






前言
如果你一直关注 Stable Diffusion (SD) 社区,那你一定不会对 “LoRA” 这个名词感到陌生。社区用户分享的 SD LoRA 模型能够修改 SD 的画风,使之画出动漫、水墨或像素等风格的图片。但实际上,LoRA 不仅仅能改变 SD 的画风,还有其他的妙用。在这篇文章中,我们会先简单学习 LoRA 的原理,再认识科研中 LoRA 的三种常见应用:1) 还原单幅图像;2)风格调整;3)训练目标调整,最后阅读两个基于 Diffusers 的 SD LoRA 代码实现示例。
所有的AI设计工具,安装包、模型和插件,都已经整理好了,👇获取~

LoRA 的原理
在认识 LoRA 之前,我们先来回顾一下迁移学习的有关概念。迁移学习指在一次新的训练中,复用之前已经训练过的模型的知识。如果你自己动手训练过深度学习模型,那你应该不经意间地使用到了迁移学习:比如你一个模型训练了 500 步,测试后发现效果不太理想,于是重新读取该模型的参数,又继续训练了 100 步。之前那个被训练过的模型叫做预训练模型(pre-trained model),继续训练预训练模型的过程叫做微调(fine-tune)。
知道了微调的概念,我们就能来认识 LoRA 了。LoRA 的全称是 Low-Rank Adaptation (低秩适配),它是一种 Parameter-Efficient Fine-Tuning (参数高效微调,PEFT) 方法,即在微调时只训练原模型中的部分参数,以加速微调的过程。相比其他的 PEFT 方法,LoRA 之所以能脱颖而出,是因为它有几个明显的优点:
-
从性能上来看,使用 LoRA 时,只需要存储少量被微调过的参数,而不需要把整个新模型都保存下来。同时,LoRA 的新参数可以和原模型的参数合并到一起,不会增加模型的运算时间。
-
从功能上来看,LoRA 维护了模型在微调中的「变化量」。通过用一个介于 0~1 之间的混合比例乘变化量,我们可以控制模型的修改程度。此外,基于同一个原模型独立训练的多个 LoRA 可以同时使用。
这些优点在 SD LoRA 中的体现为:
-
SD LoRA 模型一般都很小,一般只有几十 MB。
-
SD LoRA 模型的参数可以合并到 SD 基础模型里,得到一个新的 SD 模型。
-
可以用一个 0~1 之间的比例来控制 SD LoRA 新画风的程度。
-
可以把不同画风的 SD LoRA 模型以不同比例混合。
为什么 LoRA 能有这些优点呢?LoRA 名字中的 「低秩」又是什么意思呢?让我们从 LoRA 的优点入手,逐步揭示它原理。
上文提到过,LoRA 之所以那么灵活,是因为它维护了模型在微调过程中的变化量。那么,假设我们正在修改模型中的一个参数 ,我们就应该维护它的变化量 ,训练时的参数用 表示。这样,想要在推理时控制模型的修改程度,只要添加一个 ,令使用的参数为 即可。
可是,这样做我们还是要记录一个和原参数矩阵一样大的参数矩阵 ,这就算不上是参数高效微调了。为此,LoRA 的作者提出假设:模型参数在微调时的变化量中蕴含的信息没有那么多。为了用更少的信息来表示参数的变化量,我们可以把拆解成两个低秩矩阵的乘积:
其中,, , 远大于参数 。这样,通过用两个参数量少得多的矩阵 来维护变化量,我们不仅提高了微调的效率,还保持了使用变化量来描述微调过程的灵活性。这就是 LoRA 的全部原理,它十分简单,用 这一行公式足以表示。
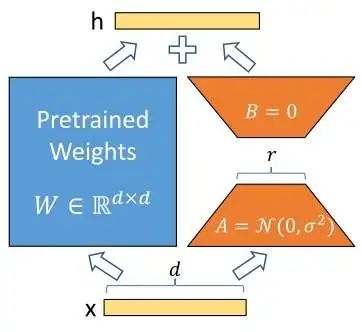
了解了 LoRA 的原理,我们再回头看前文提及的 LoRA 的四项优点。LoRA 模型由许多参数量较少的矩阵 来表示,它可以被单独存储,且占用空间不大。由于 维护的其实是参数的变化量,我们既可以把它与预训练模型的参数加起来得到一个新模型以提高推理速度,也可以在线地用一个混合比例来灵活地组合新旧模型。LoRA 的最后一个优点是各个基于同一个原模型独立训练出来的 LoRA 模型可以混合使用。LoRA 甚至可以作用于被其他方式修改过的原模型,比如 SD LoRA 支持带 ControlNet 的 SD。这一点其实来自于社区用户的实践。一个可能的解释是,LoRA 用低秩矩阵来表示变化量,这种低秩的变化量恰好与其他方法的变化量「错开」,使得 LoRA 能向着一个不干扰其他方法的方向修改模型。
我们最后来学习一下 LoRA 的实现细节。LoRA 有两个超参数,除了上文中提到的,还有一个叫的参数。LoRA 的作者在实现 LoRA 模块时,给修改量乘了一个 的系数,即对于输入,带了 LoRA 模块后的输出为 。作者解释说,调这个参数几乎等于调学习率,一开始令即可。在我们要反复调超参数时,只要保持不变,就不用改其他超参数了(因为不加的话,改了后,学习率等参数也得做相应调整以维持同样的训练条件)。当然,实际运用中,LoRA 的超参数很好调。一般令即可。由于我们不怎么会变,总是令就够了。
