






1、限流
1.1 什么是限流
限流(Rate Limiting)是一种常用的技术手段,用于控制系统对资源的访问速率,确保系统的稳定性和可靠性。在分布式系统、Web服务、API接口等场景中,限流尤为重要。通过限制请求的频率或数量,可以有效防止因突发流量导致系统过载、崩溃或资源耗尽等问题。限流不仅保护了服务提供者的利益,也提升了用户体验。
1.2 限流的常见场景
- API接口保护:防止恶意用户或爬虫程序对API进行高频访问,消耗大量服务器资源。
- 分布式系统:在微服务架构中,限制各服务间的调用频率,避免服务间的级联失败。
- 数据库访问:限制对数据库的查询或写入操作,防止数据库因压力过大而响应缓慢或崩溃。
- 网络带宽控制:在网络设备或服务器上实施带宽限制,确保关键业务的网络传输质量。
1.3 限流策略
- 基于IP的限流:对每个访问者的IP地址进行限流,防止单个IP的恶意访问。
- 基于用户的限流:对注册用户进行限流,根据用户身份或角色分配不同的请求额度。
- 基于接口的限流:对不同的API接口分别设置限流规则,根据接口的重要性和访问频率进行调整。
- 基于时间段的限流:在特定的时间段内对请求进行限流,如高峰期限制请求频率,低峰期放宽限制。
1.4 限流算法
-
固定窗口算法:将时间划分为固定的窗口,每个窗口内统计请求数量,超过阈值则拒绝服务。该算法实现简单,但可能存在临界问题,即窗口切换时突然允许大量请求通过。
-
滑动窗口算法:相对于固定窗口,滑动窗口算法允许窗口在时间轴上滑动,通过两个固定窗口(当前窗口和上一个窗口)的叠加来统计请求数量,解决了临界问题,但实现复杂度稍高。
-
漏桶算法(Leaky Bucket):将请求视为水滴,以固定速率从桶中漏出。如果水滴到达速率超过漏出速率,则桶满后多余的水滴将被丢弃。该算法平滑了请求的突发流量,但可能导致低优先级请求长时间等待。
-
令牌桶算法(Token Bucket):与漏桶算法类似,但令牌桶以固定速率向桶中添加令牌(代表服务容量)。当请求到达时,如果桶中有足够的令牌,则请求被处理并消耗一个令牌;否则,请求被限流。该算法既能应对突发流量,又能保证请求的公平性。
2、熔断
2.1 什么是熔断
熔断(Circuit Breaker)模式是一种用于处理分布式系统中因服务调用失败而可能导致系统雪崩效应的保护机制。它借用了电路中的“熔断器”概念,当电流过大时,熔断器会自动切断电路,以保护整个电路系统不被烧毁。在分布式系统中,熔断器用于监控服务调用的健康状况,并在检测到异常(如服务调用失败率过高、响应时间过长等)时,自动切断对该服务的调用,从而防止故障在系统中蔓延,保障系统的整体稳定性和可用性。
2.2 熔断的目的
- 防止系统雪崩:当某个服务出现故障时,如果没有有效的隔离措施,故障可能会迅速扩散到整个系统,导致系统雪崩。熔断机制能够在服务故障时及时切断调用链,防止故障扩散。
- 提升系统弹性:通过熔断机制,系统能够在面对服务故障时保持一定的弹性,即能够在故障恢复后快速恢复正常服务,减少因故障导致的服务中断时间。
- 优化用户体验:在熔断期间,系统可以返回预设的降级响应(如默认值、缓存数据或错误信息),减少用户等待时间和错误率,提升用户体验。
2.3 熔断的常见场景
-
服务调用超时:当下游服务的响应时间超过预设的阈值时,如果继续调用可能会导致上游服务资源耗尽,影响整体系统性能。此时,熔断机制可以切断对下游服务的调用,避免超时问题进一步恶化。
-
服务调用失败率过高:如果某个服务的调用失败率达到一定阈值,说明该服务可能存在问题,继续调用可能会浪费系统资源并影响用户体验。熔断机制可以在此时介入,切断对该服务的调用,并返回降级响应。
-
系统资源紧张:在高峰期或系统资源不足时,为了保障核心功能的稳定运行,可以通过熔断机制对部分非核心服务进行降级处理,释放系统资源给关键服务使用。
-
硬件故障或网络问题:当下游服务所在的服务器或网络出现故障时,可能导致服务不可用。熔断机制可以及时发现并切断对故障服务的调用,防止故障扩散。
-
缓存击穿或穿透:在缓存服务中,如果大量请求同时访问未命中缓存的数据(缓存击穿)或不存在的数据(缓存穿透),可能会直接对数据库造成压力。此时,可以通过熔断机制对这类请求进行限流或降级处理。
2.4 熔断策略
-
基于失败率的熔断策略:当服务调用的失败率达到预设的阈值时,触发熔断。这种策略适用于对服务稳定性要求较高的场景,可以确保在服务出现问题时及时切断调用链。
-
基于响应时间的熔断策略:当服务调用的响应时间超过预设的阈值时,触发熔断。这种策略适用于对服务响应时间有严格要求的场景,如在线交易系统、实时数据处理等。
-
基于异常比例的熔断策略:当单位统计时长内异常请求(如抛出异常、返回错误码等)的比例超过设定的阈值时,触发熔断。这种策略适用于服务出现不稳定情况、异常情况较多的场景。
-
基于异常数的熔断策略:当单位统计时长内异常请求的数量超过设定的阈值时,触发熔断。这种策略适用于对异常请求数量敏感的场景,如高并发的Web服务中突然出现大量异常请求的情况。
