







目录
1、概述
Neo4j是一个高性能的,NOSQL图形数据库,它将结构化数据存储在网络上而不是表中。它是一个嵌入式的、基于磁盘的、具备完全的事务特性的Java持久化引擎,但是它将结构化数据存储在网络(从数学角度叫做图)上而不是表中。Neo4j也可以被看作是一个高性能的图引擎,该引擎具有成熟数据库的所有特性。程序员工作在一个面向对象的、灵活的网络结构下而不是严格、静态的表中——但是他们可以享受到具备完全的事务特性、企业级的数据库的所有好处。
1.1 特点
-
SQL就像简单的查询语言Neo4j CQL。
-
它遵循属性图数据模型。
-
它通过使用Apache Lucence支持索引。
-
它支持UNIQUE约束。
-
它包含一个用于执行CQL命令的UI:Neo4j数据浏览器。
-
它支持完整的ACID(原子性,一致性,隔离性和持久性)规则。
-
它采用原生图形库与本地GPE(图形处理引擎)。
-
它支持查询的数据导出到JSON和XLS格式。
-
它提供了REST API,可以被任何编程语言(如Java,Spring,Scala等)访问。
-
它提供了可以通过任何UI MVC框架(如Node JS)访问的Java脚本。
-
它支持两种Java API:Cypher API和Native Java API来开发Java应用程序。
1.2 优点
-
数据底层存储专门针对图数据的特点进行优化,在关系数据的处理上具备远高于其他数据库的性能。
-
检索/遍历/导航更多的连接数据是非常容易和快速的。
-
专门为关系数据设计的查询语言,对于关系数据的操作更加的方便。
-
Neo4j CQL查询语言命令是人性化的可读格式,非常容易学习。
-
自动为数据建立合适的索引(根据数据的标签),免去管理索引的麻烦。
-
支持高可用性主从集群部署。
-
它不需要复杂的连接来检索连接的/相关的数据,因为它很容易检索它的相邻节点或关系细节没有连接或索引。
-
具备图形化平台等配套工具,帮助开发者快速构建出完整的关系数据平台。
1.3 缺点
-
Neo4j来处理结点本身的属性就没有什么优势。
-
单机版,分布式不好做。
1.4 Neo4j的使用场景
-
社交网络:根据用户与其他用户的关系为用户推荐新的朋友。例如,在QQ中给你推荐朋友的朋友 。
-
智能推荐引擎:通过分析用户有哪些朋友、用户朋友喜好的产品、用户的浏览记录等关系信息为用户推荐商品。