为了使用 LoRA,除了确定超参数外,我们还得指定需要被微调的参数矩阵。在 SD 中使用 LoRA 时,大家一般会对 SD 的 U-Net 的所有多头注意力模块的所有参数矩阵做微调。即对于多头注意力模块的四个矩阵 进行微调。
LoRA 在 SD 中的三种运用
LoRA 在 SD 的科研中有着广泛的应用。按照使用 LoRA 的动机,我们可以把 LoRA 的应用分成:1) 还原单幅图像;2)风格调整;3)训练目标调整。通过学习这些应用,我们能更好地理解 LoRA 的本质。
还原单幅图像
SD 只是一个生成任意图片的模型。为了用 SD 来编辑一张给定的图片,我们一般要让 SD 先学会生成一张一模一样的图片,再在此基础上做修改。可是,由于训练集和输入图片的差异,SD 或许不能生成完全一样的图片。解决这个问题的思路很简单粗暴:我们只用这一张图片来微调 SD,让 SD 在这张图片上过拟合。这样,SD 的输出就会和这张图片非常相似了。
较早介绍这种提高输入图片保真度方法的工作是 Imagic,只不过它采取的是完全微调策略。后续的 DragDiffusion 也用了相同的方法,并使用 LoRA 来代替完全微调。近期的 DiffMorpher 为了实现两幅图像间的插值,不仅对两幅图像单独训练了 LoRA,还通过两个 LoRA 间的插值来平滑图像插值的过程。
风格调整
LoRA 在 SD 社区中最受欢迎的应用就是风格调整了。我们希望 SD 只生成某一画风,或者某一人物的图片。为此,我们只需要在一个符合我们要求的训练集上直接训练 SD LoRA 即可。
由于这种调整 SD 风格的方法非常直接,没有特别介绍这种方法的论文。稍微值得一提的是基于 SD 的视频模型 AnimateDiff,它用 LoRA 来控制输出视频的视角变换,而不是控制画风。
由于 SD 风格化 LoRA 已经被广泛使用,能否兼容 SD 风格化 LoRA 决定了一个工作是否易于在社区中传播。
训练目标调整
最后一个应用就有一点返璞归真了。LoRA 最初的应用就是把一个预训练模型适配到另一任务上。比如 GPT 一开始在大量语料中训练,随后在问答任务上微调。对于 SD 来说,我们也可以修改 U-Net 的训练目标,以提升 SD 的能力。
有不少相关工作用 LoRA 来改进 SD。比如 Smooth Diffusion 通过在训练目标中添加一个约束项并进行 LoRA 微调来使得 SD 的隐空间更加平滑。近期比较火的高速图像生成方法 LCM-LoRA 也是把原本作用于 SD 全参数上的一个模型蒸馏过程用 LoRA 来实现。
SD LoRA 应用总结
尽管上述三种 SD LoRA 应用的设计出发点不同,它们本质上还是在利用微调这一迁移学习技术来调整模型的数据分布或者训练目标。LoRA 只是众多高效微调方法中的一种,只要是微调能实现的功能,LoRA 基本都能实现,只不过 LoRA 更轻便而已。如果你想微调 SD 又担心计算资源不够,那么用 LoRA 准没错。反过来说,你想用 LoRA 在 SD 上设计出一个新应用,就要去思考微调 SD 能够做到哪些事。
Diffusers SD LoRA 代码实战
看完了原理,我们来尝试用 Diffusers 自己训一训 LoRA。我们会先学习 Diffusers 训练 LoRA 的脚本,再学习两个简单的 LoRA 示例: SD 图像插值与 SD 图像风格迁移。
项目网址:https://github.com/SingleZombie/DiffusersExample/tree/main/LoRA
Diffusers 脚本
我们将参考 Diffusers 中的 SD LoRA 文档 https://huggingface.co/docs/diffusers/training/lora ,使用官方脚本 examples/text_to_image/train_text_to_image_lora.py 训练 LoRA。为了使用这个脚本,建议直接克隆官方仓库,并安装根目录和 text_to_image 目录下的依赖文件。本文使用的 Diffusers 版本是 0.26.0,过旧的 Diffusers 的代码可能和本文展示的有所出入。目前,官方文档也描述的是旧版的代码。
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install .
cd examples/text_to_image
pip install -r requirements.txt
这份代码使用 accelerate 库管理 PyTorch 的训练。对同一份代码,只需要修改 accelerate 的配置,就能实现单卡训练或者多卡训练。默认情况下,用 accelerate launch 命令运行 Python 脚本会使用所有显卡。如果你需要修改训练配置,请参考相关文档使用 accelerate config 命令配置环境。