-
滑动窗口熔断策略:通过滑动窗口来记录一段时间内的请求情况,并根据窗口内的请求失败率或响应时间等指标来判断是否触发熔断。这种策略可以更加灵活地应对系统负载的变化。
-
半开状态策略:在熔断器处于开启状态一段时间后,进入半开状态,允许部分请求通过以测试服务是否已恢复正常。如果测试请求成功,则熔断器关闭;如果测试请求失败,则熔断器重新进入开启状态并延长休眠时间。这种策略有助于在保障系统稳定性的同时,尽快恢复对服务的调用。
2.5 熔断工作流程
- 闭合状态:熔断器处于正常工作状态,允许服务调用通过。此时,系统会监控服务调用的健康状况,如失败率、响应时间等。
- 开启状态:当服务调用满足熔断条件(如失败率达到阈值)时,熔断器进入开启状态,自动切断对该服务的调用。此时,所有对该服务的调用都将直接返回降级响应,不再实际执行。
- 半开启状态:熔断器在开启一段时间后(称为“休眠时间”),会进入半开启状态。在此状态下,系统会允许少量的服务调用通过,以测试服务是否已恢复正常。如果测试调用成功,熔断器将重新进入闭合状态;如果测试调用失败,熔断器将再次进入开启状态,并延长休眠时间。
3、降级
3.1 什么是降级
降级(Degrade)是分布式系统和高可用架构设计中的一个重要概念,旨在系统资源紧张或发生故障时,通过牺牲部分非核心业务功能或降低服务性能的方式,来保障系统整体的可用性和稳定性。降级是一种自我保护机制,它允许系统在面对压力时,主动减少负载,从而避免系统全面崩溃或资源耗尽。
3.2 降级的常见场景
-
服务依赖故障:当系统依赖的外部服务(如数据库、缓存、第三方API等)出现故障或响应缓慢时,可以通过降级策略来减少对这些服务的依赖,使用本地缓存、备用数据源或模拟数据等方式来保障核心功能的运行。
-
系统资源不足:在高峰期或系统资源紧张时,通过降级非核心功能来释放资源,确保核心功能的稳定运行。例如,在电商大促期间,可以降级非交易相关的功能(如商品评论、推荐系统等),以保障交易系统的流畅运行。
-
服务版本不兼容:在微服务架构中,不同服务之间可能存在版本不兼容的问题。当某个服务升级后,与其他服务存在兼容性问题时,可以通过降级策略来回退到旧版本,以保障系统的整体稳定性。
-
安全或合规性要求:在某些情况下,为了满足安全或合规性要求,可能需要降级部分功能或数据。例如,在发现数据泄露风险时,可以降级涉及敏感数据的服务,以防止数据进一步泄露。
-
功能优先级调整:在业务需求发生变化时,可能需要重新评估各功能的优先级。通过降级非优先功能,可以确保有限的资源被用于支持最重要的业务场景。
-
性能测试和故障演练:在进行性能测试或故障演练时,为了模拟真实环境下的系统压力,可以主动对部分服务进行降级处理,以观察系统的表现和恢复能力。
3.3 降级策略
- 开关降级:通过配置开关来启用或禁用某些功能或服务,实现快速降级。
- 限流降级:当系统流量超过预设阈值时,对部分请求进行限流或拒绝服务,以减少系统负载。
- 熔断降级:当服务调用失败率达到一定阈值时,自动触发熔断机制,将后续请求直接返回降级响应,避免对下游服务造成更大压力。
- 资源隔离降级:通过隔离不同服务的资源(如线程池、数据库连接等),防止单个服务的故障影响整个系统。当某个服务资源耗尽时,对其进行降级处理,以保障其他服务的正常运行。
- 超时降级:当服务调用超过预设的超时时间时,自动返回降级响应,防止长时间等待导致的资源浪费和用户体验下降。
3.4 降级和熔断的区别
降级和熔断都是系统保护机制,但侧重点不同。熔断侧重于在故障发生时快速切断服务调用链,防止故障扩散;而降级则是在系统资源紧张或故障发生时,通过牺牲部分非核心功能来保障系统整体可用性和稳定性。两者往往结合使用,形成更完善的系统保护体系。
4、 Sentinel 实现方案
Sentinel 提供了 @SentinelResource 注解用于定义资源,并提供了 AspectJ 的扩展用于自动定义资源、处理 BlockException 等。使用 Sentinel Annotation AspectJ Extension 的时候需要引入以下依赖:
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-core</artifactId>
<version>1.8.8</version>
</dependency>
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-annotation-aspectj</artifactId>
<version>1.8.8</version>
</dependency>4.1 官方示例
public class TestService {
// 对应的 `handleException` 函数需要位于 `ExceptionUtil` 类中,并且必须为 static 函数.
