产系统实时导入经常会出现OOM,以及CPU负载太高的问题,故过亿数据无法实时导入数据,一般过百亿的系统均采用离线创建索引的方式,即数据时效性延迟一天。
3.没有良好的合并控制策略,系统会发生阶段性(几分钟)的负载极高的情况(索引合并),此时系统资源占用特别高,前台查询响应速度极慢。
YDB:
采用SQL方式的批量导入,也支持kafka的流式导入
1.索引的设计实现,不会想solr与es那样将数据全部加载到内种内存中进行映射,这无论是在导入还是在查询过程中均大幅的减少了OOM的风险。
2.在内存与磁盘多个区域不同合并策略,在结合控速逻辑,让导入占用的性能控制在一定范围之内,让系统更平稳,尽量减少索引合并瞬间产生的几分钟占据了大量的资源的情况,分散资源的占用,让前台用户的查询更平稳。
3.结合了storm流式处理的优点,采用对接消息队列(如kafka)的方式,数据导入kafka后大约1~2分钟即可在ydb中查到。
8)数据存储与恢复
solr/es:
索引存储在本地硬盘,恢复难
1.磁盘读写没有很好的控速机制,导入数据没有良好的流量控制机制,无法控制流量,而生产系统,磁盘控速与流量控速是必须的,不能因为业务高峰对系统造成较大的冲击,导致磁盘都hang住或挂掉。
2.本地硬盘局部坏点,造成局部数据损坏对于lucene来说无法识别,但是对于索引来说哪怕是仅仅一个byte数据的读异常,就会造成索引指针的错乱,导致检索结果数据丢失,甚至整个索引废掉,但是solr与es不能及时的发现并修正这些错误。
3.数据存储在本地磁盘,一旦本地将近20T的存储盘损坏,需要从副本恢复后才能继续服务,恢复时间太长。
YDB:
将数据存储在HDFS之上
1.YDB基于HDFS做了磁盘与网络做了读写控速逻辑。
2.磁盘局部坏点hdfs配有crc32校验,有坏点会立即发现,并不影响服务,会自动切换到没有坏点的数据继续读取。
3.本地磁盘损坏,HDFS自动恢复数据,不会中断读写,不会有服务中断。
9)数据迁移
solr/es:
1.如若夸机房搬迁机器,需要运维人员细心的进行索引1对1复制,搬迁方案往往要数星期,且非常容易出错。
2.迁移过程中为了保证数据的一致性,需要中断服务或者中断数据的实时导入,让数据静态化落地后不允许在变化后,才能进行迁移。
YDB:
1.hdfs通过balance自动迁移数据。
2.可以控制迁移过程中的带宽流量。
2.迁移过程中不中断服务,hdfs扩容与移除机器也对服务没影响。
10)范围查找性能更佳
范围查找,尤其是时间范围的查找,在日常检索中会被经常使用,在范围查找中跳跃表的利用与否对性能影响非常大,针对多个条件组合筛选的情况,YDB会更充分的利用跳跃功能,让让范围查找性能更高
。具体原理请参考http://blog.csdn.Net/qq_33160722/article/details/54782969
solr/es:
大范围的term扫描(超过16个term的情形),采用暴力读取doclist的方式,并没有使用skip功能,doclist本很成为瓶颈。
doclist用来存储一个term对应的doc id的列表,由于数据量很大,有些term可能达数亿甚至几十亿个,这种大范围查找会导致lucene性能特别低下。
对于文档数量较少的范围查找,是否使用了跳跃功能对性能影响不大,但是YDB的场景更偏重大数据场景,倒排表对应的skiplist会特别长,如果没有使用跳跃功能就会出现上面那种一个查询耗费几个GB的IO的情况,严重影响查询性能。
YDB:
lucene这样优化是有明显的原因的,即当term数量特别多的时候,跳跃的功能会带来更多的随机读,相反性能会更差。