做好准备后,我们来开始阅读 examples/text_to_image/train_text_to_image_lora.py 的代码。这份代码写得十分易懂,复杂的地方都有注释。我们跳过命令行参数部分,直接从 main 函数开始读。
一开始,函数会配置 accelerate 库及日志记录器。
args = parse_args()
logging_dir = Path(args.output_dir, args.logging_dir)
accelerator_project_config = ProjectConfiguration(project_dir=args.output_dir, logging_dir=logging_dir)
accelerator = Accelerator(
gradient_accumulation_steps=args.gradient_accumulation_steps,
mixed_precision=args.mixed_precision,
log_with=args.report_to,
project_config=accelerator_project_config,
)
if args.report_to == "wandb":
if not is_wandb_available():
raise ImportError("Make sure to install wandb if you want to use it for logging during training.")
import wandb
# Make one log on every process with the configuration for debugging.
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO,
)
logger.info(accelerator.state, main_process_only=False)
if accelerator.is_local_main_process:
datasets.utils.logging.set_verbosity_warning()
transformers.utils.logging.set_verbosity_warning()
diffusers.utils.logging.set_verbosity_info()
else:
datasets.utils.logging.set_verbosity_error()
transformers.utils.logging.set_verbosity_error()
diffusers.utils.logging.set_verbosity_error()
随后的代码决定是否手动设置随机种子。保持默认即可。
# If passed along, set the training seed now.
if args.seed is not None:
set_seed(args.seed)
接着,函数会创建输出文件夹。如果我们想把模型推送到在线仓库上,函数还会创建一个仓库。我们的项目不必上传,忽略所有 args.push_to_hub 即可。另外,if accelerator.is_main_process: 表示多卡训练时只有主进程会执行这段代码块。
# Handle the repository creation
if accelerator.is_main_process:
if args.output_dir is not None:
os.makedirs(args.output_dir, exist_ok=True)
if args.push_to_hub:
repo_id = create_repo(
repo_id=args.hub_model_id or Path(args.output_dir).name, exist_ok=True, token=args.hub_token
).repo_id
准备完辅助工具后,函数正式开始着手训练。训练前,函数会先实例化好一切处理类,包括用于维护扩散模型中间变量的 DDPMScheduler,负责编码输入文本的 CLIPTokenizer, CLIPTextModel,压缩图像的VAE AutoencoderKL,预测噪声的 U-Net UNet2DConditionModel。参数 args.pretrained_model_name_or_path 是 Diffusers 在线仓库的地址(如runwayml/stable-diffusion-v1-5),或者本地的 Diffusers 模型文件夹。