@SentinelResource(value = "test", blockHandler = "handleException", blockHandlerClass = {ExceptionUtil.class})
public void test() {
System.out.println("Test");
}
// 原函数
@SentinelResource(value = "hello", blockHandler = "exceptionHandler", fallback = "helloFallback")
public String hello(long s) {
return String.format("Hello at %d", s);
}
// Fallback 函数,函数签名与原函数一致或加一个 Throwable 类型的参数.
public String helloFallback(long s) {
return String.format("Halooooo %d", s);
}
// Block 异常处理函数,参数最后多一个 BlockException,其余与原函数一致.
public String exceptionHandler(long s, BlockException ex) {
// Do some log here.
ex.printStackTrace();
return "Oops, error occurred at " + s;
}
}需要通过配置的方式将 SentinelResourceAspect 注册为一个 Spring Bean:
@Configuration
public class SentinelAspectConfiguration {
@Bean
public SentinelResourceAspect sentinelResourceAspect() {
return new SentinelResourceAspect();
}
}官方文档:https://sentinelguard.io/zh-cn/docs/introduction.html
官方案例:Sentinel/sentinel-demo at master · alibaba/Sentinel · GitHub
4.2 流量控制(自测)
一条限流规则主要由下面几个因素组成,我们可以组合这些元素来实现不同的限流效果:
resource:资源名,即限流规则的作用对象count: 限流阈值grade: 限流阈值类型,QPS 或线程数strategy: 根据调用关系选择策略
基于QPS/并发数的流量控制
FlowRule.grade 字段控制了统计QPS还是统计并发数。
1、定义流量限制规则
@Component
public class SentinelRuleInitializer {
@PostConstruct
private static void initFlowQpsRule() {
List<FlowRule> rules = new ArrayList<FlowRule>();
FlowRule rule1 = new FlowRule();
//定义资源名称
rule1.setResource("flowControl");
//限流阈值
rule1.setCount(1);
//限流阈值类型 0-并发数 1-QPS
rule1.setGrade(RuleConstant.FLOW_GRADE_QPS);
//超出阈值后处理手段 0-直接拒绝 1-冷启动 2-匀速器 3-
rule1.setControlBehavior(RuleConstant.CONTROL_BEHAVIOR_DEFAULT);
//应用来源限制
rule1.setLimitApp(RuleConstant.LIMIT_APP_DEFAULT);
rules.add(rule1);
FlowRuleManager.loadRules(rules);
}
}2、注入bean
@Configuration
public class SentinelAspectConfiguration {
@Bean
public SentinelResourceAspect sentinelResourceAspect() {
return new SentinelResourceAspect();
}
}3、实现接口
注意!!!一开始没注意到踩了坑~
// Fallback 函数,函数签名与原函数一致或加一个 Throwable 类型的参数.
// Block 异常处理函数,参数最后多一个 BlockException,其余与原函数一致.