-
知识图谱:根据知识点之间的关系建立知识图,帮助用户搜索到关联的知识。
-
网络、数据中心管理:网络、数据中心这些基础设施自身就是一个包含复杂关系的网络,利用Neo4j可以方便的建立设备之间的关系,以便于对整个系统的管理。
2、为什么需要图数据库
随着技术的发展,我们对数据的需求已经不再局限于对数据本身的获取了,我们还需要获取数据与数据间的关系(也就是连接数据)。简单地说,我们可以说图数据库主要用于存储更多的连接数据(因为图结构相比其他数据结构而言,能保存更多的数据间的关系)。
如果我们使用 RDBMS 数据库来存储更多连接的数据,那么它们不能提供用于遍历大量数据的适当性能。 在这些情况下,Graph Database 提高了应用程序性能。
我们将观察什么是连接数据? 以及这些应用程序如何与某些实时应用程序存储数据。
2.1 Google+
使用 Google+(GooglePlus)应用程序来了解现实世界中 Graph 数据库的需求。 观察下面的图表。在这里,我们用圆圈表示了 Google+应用个人资料。
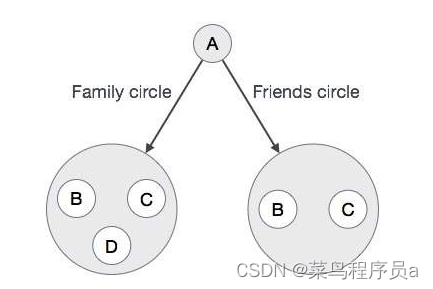
在上图中,轮廓“A”具有圆圈以连接到其他轮廓:家庭圈(B,C,D)和朋友圈(B,C)。
再次,如果我们打开配置文件“B”,我们可以观察以下连接的数据。
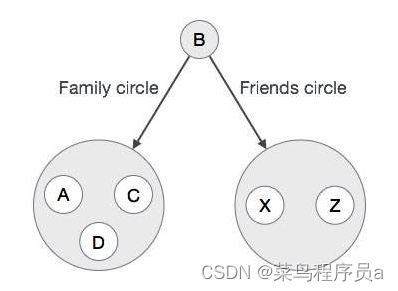
像这样,这些应用程序包含大量的结构化,半结构化和非结构化的连接数据。 在 RDBMS 数据库中表示这种非结构化连接数据并不容易。如果我们在 RDBMS 数据库中存储这种更多连接的数据,那么检索或遍历是非常困难和缓慢的。所以要表示或存储这种更连接的数据,我们应该选择一个流行的图数据库。
图形DBMS非常容易地存储这种更多连接的数据。 它将每个配置文件数据作为节点存储在内部,它与相邻节点连接的节点,它们通过关系相互连接。他们存储这种连接的数据与上面的图表中的相同,这样检索或遍历是非常容易和更快的。
2.2 Facebook
利用 Facebook 应用程序了解现实世界中 Graph 数据库的需求。
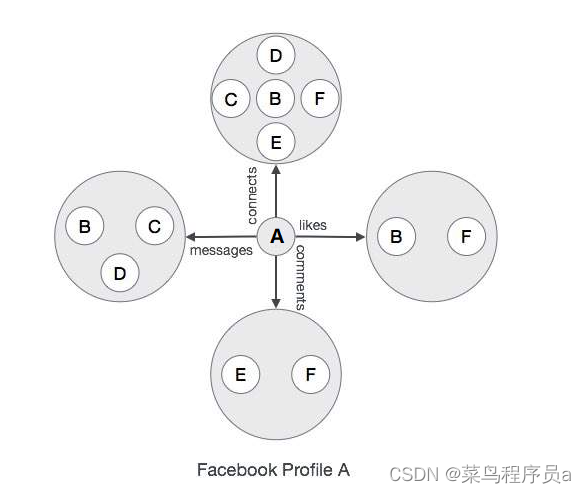
在上面的图中,Facebook Profile“A”已经连接到他的朋友,喜欢他的一些朋友,发送消息给他的一些朋友,跟随他喜欢的一些名人。 这意味着大量的连接数据配置文件A.如果我们打开其他配置文件,如配置文件B,我们将看到类似的大量的连接数据。