# Load scheduler, tokenizer and models.
noise_scheduler = DDPMScheduler.from_pretrained(args.pretrained_model_name_or_path, subfolder="scheduler")
tokenizer = CLIPTokenizer.from_pretrained(
args.pretrained_model_name_or_path, subfolder="tokenizer", revision=args.revision
)
text_encoder = CLIPTextModel.from_pretrained(
args.pretrained_model_name_or_path, subfolder="text_encoder", revision=args.revision
)
vae = AutoencoderKL.from_pretrained(
args.pretrained_model_name_or_path, subfolder="vae", revision=args.revision, variant=args.variant
)
unet = UNet2DConditionModel.from_pretrained(
args.pretrained_model_name_or_path, subfolder="unet", revision=args.revision, variant=args.variant
)
函数还会设置各个带参数模型是否需要计算梯度。由于我们待会要优化的是新加入的 LoRA 模型,所有预训练模型都不需要计算梯度。另外,函数还会根据 accelerate 配置自动设置这些模型的精度。
# freeze parameters of models to save more memory
unet.requires_grad_(False)
vae.requires_grad_(False)
text_encoder.requires_grad_(False)
# Freeze the unet parameters before adding adapters
for param in unet.parameters():
param.requires_grad_(False)
# For mixed precision training we cast all non-trainable weigths (vae, non-lora text_encoder and non-lora unet) to half-precision
# as these weights are only used for inference, keeping weights in full precision is not required.
weight_dtype = torch.float32
if accelerator.mixed_precision == "fp16":
weight_dtype = torch.float16
elif accelerator.mixed_precision == "bf16":
weight_dtype = torch.bfloat16
# Move unet, vae and text_encoder to device and cast to weight_dtype
unet.to(accelerator.device, dtype=weight_dtype)
vae.to(accelerator.device, dtype=weight_dtype)
text_encoder.to(accelerator.device, dtype=weight_dtype)
把预训练模型都调好了后,函数会配置 LoRA 模块并将其加入 U-Net 模型中。最近,Diffusers 更新了添加 LoRA 的方式。Diffusers 用 Attention 处理器来描述 Attention 的计算。为了把 LoRA 加入到 Attention 模块中,早期的 Diffusers 直接在 Attention 处理器里加入可训练参数。现在,为了和其他 Hugging Face 库统一,Diffusers 使用 PEFT 库来管理 LoRA。我们不需要关注 LoRA 的实现细节,只需要写一个 LoraConfig 就行了。
PEFT 中的 LoRA 文档参见 https://huggingface.co/docs/peft/conceptual_guides/lora
LoraConfig 中有四个主要参数: r, lora_alpha, init_lora_weights, target_modules。 r, lora_alpha 的意义我们已经在前文中见过了,前者决定了 LoRA 矩阵的大小,后者决定了训练速度。默认配置下,它们都等于同一个值 args.rank。init_lora_weights 表示如何初始化训练参数,gaussian是论文中使用的方法。target_modules 表示 Attention 模块的哪些层需要添加 LoRA。按照通常的做法,会给所有层,即三个输入变换矩阵 to_k, to_q, to_v 和一个输出变换矩阵 to_out.0 加 LoRA。
创建了配置后,用 unet.add_adapter(unet_lora_config) 就可以创建 LoRA 模块。
unet_lora_config = LoraConfig(
r=args.rank,
lora_alpha=args.rank,
init_lora_weights="gaussian",
target_modules=["to_k", "to_q", "to_v", "to_out.0"],
)
unet.add_adapter(unet_lora_config)
if args.mixed_precision == "fp16":
for param in unet.parameters():
# only upcast trainable parameters (LoRA) into fp32
if param.requires_grad:
param.data = param.to(torch.float32)
更新完了 U-Net 的结构,函数会尝试启用 xformers 来提升 Attention 的效率。PyTorch 在 2.0 版本也加入了类似的 Attention 优化技术。如果你的显卡性能有限,且 PyTorch 版本小于 2.0,可以考虑使用 xformers。
if args.enable_xformers_memory_efficient_attention:
if is_xformers_available():
import xformers
xformers_version = version.parse(xformers.__version__)
if xformers_version == version.parse("0.0.16"):
logger.warn(
...