@Slf4j
@RestController
@RequestMapping("/sentinel")
public class SentinelController {
private Integer count = 0;
@SneakyThrows
@GetMapping("/flow/control")
@SentinelResource(value = "flowControl", blockHandler = "handleBlock", fallback = "exceptHandler")
public String flowControl() {
return "hello flow control!" + count++;
}
// 发生异常时 进入该方法
public String exceptHandler(BlockException ex) {
log.info("发生异常{}", count);
return "发生异常";
}
// sentinel发生异常时 BlockException 进入该方法
public String handleBlock(BlockException ex) {
log.info("发生限流、降级和熔断{}", count);
return "发生降级、降级和熔断" + ex;
}
}4、测试
限流规则是 QPS为1,即1秒最多请求1次,请求正常结果如下:

当快速点击后,请求结果如下:

4.2 熔断降级(自测)
1. 自定义熔断规则
@PostConstruct
private static void initDegradeRule() {
List<DegradeRule> rules = new ArrayList<>();
DegradeRule rule = new DegradeRule("flowControl")
//熔断策略,支持 0-慢调用比例/ 1-异常比例/ 2-异常数策略
.setGrade(CircuitBreakerStrategy.SLOW_REQUEST_RATIO.getType())
//慢调用比例模式下为慢调用临界 响应时间(超出该值计为慢调用);异常比例/异常数模式下为对应的阈值
.setCount(5)
// 熔断时长,单位为 s
.setTimeWindow(10)
//慢调用比例阈值,仅慢调用比例模式有效(1.8.0 引入)
.setSlowRatioThreshold(0.6)
// 熔断触发的最小请求数,请求数小于该值时即使异常比率超出阈值也不会熔断(1.7.0 引入)
.setMinRequestAmount(1)
//统计时长(单位为 ms),如 60*1000 代表分钟级(1.8.0 引入)
.setStatIntervalMs(20000);
rules.add(rule);
DegradeRuleManager.loadRules(rules);
}2. controller 增加10s时间
@SneakyThrows
@GetMapping("/flow/control")
@SentinelResource(value = "flowControl", blockHandler = "handleBlock", fallback = "exceptHandler")
public String flowControl() {
Thread.sleep(10);
return "hello flow control!" + count++;
}3. 访问页面,由于每次请求都超出5s,所以5s后第二次请求一定是发生熔断,熔断时间10s,即第一次请求15s后才能再次请求(前5秒是可以发起请求的)
注意:上述是有问题的,应该是发生熔断(可能是在第5s,也可能在第7s)到10s结束不接收请求,但是在第10s结束后就恢复了,而不是第15s
可以看到报错的类已经从FlowException 变成 DegradeException

4.3 Sentinel 控制台
官方 jar包下载:https://github.com/alibaba/Sentinel/releases
下载后使用如下命令启动,注意更改最后的文件名sentinel-dashboard.jar
java -Dserver.port=8080 -Dcsp.sentinel.dashboard.server=localhost:8080 -Dproject.name=sentinel-dashboard -jar sentinel-dashboard.jar应用绑定sentinel dashboard
spring.cloud.sentinel.transport.dashboard = localhost:8081打开本地页面(我这里更改端口为8081,默认8080):http://localhost:8081/#/login
默认用户名和密码都是 sentinel
 进入后即可配置限流、熔断规则等。
进入后即可配置限流、熔断规则等。
4.5 源码解析
4.5.1 入口
AbstractSentinelInterceptor和SentinelResourceAspect都是在Spring框架中与Sentinel集成时使用的组件,通过使用两者可实现接口或方法的限流、熔断和降级等功能。但它们在职责和使用场景上有所不同:
- AbstractSentinelInterceptor:它是一个抽象拦截器类,主要用于Spring AOP(面向切面编程)或者类似拦截器的场景,如Spring MVC、Spring Cloud Gateway等。拦截器在方法调用前/后执行,它可以控制请求的进入、资源的保护以及异常处理等