但显然对于海量数据的情况下不适用,因IO巨大导致检索性能很慢,YDB针对范围查找做了如下的变更改动
16个term真的太小太小,我们更改为1024个,针对tlong,tint,tfloat,tdouble类型的数据将会有特别高的扫描性能。
大多时候term对应的skiplist也是有数据倾斜的,尤其是tlong,ting,tfloat,tdouble类型本身的分层特性。对于有数据倾斜的term我们要区别对待,对于skiplist很长的term采用跳跃功能能显著减少IO,对于skiplist很短的term则采用顺序读取,遍历的方式,减少随机读。
11)冷热索引区分对待-同样的机器容纳更多数据
solr/es:
默认是打开全部的索引,每个索引都会独占一些资源,如 内存、文件描述符等。但是一台机器的内存与文件描述符始终是有限的,从而也限制了solr与ES能够装载的数据规模,在机器资源有限的情况下,制约了数据规模。
YDB:
YDB将索引按照冷热索引区别对待,经常被使用的索引为热索引,那些不经常使用的索引为冷索引。
热索引是处于打开状态的,可以有较快的检索速度。
冷索引则是关闭状态的,仅仅占用hdfs的存储空间,并不会占用内存,文件资源描述,socket连接句柄等,理论上有多少存储空间,就可以存储多少冷数据。
12)稳定性
solr/es:
1.数据规模一旦过百亿,就会频繁的出现OOM,节点调片的情况。
2.一旦调片后无法自动恢复服务,需要运维人员去重启相关服务。
3.系统无过载保护,经常是一个人员做了一个复杂的查询,导致集群整体宕机,系统崩溃。
lucene在索引合并过程中,每进行一次commit都要进行一次全范围的ord关系的重新映射,数据规模小的时候整个索引文件的映射还没什么,但是当数据量达到亿级别,甚至百亿级别后,这种映射关系会占用超多的CPU、内存、硬盘资源,所以当数据量过亿后,solr与Es在数据比较大的情况下,实时索引几乎是不可能的,频繁的ord关系映射,会让整个系统不可用。
YDB:
YDB相对于solr/es底层做了大幅度的改动,更适合海量数据。
1.优化或修正LUCENE的BUG大幅度的缩减了OOM,频繁调片的风险。
2.服务自动迁移与恢复的特性,大幅减少运维人员驻场的工作量。
3.提供了导入与查询的限流控制,也提供了过载保护控制,甚至在极端场景提供了有损查询与有损服务。
2.YDB与Solr、ES定位不同
Solr\ES :偏重于为小规模的数据提供全文检索服务;YDB:则更倾向于为大规模的数据仓库提供索引支持,为大规模数据仓库提供即席分析的解决方案,并降低数据仓库的成本,YDB数据量更“大”。
1)Solr、ES的使用特点如下:
1)源自搜索引擎,侧重搜索与全文检索,统计功能非常弱。
2)数据规模从几百万到千万不等,数据量过亿的集群特别少。
Ps:有可能存在个别系统数据量过亿,但这并不是普遍现象(就像Oracle的表里的数据规模有可能超过Hive里一样,但需要小型机)。
2)YDB:的使用特点如下:
3)一个基于大索引技术的海量数据实时检索分析平台。侧重数据的即席分析,可做复杂的分析计算任务,自定义函数,统计功能强。。
4)数据规模从几亿到万亿不等。最小的表也是千万级别。
3.Solr、ES在大索引上存在的问题:
1)Solr\ES中的索引是一直处于打开状态的,不会主动去释放资源;
这种模式会制约一台机器的索引数量与索引规模,打开的索引通常会消耗比较多的资源(内存与文件句柄),通常一台机器固定负责某个业务的索引。
2)将列的全部值Load到放到内存里,处理数据量过亿会出现掉片,OOM。