)
unet.enable_xformers_memory_efficient_attention()
else:
raise ValueError("xformers is not available. Make sure it is installed correctly")
做完了 U-Net 的处理后,函数会过滤出要优化的模型参数,这些参数稍后会传递给优化器。过滤的原则很简单,如果参数要求梯度,就是待优化参数。
lora_layers = filter(lambda p: p.requires_grad, unet.parameters())
之后是优化器的配置。函数先是配置了一些细枝末节的训练选项,一般可以忽略。
if args.gradient_checkpointing:
unet.enable_gradient_checkpointing()
# Enable TF32 for faster training on Ampere GPUs,
# cf https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices
if args.allow_tf32:
torch.backends.cuda.matmul.allow_tf32 = True
然后是优化器的选择。我们可以忽略其他逻辑,直接用 AdamW。
# Initialize the optimizer
if args.use_8bit_adam:
try:
import bitsandbytes as bnb
except ImportError:
raise ImportError(
"..."
)
optimizer_cls = bnb.optim.AdamW8bit
else:
optimizer_cls = torch.optim.AdamW
选择了优化器类,就可以实例化优化器了。优化器的第一个参数是之前准备好的待优化 LoRA 参数,其他参数是 Adam 优化器本身的参数。
optimizer = optimizer_cls(
lora_layers,
lr=args.learning_rate,
betas=(args.adam_beta1, args.adam_beta2),
weight_decay=args.adam_weight_decay,
eps=args.adam_epsilon,
)
准备了优化器,之后需要准备训练集。这个脚本用 Hugging Face 的 datasets 库来管理数据集。我们既可以读取在线数据集,也可以读取本地的图片文件夹数据集。在本文的示例项目中,我们将使用图片文件夹数据集。稍后我们再详细学习这样的数据集文件夹该怎么构建。相关的文档可以参考 https://huggingface.co/docs/datasets/v2.4.0/en/image_load#imagefolder 。
if args.dataset_name is not None:
# Downloading and loading a dataset from the hub.
dataset = load_dataset(
args.dataset_name,
args.dataset_config_name,
cache_dir=args.cache_dir,
data_dir=args.train_data_dir,
)
else:
data_files = {}
if args.train_data_dir is not None:
data_files["train"] = os.path.join(args.train_data_dir, "**")
dataset = load_dataset(
"imagefolder",
data_files=data_files,
cache_dir=args.cache_dir,
)
# See more about loading custom images at
# https://huggingface.co/docs/datasets/v2.4.0/en/image_load#imagefolder
训练 SD 时,每一个数据样本需要包含两项信息:图像数据与对应的文本描述。在数据集 dataset 中,每个数据样本包含了多项属性。下面的代码用于从这些属性中取出图像与文本描述。默认情况下,第一个属性会被当做图像数据,第二个属性会被当做文本。
# Preprocessing the datasets.
# We need to tokenize inputs and targets.
column_names = dataset["train"].column_names
# 6. Get the column names for input/target.
dataset_columns = DATASET_NAME_MAPPING.get(args.dataset_name, None)
if args.image_column is None:
image_column = dataset_columns[0] if dataset_columns is not None else column_names[0]
else:
image_column = args.image_column
if image_column not in column_names:
raise ValueError(
f"--image_column' value '{args.image_column}' needs to be one of: {', '.join(column_names)}"
)
if args.caption_column is None:
caption_column = dataset_columns[1] if dataset_columns is not None else column_names[1]
else:
caption_column = args.caption_column
if caption_column not in column_names:
raise ValueError(
f"--caption_column' value '{args.caption_column}' needs to be one of: {', '.join(column_names)}"
)
准备好了数据集,接下来要定义数据预处理流程以创建 DataLoader。函数先定义了一个把文本标签预处理成 token ID 的 token 化函数。我们不需要修改它。
def tokenize_captions(examples, is_train=True):
captions = []
for caption in examples[caption_column]:
if isinstance(caption, str):
captions.append(caption)
elif isinstance(caption, (list, np.ndarray)):
# take a random caption if there are multiple
captions.append(random.choice(caption) if is_train else caption[0])
else:
raise ValueError(
f"Caption column `{caption_column}` should contain either strings or lists of strings."