- SentinelResourceAspect:这是一个Spring的切面(Aspect),基于AOP注解驱动。它主要用于扫描并处理标记了`@SentinelResource`注解的方法。当方法被调用时,SentinelResourceAspect会自动应用Sentinel的流量控制、熔断和降级策略。只需要在方法上添加注解,无需手动编写拦截器。
总结一下,两者的区别在于:
- 使用方式:AbstractSentinelInterceptor需要手动配置并实现拦截逻辑,而SentinelResourceAspect是基于注解的自动处理。
- 处理方式:AbstractSentinelInterceptor通常在方法调用的开始和结束,而SentinelResourceAspect是在方法执行的点上。
- 适用场景:AbstractSentinelInterceptor更适合自定义复杂的拦截逻辑,SentinelResourceAspect则更适用于简单、直接的资源保护。
两者都调用了一个SphU.entry()方法,该方法会创建一个Entry,实现sentinel功能。
4.5.2 SphU.entry()
SphU.entry()会使用静态类调用Env.sph.entryWithType方法,它用于尝试进入一个资源并执行相应的流量控制策略。这个方法的参数含义如下:
- name:这是资源的名称,通常对应你的API路径、服务方法名或者业务逻辑的标识。它是 Sentinel 资源的核心标识。
- resourceType:资源类型,用于标识资源的类型。Sentinel 提供了一些内置的资源类型。你可以根据实际情况选择或自定义资源类型。【拦截器一定是COMMON_WEB=1,切面从接口中获取,默认是COMMON=0,变量在ResourceTypeConstants类中定义】
- trafficType:流量类型,表示资源的流量来源,如`IN`(入站流量Inbound traffic,通常为服务提供者)或`OUT`(出站流量Outbound traffic,通常为服务消费者)。【拦截器一定是IN,切面从接口中获取默认是OUT】
- count:资源的请求数量,一般为1,表示每次只有一个请求尝试进入。【都固定为1了】
- OBJECTS0:可选参数,用于传递业务上下文。例如,如果是HTTP请求,你可以传递HttpServletRequest对象,如果是RPC调用,可以传递`RpcContext`或业务参数。这个参数可以是空的,具体取决于你的业务需求。【拦截器传了空,切面传了方法参数列表】
进入资源有多种形式,Env.sph.entryWithType(类型) 和 Env.sph.entryWithPriority(优先级),但它们的区别在于流量控制的优先级处理:
- Env.sph.entryWithType:这个方法是标准的资源入口方法,它只基于资源名称、资源类型和流量类型来执行流量控制策略。它通常用于简单的流量控制场景,按照资源定义的规则进行限流,没有优先级概念。
- Env.sph.entryWithPriority:这个方法则引入了优先级的概念,允许在处理资源时考虑优先级。当系统资源紧张时,具有更高优先级的资源会优先通过流量控制,较低优先级的资源可能会被限制。这个方法通常用于更复杂的场景,例如在多个资源竞争有限资源时,确保关键资源的优先处理。
总结来说,entryWithType适用于常规的流量控制,而entryWithPriority适用于需要区分资源优先级的场景,它可以根据优先级顺序决定资源的进入顺序。在实际使用中,你需要根据业务需求来决定是否需要引入优先级控制。
4.5.3 ProcessorSlotChain
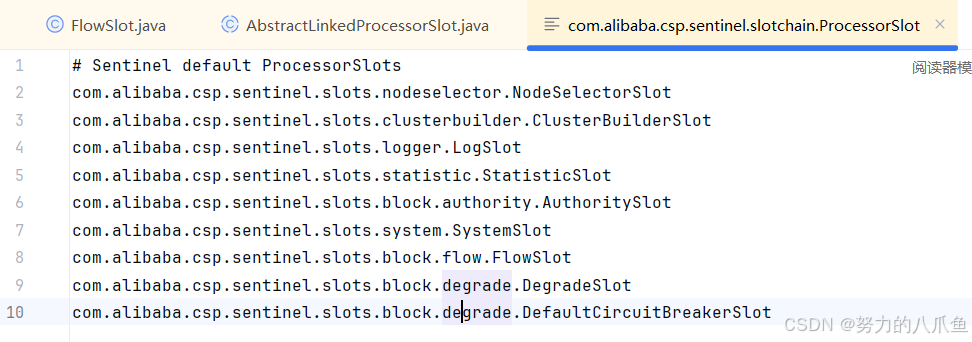
在Sentinel的源码中,DefaultSlotChainBuilder 类主要用于构建 ProcessorSlotChain,chain是个链,存的链的第一个元素。这个方法是`ProcessorSlotChainBuilder`的`build`方法,它的主要任务是根据服务提供者的SPI(Service Provider Interface)机制加载并排序所有的`ProcessorSlot`实现,然后将它们添加到`ProcessorSlotChain`中。这个过程初始化了以下功能:
- 加载插槽实现:SpiLoader.of(ProcessorSlot.class).loadInstanceListSorted();`这行代码使用了Java的SPI机制,从META-INF/services/com.alibaba.csp.sentinel.slotchain.ProcessorSlot文件中加载所有已注册的ProcessorSlot实现。这些实现是插槽的扩展点,用于实现特定的功能,如日志记录、统计、限流策略处理等。
- 排序插槽:加载的ProcessorSlot列表会按照它们在META-INF/services文件中的顺序进行排序。这意味着插槽的执行顺序是预定义的,可以保证特定的插槽先于其他插槽执行。
- 检查和添加插槽:对于每个加载的插槽,方法会检查它是否是AbstractLinkedProcessorSlot的实例。AbstractLinkedProcessorSlot是一个抽象基类,大多数插槽会继承它,以实现链式执行。如果不是,日志会发出警告,并跳过这个插槽(因为无法添加到链中)。
- 构建ProcessorSlotChain:使用DefaultProcessorSlotChain实例,将所有符合条件的AbstractLinkedProcessorSlot(如下图)添加到链中,按照它们的顺序()。addLast方法将插槽添加到链的末尾,保证了按照加载的顺序执行。