排序和统计(sum,max,min)的时候,是通过遍历倒排表,将某一列的全部值都Load到内存里(在Lucence5以后做了改进,采用了docvalues,虽然不是load原始值本身,而是将字典ord映射到内存中,创建全局的ord关系)。然后基于内存数据进行统计,即使一次查询只会用到其中的一条记录,也会将整列的全部值都Load到内存里,太浪费资源,首次查询的性能太差。数据规模受物理内存限制很大,索引规模上千万后OOM是常事。
另外对于实时系统,新版Lucene在索引合并过程中,每进行一次commit都要进行一次全范围的ord关系的重新映射,数据规模小的时候整个索引文件的映射还没什么,但是当数据量达到亿级别,甚至百亿级别后,这种映射关系会占用超多的CPU、内存、硬盘资源,所以当数据量过亿后,solr与Es在数据比较大的情况下,实时索引几乎是不可能的,频繁的ord关系映射,会让整个系统不可用。
3)索引存储在本地硬盘,恢复难,数据迁移更难
一旦机器损坏,数据即使没有丢失,一个几T的索引,仅仅数据copy时间就需要好几个小时才能搞定,如果本地将近20T的存储盘损坏,需要从副本恢复后才能继续服务,恢复时间长达几天,而且这个过程中经常会出现连锁反应,因为要恢复索引,数据复制占用太多的资源,也导致了其他节点陆续调片,最终整体罢工现象是常态。
4)磁盘读写没有很好的控速机制,导入数据没有良好的流量控制机制,无法控制流量,而生产系统,磁盘控速与流量控速是必须的,不能因为业务高峰对系统造成较大的冲击,导致磁盘都hang住或挂掉。
5)本次硬盘局部坏点,造成局部数据损坏对于lucene来说无法识别,但是对于索引来说哪怕是仅仅一个byte数据的读异常,就会造成索引指针的错乱,导致检索结果数据丢失,甚至整个索引废掉。
6)集群规模太小
支持Master/Slave模式,但是跟传统Mysql数据库一样,集群规模并没有特别大的(百台以内)。这种模式处理集群规模受限外,每次扩容的数据迁移将是一件非常痛苦的事情,数据迁移时间太久。
7)数据倾斜问题
倒排检索即使某个词语存在数据倾斜,因数据量比较小,也可以将全部的doc list都读取过来(比如说男、女),这个doclist会占用较大的内存进行Cache,当然在数据规模较小的情况下占用内存不是特别多,查询命中率很高,会提升检索速度,但是数据规模上来后,这里的内存问题越来越严重。
8)节点和数据规模受限
一次查询的时候Merger Server只能是一个,用来合并其他shard的结果,这种单merger server的设计,实现上比较简单,但是也意味着,节点数过多后,这个merger server会成为瓶颈,制约了查询的节点数量
9)硬盘损坏,机器宕机后不能自动恢复服务
一旦调片后无法自动恢复服务,需要运维人员去重启相关服务,由于索引存储在机器本地,一点这台机器宕机,相关服务进程无法自动迁移,也需要人工处理,运维工作量较大。系统无过载保护,经常是一个人员做了一个复杂的查询,导致集群整体宕机,系统崩溃。
10)与大数据系统对接麻烦
数据导入导出太麻烦,甚至不可行,第三方有SQL引擎插件,但均是简单SQL。无法与常见的支持JDBC标准的报表系统集成,定制开发代价较大。
11)FQ Cache在数据规模庞大后太耗内存
使用Solr的同学到知道,solr有个autowarm的功能,本质上是将用户常见的搜索条件按照FQ参数进行Cache下来,Cache里面存储的openbitset的值,但是openbitset在数据量很小的时候非常节省内存,但是随着数据量变得越来越多openbitset由于占用的内存越来越多,将变得非常不可取。而且对于像性别是男女这种的数据,由于数据倾斜很严重,构建openbitset本身花费的时间也特别旧,因为要有大量的IO,从磁盘上读取doclist.