)
inputs = tokenizer(
captions, max_length=tokenizer.model_max_length, padding="max_length", truncation=True, return_tensors="pt"
)
return inputs.input_ids
接着,函数定义了图像数据的预处理流程。该流程是用 torchvision 中的 transforms 实现的。如代码所示,处理流程中包括了 resize 至指定分辨率 args.resolution、将图像长宽均裁剪至指定分辨率、随机翻转、转换至 tensor 和归一化。
经过这一套预处理后,所有图像的长宽都会被设置为 args.resolution 。统一图像的尺寸,主要的目的是对齐数据,以使多个数据样本能拼接成一个 batch。注意,数据预处理流程中包括了随机裁剪。如果数据集里的多数图片都长宽不一致,模型会倾向于生成被裁剪过的图片。为了解决这一问题,要么自己手动预处理图片,使训练图片都是分辨率至少为 args.resolution 的正方形图片,要么令 batch size 为 1 并取消掉随机裁剪。
# Preprocessing the datasets.
train_transforms = transforms.Compose(
[
transforms.Resize(
args.resolution, interpolation=transforms.InterpolationMode.BILINEAR),
transforms.CenterCrop(
args.resolution) if args.center_crop else transforms.RandomCrop(args.resolution),
transforms.RandomHorizontalFlip() if args.random_flip else transforms.Lambda(lambda x: x),
transforms.ToTensor(),
transforms.Normalize([0.5], [0.5]),
]
)
定义了预处理流程后,函数对所有数据进行预处理。
def preprocess_train(examples):
images = [image.convert("RGB") for image in examples[image_column]]
examples["pixel_values"] = [
train_transforms(image) for image in images]
examples["input_ids"] = tokenize_captions(examples)
return examples
with accelerator.main_process_first():
if args.max_train_samples is not None:
dataset["train"] = dataset["train"].shuffle(
seed=args.seed).select(range(args.max_train_samples))
# Set the training transforms
train_dataset = dataset["train"].with_transform(preprocess_train)
之后函数用预处理过的数据集创建 DataLoader。这里要注意的参数是 batch size args.train_batch_size 和读取数据的进程数 args.dataloader_num_workers 。这两个参数的用法和一般的 PyTorch 项目一样。args.train_batch_size 决定了训练速度,一般设置到不爆显存的最大值。如果要读取的数据过多,导致数据读取成为了模型训练的速度瓶颈,则应该提高 args.dataloader_num_workers。
def collate_fn(examples):
pixel_values = torch.stack([example["pixel_values"]
for example in examples])
pixel_values = pixel_values.to(
memory_format=torch.contiguous_format).float()
input_ids = torch.stack([example["input_ids"] for example in examples])
return {"pixel_values": pixel_values, "input_ids": input_ids}
# DataLoaders creation:
train_dataloader = torch.utils.data.DataLoader(
train_dataset,
shuffle=True,
collate_fn=collate_fn,
batch_size=args.train_batch_size,
num_workers=args.dataloader_num_workers,
)
如果想用更大的 batch size,显存又不够,则可以使用梯度累计技术。使用这项技术时,训练梯度不会每步优化,而是累计了若干步后再优化。args.gradient_accumulation_steps 表示要累计几步再优化模型。实际的 batch size 等于输入 batch size 乘 GPU 数乘梯度累计步数。下面的代码维护了训练步数有关的信息,并创建了学习率调度器。我们按照默认设置使用一个常量学习率即可。
# Scheduler and math around the number of training steps.
overrode_max_train_steps = False
num_update_steps_per_epoch = math.ceil(
len(train_dataloader) / args.gradient_accumulation_steps)
if args.max_train_steps is None:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
overrode_max_train_steps = True
lr_scheduler = get_scheduler(
args.lr_scheduler,
optimizer=optimizer,
num_warmup_steps=args.lr_warmup_steps * accelerator.num_processes,
num_training_steps=args.max_train_steps * accelerator.num_processes,
)