注:通过观察上述两个应用程序,他们有更多的连接数据。使用图形数据库存储和检索这种更连接的数据是非常容易的。
3、数据模型
Neo4j图数据库遵循属性图模型来存储和管理其数据。
属性图模型规则
-
表示节点,关系和属性中的数据
-
节点和关系都包含属性
-
关系连接节点
-
属性是键值对
-
节点用圆圈表示,关系用方向键表示。
-
关系具有方向:单向和双向。
-
每个关系包含“开始节点”或“从节点”和“到节点”或“结束节点”
在属性图数据模型中,关系应该是定向的。如果我们尝试创建没有方向的关系,那么它将抛出一个错误消息。在Neo4j中,关系也应该是有方向性的。如果我们尝试创建没有方向的关系,那么Neo4j会抛出一个错误消息,“关系应该是方向性的”。Neo4j图数据库将其所有数据存储在节点和关系中。我们不需要任何额外的RDBMS数据库或无SQL数据库来存储Neo4j数据库数据。它以图形的形式存储其数据的本机格式。Neo4j使用本机GPE(图形处理引擎)引擎来使用它的本机图存储格式。
图形数据库数据模型的主要构建块是:
-
节点
-
关系
-
属性
简单的属性图的例子
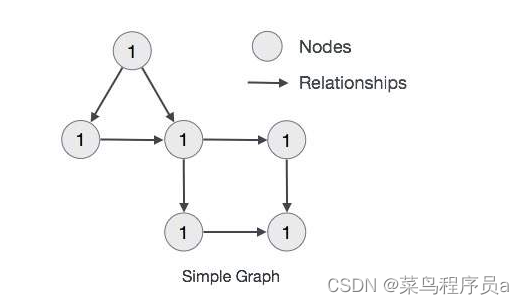
这里我们使用圆圈表示节点。 使用箭头的关系。 关系是有方向性的。 我们可以用Properties(键值对)来表示Node的数据。 在这个例子中,我们在Node的Circle中表示了每个Node的Id属性。
4、图形理论基础
图是一组节点和连接这些节点的关系。图形数据存储在节点和关系在属性的形式。属性是键值对表示数据。图形以属性的形式将数据存储在节点和关系中,属性是用于表示数据的键值对。在图形理论中,我们可以表示一个带有圆的节点,节点之间的关系用一个箭头标记表示。
最简单的可能图是单个节点:
我们可以使用节点表示社交网络(如Google+(GooglePlus)个人资料)。 它不包含任何属性。
向 Google+个人资料添加一些属性:
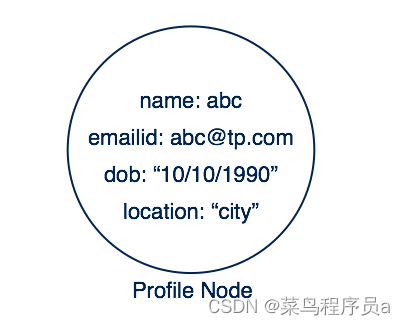
此节点包含一组属性。 属性是一个名称:键值对。
在两个节点之间创建关系
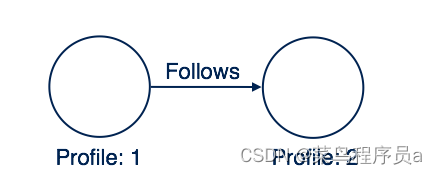