因此,这个方法初始化了所有通过SPI注册的`ProcessorSlot`实现,并构建了一个按照加载顺序执行的ProcessorSlotChain。在Sentinel执行资源控制时,这个链会被按照顺序逐个执行,处理资源的进入和退出。
4.5.4 FlowSlot
FlowSlot类(以限流为例)调用了FlowRuleChecker::checkFlow方法实现限流功能,该方法主要实现了根据资源名查找限流规则和判断请求是否能通过两个功能。
FlowRuleChecker::selectNodeByRequesterAndStrategy方法在Apache Sentinel中通常用于根据请求者(Requester)和流量控制策略(Strategy)选择合适的流量控制节点。这个方法的主要作用是动态地确定流量控制应该作用于哪个节点,以便实施正确的流量控制策略。
在Sentinel中,流量控制有多种策略,包括DefaultController、ThrottlingController、WarmUpController和WarmUpRateLimiterController。这些控制器对应不同的流量控制逻辑:
- DefaultController:这是Sentinel流量控制的默认实现,通常基于令牌桶算法(Token Bucket)进行限流。当令牌桶中的令牌用完时,新的请求会被限流。它主要关注的是平均速率控制,可以配置最大QPS(每秒请求数)等参数。
- ThrottlingController:这种控制器可能是指基于滑动窗口的限流策略,例如固定窗口、滑动窗口或漏桶窗口等。这些策略更注重在时间窗口内控制请求的峰值,以防止短时间内的流量激增对系统造成冲击。
- WarmUpController:温暖启动(Warm-up)控制器是为了解决服务启动时突然涌入大量请求可能导致性能波动的问题。它允许服务在启动初期以较低的流量接受请求,然后逐渐增加到设定的最大值,类似于预热过程。这有助于系统平稳启动,避免资源的瞬间大量消耗。
- WarmUpRateLimiterController:这是WarmUpController的一个变种,可能更专注于使用速率限制来实现温暖启动。它会在服务启动或规则切换时,以预设的速率逐渐增加允许的请求数,直到达到设定的限流阈值。这样可以平滑地引入流量,减少对系统的影响。
5、学习实践
5.1 限流-令牌桶
注意:令牌桶算法不能与另外一种常见算法“漏桶算法(Leaky Bucket)”相混淆。这两种算法的主要区别在于“漏桶算法”能够强行限制数据的传输速率,而“令牌桶算法”在能够限制数据的平均传输速率外,还允许某种程度的突发传输。在“令牌桶算法”中,只要令牌桶中存在令牌,那么就允许突发地传输数据直到达到用户配置的门限,因此它适合于具有突发特性的流量。
令牌桶工作分为三步:
- 产生令牌:周期性的以速率CIR/EIR向令牌桶中增加令牌,桶中的令牌不断增多。如果桶中令牌数已到达CBS/EBS,则丢弃多余令牌。
- 消耗令牌:输入数据包会消耗桶中的令牌。在网络传输中,数据包的大小通常不一致。大的数据包相较于小的数据包消耗的令牌要多。
- 判断是否通过:输入数据包经过令牌桶后的结果包括输出的数据包和丢弃的数据包。当桶中的令牌数量可以满足数据包对令牌的需求,则将数据包输出,否则将其丢弃。
以下模仿在微服务中,1台客户端实例不断请求,1台服务端实例使用令牌桶进行限流的场景。(由于一开始想做集群限流,3台实例,所以用redis存储令牌,后续嫌麻烦做了单实例)
1. 工具类负责两件事。一是在程序启动时初始化令牌数量,二是每隔30s向令牌桶中生成两个令牌,直到令牌桶已满。(开始做的集群限流,使用了抢占的方式,哪台实例能第一个抢到token,后续就由这一台实例生成令牌,其他实例不生成,这里没做好。如果不用集群限流,可以直接使用AtomicInteger)
public class TokenBucketUtil {
public static final String TOKEN = "token";
//令牌桶最大数量
private Integer maxToken = 10;
//每次放入数量
private Integer perToken = 2;
@Resource
RedisUtil redisUtil;
@PostConstruct
@SneakyThrows
public void init() {
//程序启动时,初始化令牌数量为最大值
redisUtil.put(TOKEN, String.valueOf(maxToken));
}
@Scheduled(fixedRate = 30000)
public void putToken() {
//如果令牌桶未满,且空余数量大于等于perToken = 2 ,则每30秒放入两个令牌
String LUA_SCRIPT =
"local currentValue = redis.call('GET', KEYS[1]); " +
"if tonumber(currentValue) <= " + (maxToken - perToken) + " then " +
" redis.call('SET', KEYS[1], tonumber(currentValue) + " + perToken + "); " +
"else " +
" redis.call('SET', KEYS[1], " + maxToken + "); " +
"end " +
"return redis.call('GET', KEYS[1]); ";
Long l = redisUtil.exeLua(LUA_SCRIPT, TOKEN);
log.info("定时塞入令牌,当前令牌个数:{}", l);
}2. 接口执行前,要获取令牌并消耗一个令牌(这里注意读写一致性)。获取到令牌后才可以执行,否则进入降级方案/拒绝处理。
@Slf4j