# Prepare everything with our `accelerator`.
unet, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
unet, optimizer, train_dataloader, lr_scheduler
)
# We need to recalculate our total training steps as the size of the training dataloader may have changed.
num_update_steps_per_epoch = math.ceil(
len(train_dataloader) / args.gradient_accumulation_steps)
if overrode_max_train_steps:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
# Afterwards we recalculate our number of training epochs
args.num_train_epochs = math.ceil(
args.max_train_steps / num_update_steps_per_epoch)
在准备工作的最后,函数会用 accelerate 库记录配置信息。
if accelerator.is_main_process:
accelerator.init_trackers("text2image-fine-tune", config=vars(args))
终于,要开始训练了。训练开始前,函数会准备全局变量并记录日志。
# Train!
total_batch_size = args.train_batch_size * \
accelerator.num_processes * args.gradient_accumulation_steps
logger.info("***** Running training *****")
...
global_step = 0
first_epoch = 0
此时,如果设置了 args.resume_from_checkpoint,则函数会读取之前训练过的权重。一般继续训练时可以把该参数设为 latest,程序会自动找最新的权重。
# Potentially load in the weights and states from a previous save
if args.resume_from_checkpoint:
if args.resume_from_checkpoint != "latest":
path = ...
else:
# Get the most recent checkpoint
path = ...
if path is None:
args.resume_from_checkpoint = None
initial_global_step = 0
else:
accelerator.load_state(os.path.join(args.output_dir, path))
global_step = int(path.split("-")[1])
initial_global_step = global_step
first_epoch = global_step // num_update_steps_per_epoch
else:
initial_global_step = 0
随后,函数根据总步数和已经训练过的步数设置迭代器,正式进入训练循环。
progress_bar = tqdm(
range(0, args.max_train_steps),
initial=initial_global_step,
desc="Steps",
# Only show the progress bar once on each machine.
disable=not accelerator.is_local_main_process,
)
for epoch in range(first_epoch, args.num_train_epochs):
unet.train()
train_loss = 0.0
for step, batch in enumerate(train_dataloader):
with accelerator.accumulate(unet):
训练的过程基本和 LDM 论文中展示的一致。一开始,要取出图像batch["pixel_values"] 并用 VAE 把它压缩进隐空间。
# Convert images to latent space
latents = vae.encode(batch["pixel_values"].to(
dtype=weight_dtype)).latent_dist.sample()
latents = latents * vae.config.scaling_factor
再随机生成一个噪声。该噪声会套入扩散模型前向过程的公式,和输入图像一起得到 t 时刻的带噪图像。
# Sample noise that we'll add to the latents
noise = torch.randn_like(latents)
下一步,这里插入了一个提升扩散模型训练质量的小技巧,用上它后输出图像的颜色分布会更合理。原理见注释中的链接。args.noise_offset 默认为 0。如果要启用这个特性,一般令 args.noise_offset = 0.1。
if args.noise_offset:
# https://www.crosslabs.org//blog/diffusion-with-offset-noise
noise += args.noise_offset * torch.randn(
(latents.shape[0], latents.shape[1], 1, 1), device=latents.device
)
然后是时间戳的随机生成。
bsz = latents.shape[0]
# Sample a random timestep for each image
timesteps = torch.randint(
0, noise_scheduler.config.num_train_timesteps, (bsz,), device=latents.device)
timesteps = timesteps.long()
时间戳和前面随机生成的噪声一起经 DDPM 的前向过程得到带噪图片 noisy_latents。
# Add noise to the latents according to the noise magnitude at each timestep
# (this is the forward diffusion process)
noisy_latents = noise_scheduler.add_noise(
latents, noise, timesteps)
再把文本 batch["input_ids"] 编码,为之后的 U-Net 前向传播做准备。
# Get the text embedding for conditioning
encoder_hidden_states = text_encoder(batch["input_ids"])[0]