此处在两个配置文件之间创建关系名称“跟随”。 这意味着 Profile-I 遵循 Profile-II。
复杂的示例图
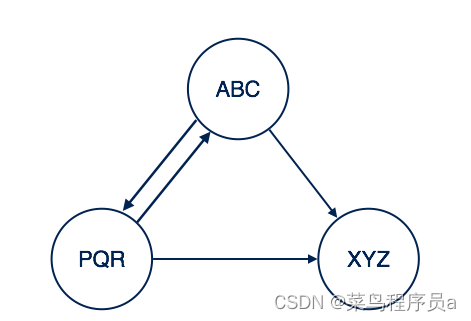
这里节点用关系连接。 关系是单向或双向的。
- 从PQR到XYZ的关系是单向关系。
- 从ABC到PQR的关系是双向关系。
5、 Neo4j体系结构
5.1 免索引邻接
Neo4j有一个重要的特点,就是用来保证关系查询的速度,即免索引邻接属性,数据库中的每个节点都会维护与它相邻节点的引用。因此每个节点都相当于与它相邻节点的微索引,这比使用全局索引的代价要小得多。这就意味着查询时间和图的整体规模无关,只与它附近节点的数量成正比。在关系型数据库中使用全局索引连接各个节点,这些索引对每个遍历都会增加一个中间层,因此会导致非常大的计算成本。而免索引邻接为图数据库提供了快速、高效的图遍历能力。
对比下面两图,可以明显的看出关系型数据库与Neo4j在查找关系时的区别。
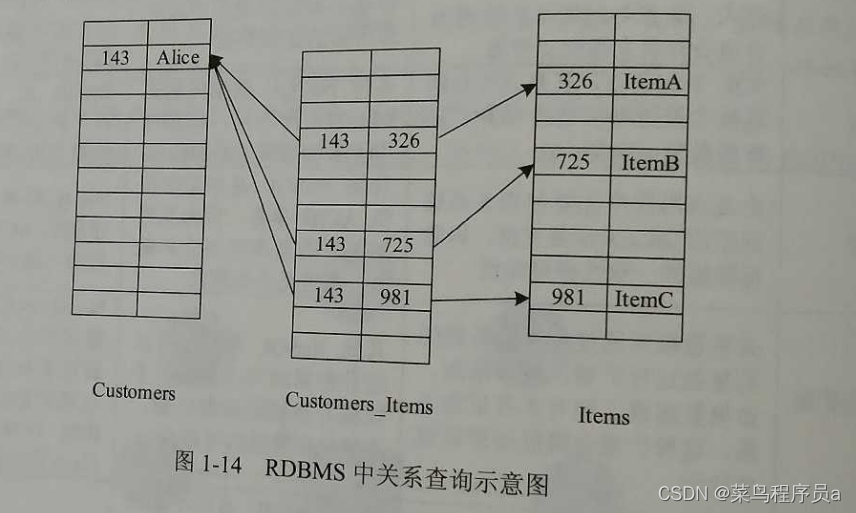
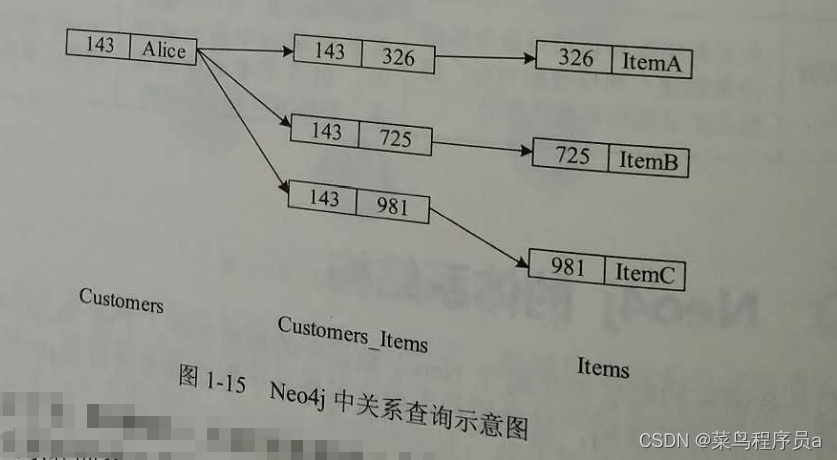
图1-14展示了在RDBMS(关系型数据库)中的查询方式。要查找Alice所购买的定西,首先要执行关系表的索引查询,时间成本为O(log(n)),n为索引表的长度。这对于偶尔的浅层次查询时可以接受的,但是当查询的层次变深或是执行反向查询时代价将会变得不可接受了。如果相较于查询Alice所购买的东西,要查询某件商品被哪些人购买了(推荐引擎中常用的一个场景),将不得不使用暴力方法来便利整个索引,时间复杂度将增长到O(n)。除非我们再建立-个从商品到用户的索引表,但是该方法将会占用许多额外的叽井 且使索引变得难以维护。
如果我们再考虑-个更复杂的场景,Alice购买过的商品被哪些人购买过(推荐引擎中查找有共同爱好的人),找到Alice购买过的商品的时间成本为O(log(n)),找到每个商品被哪 些人购买的时间成本为O(n),假如Alice购买过m(m远小于n)个商品,那么总的时间复杂 度即为O(mnlog(n))。即使再建立一个方向索引表,时间复杂度也为O(mn)。