@RestController
@RequestMapping("/token/bucket")
public class TokenBucketController {
@Resource
RedisUtil redisUtil;
@SneakyThrows
@GetMapping("/flow/control")
public String flowControl() {
//先获取令牌 如果令牌数量大于1 ,才可以被执行,同时减少令牌数量
//redis单个操作是原子的,但是多个操作不是,所以要确保一致性
//使用lua脚本执行
String LUA_SCRIPT =
"local currentValue = redis.call('GET', KEYS[1]); " +
"if tonumber(currentValue) > 1 then " +
" redis.call('SET', KEYS[1], tonumber(currentValue) - 1); " +
" return redis.call('GET', KEYS[1]); " + // 返回1表示操作成功
"else " +
" return 0; " + // 返回0表示不处理
"end";
String result;
Long canToken = redisUtil.exeLua(LUA_SCRIPT, "token");
if (canToken != 0) {
result = "抢到令牌,可以执行,剩余令牌个数" + canToken;
} else {
result = "未抢到令牌,降级方案,剩余令牌个数" + canToken;
}
return result;
}
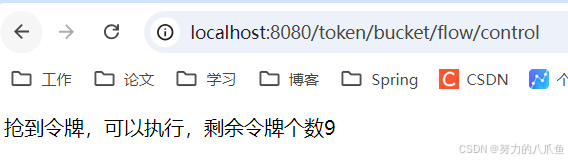
}3. 结果如图,可以不断访问该接口,直到令牌被耗尽

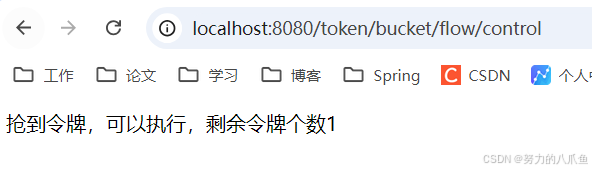
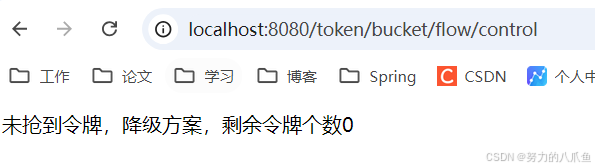
当再次产生令牌时,可以继续处理请求

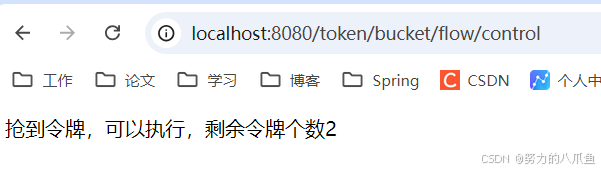
当令牌桶已达到最大值时不会再产生多余的令牌

4. 优化了一下,使用注解的方式实现上述限流方法,是需要在需要被限流的接口上使用注解即可。(这里还有一个改进项:目前是所有接口共用同一个令牌桶,可以优化一下,根据接口地址配置不同的桶)
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface RequireToken {
// 可以添加其他属性,如最小令牌数等
}@Aspect
@Component
@Slf4j
public class TokenAspect {
// Lua脚本(与之前的相同)
private static final String LUA_SCRIPT =
"local currentValue = redis.call('GET', KEYS[1]); " +
"if tonumber(currentValue) > 1 then " +
" redis.call('SET', KEYS[1], tonumber(currentValue) - 1); " +
" return redis.call('GET', KEYS[1]); " +
"else " +
" return 0; " +
"end";
@Autowired
private RedisUtil redisUtil;
@Around("@annotation(requireToken)")
public Object checkToken(ProceedingJoinPoint joinPoint, RequireToken requireToken) throws Throwable {
String result;
Long canToken = redisUtil.exeLua(LUA_SCRIPT, "token");
log.info("剩余令牌个数{}", canToken);
if (canToken != 0) {
// 继续执行原方法
return joinPoint.proceed();
} else {
result = "未抢到令牌,降级方案";
// 可以在这里执行降级逻辑,或者直接返回结果
return result;
}
}
}@Slf4j
@RestController
@RequestMapping("/token/bucket")
public class TokenBucket2Controller {
@Resource
RedisUtil redisUtil;
@SneakyThrows
@GetMapping("/flow/control-2")
@RequireToken
public String flowControl() {
return "抢到令牌,可以执行";
}
}5.2 限流-漏桶
1. 定义注解
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface RequireLeaky {
// 可以根据需要添加属性
}2. 切面实现,将方法放入队列中,这里不可以使用Runnable ,会丢失返回值(还没有想到更好的办法)
@Aspect
@Component
@Slf4j
public class LeakyAspect {
@Resource
LeakyBucketQueueService leakyBucketQueueService;
@Around("@annotation(requireLeaky)")