12)数据迁移麻烦
如若夸机房搬迁机器,需要运维人员细心的进行索引1对1复制,搬迁方案往往要数星期,且非常容易出错。 数据如若想导出到其他系统很难,超过百万级别的导出基本是不可行的,更别提复杂计算后的导出,没有成型的高可用的导出方案。
13)Lucene内部大量的使用了thread local,在Solr与ES这个含有线程池的系统下,会造成内存泄露(本书内存泄露的部分由详解)
Solr与ES小结
并不是说Solr与ES的这种方式不好,在数据规模较小的情况下,Solr的这种处理方式表现优越,并发性能较好,Cache利用率较高,事实证明在生产领域Solr和ES是非常稳定的,并且性能也很卓越。但是在数据规模较大,并且数据在频繁的实时导入的情况下,就需要进行一些优化。
4.YDB相对于Solr ,ES在索引上的改进:
1)索引按需加载
大部分的索引处于关闭状态,只有真正用到索引才会去打开;一级跳跃表采用按需Load,并不会Load整个跳跃表,用来节省内存和提高打开索引的速度。YDB经常会根据业务的不同动态的打开不同的索引,关闭那些不经常使用的索引,这样同样一台机器,可以被多种不同的业务所使用,机器利用率高。
2)排序和统计按需加载
排序和统计并不会使用数据的真实值,而是通过标签技术将大数据转换成占用内存很小的数据标签,占用内存是原先的几十分之一。
另外不会将这个列的全部值都Load到内存里,而是用到哪些数据Load哪些数据,依然是按需Load。不用了的数据会从内存里移除。
3)索引存储在HDFS中
理论上只要HDFS有空间,就可以不断的添加索引,索引规模不在严重受机器的物理内存和物理磁盘的限制。容灾和数据迁移容易得多。
4)HDFS有CRC的文件校验,在读取数据的时候,如果文件系统异常,读取到的数据有部分坏点的情况,能够立即发现,并重新从其他机器上的备份Block去读取。
5)有较好的控速逻辑,无论是HDFS的读,写,还是Kafka的消费,均可以非常好的控制速度,生产系统上系统稳定性有保障。
6)更精细化的索引管理,从表的级别、索引级别、segments级别、列的级别、列的值的基本均可以控制与调整
7)采用Yarn进行进程管理
数据在HDFS中,集群规模和扩容都是一件很容易的事情,一旦进程挂掉,或者机器挂掉,进程会有Yarn进行自动的迁移,恢复服务。系统宕机,硬件损坏,服务会自动迁移,数据不丢失。延云YDB只需要部署在一台机器上,由Yarn自动分发,不需要维护一堆机器的配置,修改参数很方便。
8)采用多条件组合跳跃降低数据倾斜
如果某个词语存在数据倾斜,则会与其他条件组合进行跳跃合并(参考doclist的skiplist资料)。
9)多级Merger与自定义分区
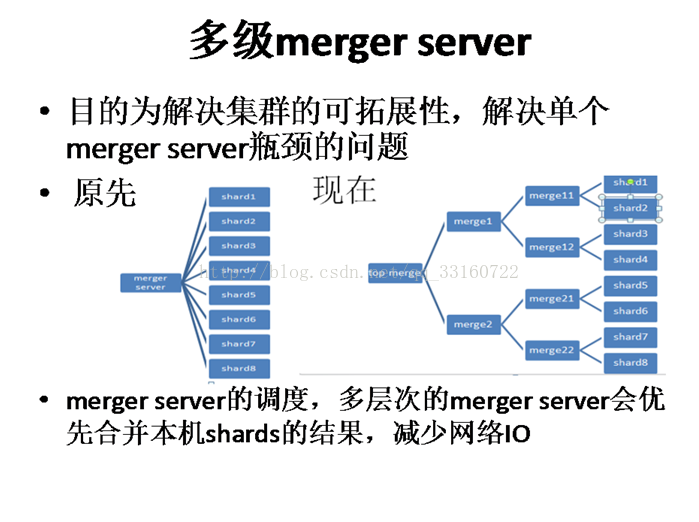
10)可以对接Hive表,与Kafka,方便的进行大规模的数据导入与导出
采用对接消息队列(如Kafka)的方式,数据导入Kafka后大约1~2分钟即可在YDB中查到。
通过Hive SQL可以方便的将YDB的数据导出成文本文件,或者与其他系统的数据交互。
11)与Spark深度集成
我们将索引集成到了Spark内部,这样结合Spark可以做很多复杂的计算,但又兼顾了倒排索引的高性能。用户可以写复杂的SQL,可以嵌套、可以join、可以distinct、可以自定义UDF\UDAF\UDTF函数来扩中SQL的功能。
因Hive已经成为大数据的事实标准,YDB采用Hive SQL的方式与周边系统的集成非常方便,数据导入导出灵活。
Hive本身支持JDBC方式,可以与常见的报表系统无缝集成。














 1639
1639











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