图1-15展示了在同样的场景下Neo4j的查询方式。使用免索引近邻机制,每个节点都有 直接或间接指向其相邻节点的指针。要查找Alice买过的东西,只需要在Alice的关系链表中 遍历,每次的遍历成本仅为O(1)。要查找一个商品被哪些人购买了,只要跟随指向该商品的 关系来源即可,每次的遍历成本也是O(1)。更复杂的,要查找Alice购买过的东西被哪些人 购买过,时间复杂度也仅为O(m),其中m远小于n。这相较于RDBMS的时间复杂度还是占 有绝对的优势。
免索引邻接针对RDBMS中的关系查询的两个缺点做了改进:
(1)先索引邻接使用遍历物理美系的方法查找,比起全局索引来说代价要小得多。查询一个索引一般的时间复杂度为O(log(n)),而遍历物理关系的时间复杂度仅为O(1),至少对于 Neo4j的存储结构来说是如此。
(2)当索引建立之后在试图反向遍历时,建立的索引就起不到作用了。我们有两个选 择:对每个反向遍历的场景创建反向查找索引,或者使用原索引进行暴力搜索,而暴力搜索 的时间复杂度为O(n)。这种代价相对于很多需要实时操作的场景来说是不可接受的。
利用兔索引邻接机制,在图数据库上进行关系查询效率非常高,这种高效是建立在图数 据库注重关系的架构设计之上的。
5.2 Neo4j遍历方式
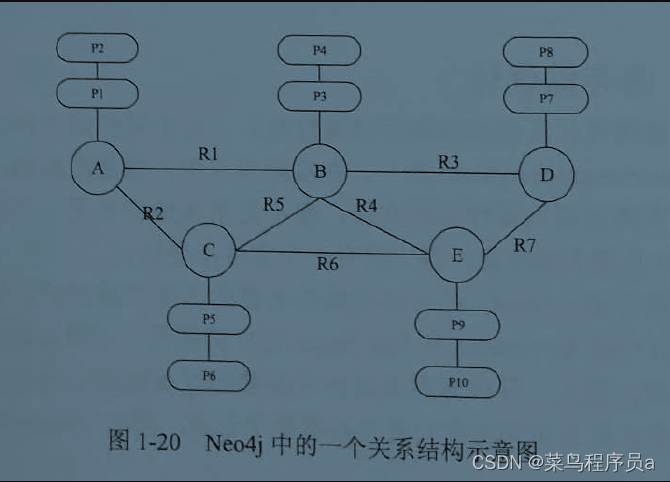
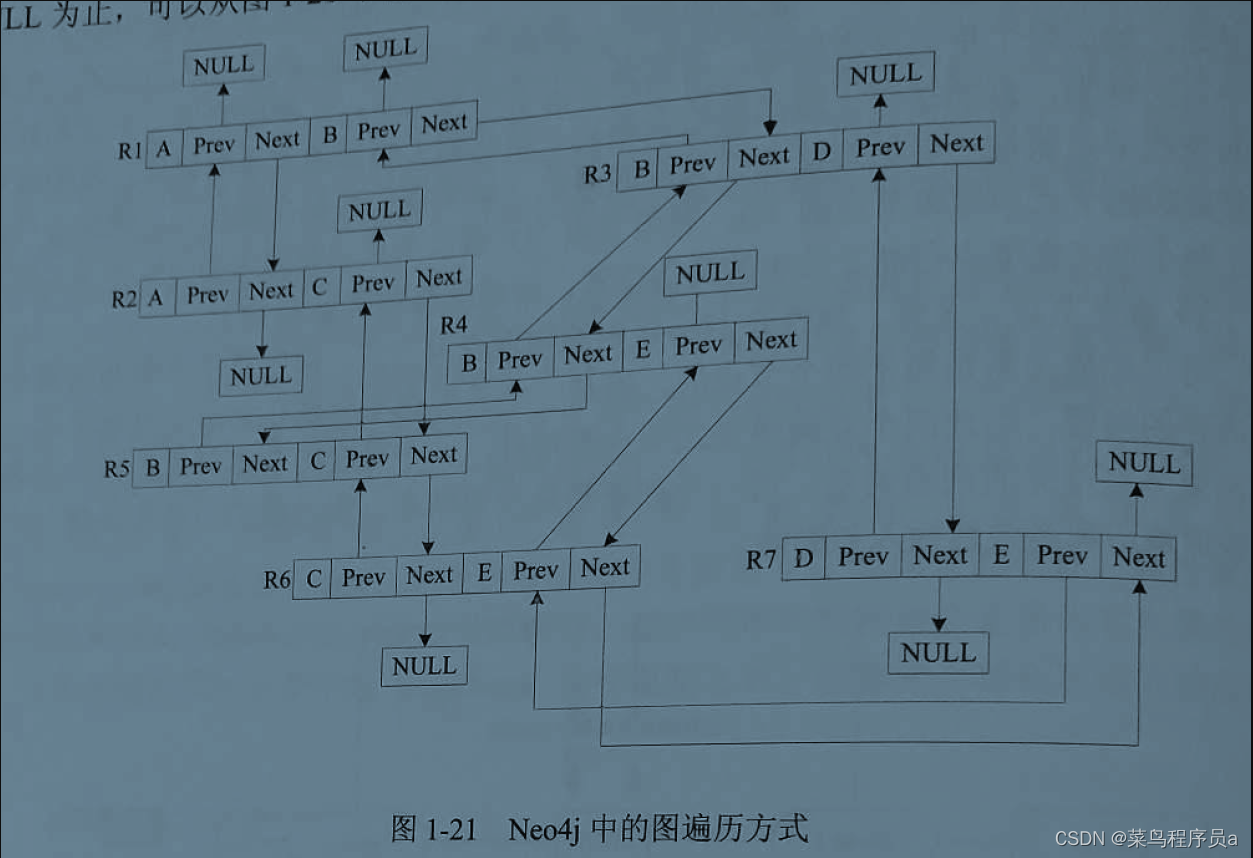
-
对于1-21图中的箭头导向就是指针.每个节点的所有指针组成了每个节点的双向关系链条
-
对于 1-21 图中的 R1 R2 R3 这些都是关系.
-
当你想要遍历一个节点的所有关系,通过双向链条的指针我们可以很容易遍历每个节点的所有关系
遍历规则:
遍历的时候从第一个next没有上一个箭头的关系开始正向遍历.或prev指向null的关系开始反向遍历
示例:
比如A.第一个关系是R1(AB),第二个关系是R2(AC).
同理遍历B.第一个关系R1(BA),第二个R3(BD) 第三个R4(BE) 第四个R5(BC) -
图1-20中的p1~p10可以理解为属性(单向链表,遍历属性的时候只能从头开始遍历到最后).属性值如果大小很小,就直接存放在属性存储文件里面,如果过大,申请动态存储,将对应动态存储文件里面的地址存放到属性里面。

















 3132
3132











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