public void beforeAsyncQueuedMethod(ProceedingJoinPoint joinPoint, RequireLeaky requireLeaky) {
// 将方法包装成Runnable放入队列
Runnable task = () -> {
try {
joinPoint.proceed();
} catch (Throwable e) {
log.info(e.getMessage());
}
};
boolean offer = leakyBucketQueueService.getQueue().offer(task);
if(offer){
log.info("offer Queue");
}else{
log.info("Queue is full");
}
}
}3. 每秒执行一次队列中的任务
@Component
public class LeakyBucketQueueService {
//线程安全的队列
private final BlockingQueue<Runnable> queue = new LinkedBlockingQueue<>(10);
public BlockingQueue<Runnable> getQueue() {
return queue;
}
@Scheduled(fixedRate = 1000)
public void execute(){
//每秒执行一次 = 每秒滴1滴水
Runnable poll = queue.poll();
if(poll != null){
poll.run();
}
}
}4. 定义controller
@Slf4j
@RestController
@RequestMapping("/leaky/bucket")
public class LeakyBucketController {
private Integer count = 0;
@RequireLeaky
@SneakyThrows
@GetMapping("/flow/control")
public String control() {
log.info("执行成功{}", count);
return "执行成功" + count++;
}
}5. 结果
不断请求接口,看以看到输出结果:先将所有请求插入到队列中,然后缓慢执行,当执行到第二个请求时,队列已经插满了(size=10)。后续每秒执行一个任务。
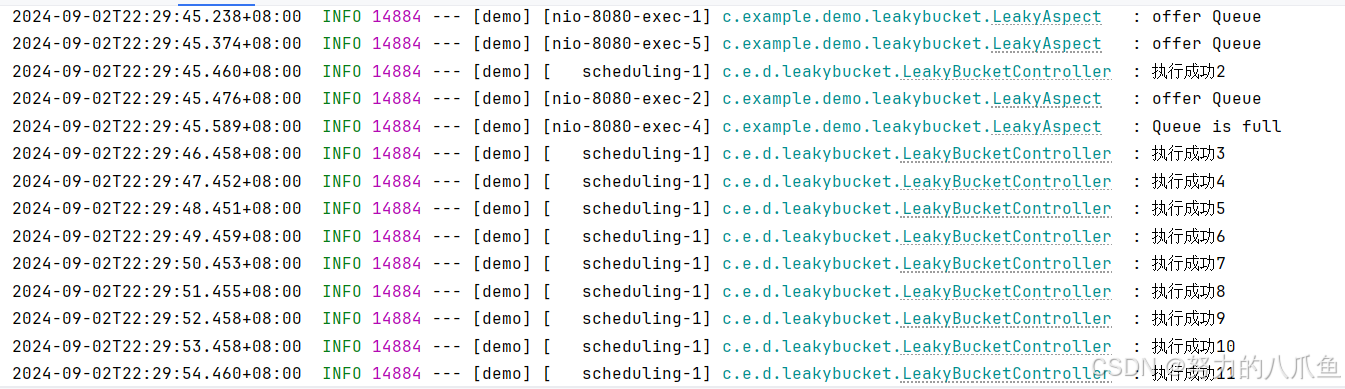
😂思考了一下,用队列是没问题的,但是位置不对,可以用MQ对消息进行拦截。
5.3 限流-滑动窗口
滑动窗口和漏桶的区别在于,漏桶不管请求的速率的,都会以恒定的速率处理请求,所以更注重请求量(能处理大量请求)。而滑动窗口则是处理完一个请求就会滑动处理下一个请求,更注重请求频率。
使用了和漏桶同样的方式,不过增加了一个线程安全的int作为窗口容量的限制,当count=0时休眠1s,当count=1时向后滑动执行1个。执行完毕后窗口count+1。
@Aspect
@Component
@Slf4j
public class SlidingWindowAspect {
@Resource
SlidingWindowQueueService slidingWindowQueueService;
@Around("@annotation(requireLeaky)")
public void beforeAsyncQueuedMethod(ProceedingJoinPoint joinPoint, RequireLeaky requireLeaky) {
// 将方法包装成Runnable放入队列
Runnable task = () -> {
try {
joinPoint.proceed();
slidingWindowQueueService.setCount(new AtomicInteger(slidingWindowQueueService.getCount().incrementAndGet()));
} catch (Throwable e) {
log.info(e.getMessage());
}
};
boolean offer = slidingWindowQueueService.getQueue().offer(task);
if (offer) {
log.info("offer Queue");
} else {
log.info("Queue is full");
}
}
}@Component
@Data
public class SlidingWindowQueueService {
//线程安全的队列
private final BlockingQueue<Runnable> queue = new LinkedBlockingQueue<>(10);
//每次窗口大小
private AtomicInteger count = new AtomicInteger(1);
@PostConstruct
@SneakyThrows
public void execute(){
while(true){
if(count.incrementAndGet() == 0){
Thread.sleep(1000);
}else{
Runnable poll = queue.poll();
if(poll != null){
poll.run();
count.decrementAndGet();
}
}
}
}
}

















 3312
3312

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