在 U-Net 推理开始前,函数这里做了一个关于 U-Net 输出类型的判断。一般 U-Net 都是输出预测的噪声 epsilon,可以忽略这段代码。当 U-Net 是想预测噪声时,要拟合的目标是之前随机生成的噪声 noise 。
# Get the target for loss depending on the prediction type
if args.prediction_type is not None:
# set prediction_type of scheduler if defined
noise_scheduler.register_to_config(
prediction_type=args.prediction_type)
if noise_scheduler.config.prediction_type == "epsilon":
target = noise
elif noise_scheduler.config.prediction_type == "v_prediction":
target = noise_scheduler.get_velocity(
latents, noise, timesteps)
else:
raise ValueError(
f"Unknown prediction type {noise_scheduler.config.prediction_type}")
之后把带噪图像、时间戳、文本编码输入进 U-Net,U-Net 输出预测的噪声。
# Predict the noise residual and compute loss
model_pred = unet(noisy_latents, timesteps,
encoder_hidden_states).sample
有了预测值,下一步是算 loss。这里又可以选择是否使用一种加速训练的技术。如果使用,则 args.snr_gamma 推荐设置为 5.0。原 DDPM 的做法是直接算预测噪声和真实噪声的均方误差。
if args.snr_gamma is None:
loss = F.mse_loss(model_pred.float(),
target.float(), reduction="mean")
else:
# Compute loss-weights as per Section 3.4 of https://arxiv.org/abs/2303.09556.
...
训练迭代的最后,要用 accelerate 库来完成梯度计算和反向传播。在更新梯度前,可以通过设置 args.max_grad_norm 来裁剪梯度,以防梯度过大。args.max_grad_norm 默认为 1.0。代码中的 if accelerator.sync_gradients: 可以保证所有 GPU 都同步了梯度再执行后续代码。
# Backpropagate
accelerator.backward(loss)
if accelerator.sync_gradients:
params_to_clip = lora_layers
accelerator.clip_grad_norm_(
params_to_clip, args.max_grad_norm)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
一步训练结束后,更新和步数相关的变量。
if accelerator.sync_gradients:
progress_bar.update(1)
global_step += 1
accelerator.log({"train_loss": train_loss}, step=global_step)
train_loss = 0.0
脚本默认每 args.checkpointing_steps 步保存一次中间结果。当需要保存时,函数会清理多余的 checkpoint,再把模型状态和 LoRA 模型分别保存下来。accelerator.save_state(save_path) 负责把模型及优化器等训练用到的所有状态存下来,后面的 StableDiffusionPipeline.save_lora_weights 负责存储 LoRA 模型。
if global_step % args.checkpointing_steps == 0:
if accelerator.is_main_process:
# _before_ saving state, check if this save would set us over the `checkpoints_total_limit`
if args.checkpoints_total_limit is not None:
checkpoints = ...
if len(checkpoints) >= args.checkpoints_total_limit:
# remove ckpt
...
save_path = os.path.join(
args.output_dir, f"checkpoint-{global_step}")
accelerator.save_state(save_path)
unwrapped_unet = accelerator.unwrap_model(unet)
unet_lora_state_dict = convert_state_dict_to_diffusers(
get_peft_model_state_dict(unwrapped_unet)
)
StableDiffusionPipeline.save_lora_weights(
save_directory=save_path,
unet_lora_layers=unet_lora_state_dict,
safe_serialization=True,
)
logger.info(f"Saved state to {save_path}")
训练循环的最后,函数会更新进度条上的信息,并根据当前的训练步数决定是否停止训练。
logs = {"step_loss": loss.detach().item(
), "lr": lr_scheduler.get_last_lr()[0]}
progress_bar.set_postfix(**logs)
if global_step >= args.max_train_steps:
break
训完每一个 epoch 后,函数会进行验证。默认的验证方法是新建一个图像生成 pipeline,生成一些图片并保存。如果有其他验证方法,如计算某一指标,可以自行编写这部分的代码。
if accelerator.is_main_process:
if args.validation_prompt is not None and epoch % args.validation_epochs == 0:
logger.info(
f"Running validation... \n Generating {args.num_validation_images} images with prompt:"
f" {args.validation_prompt}."
)
pipeline = DiffusionPipeline.from_pretrained(...)
...
所有训练结束后,函数会再存一次最终的 LoRA 模型权重。
# Save the lora layers
accelerator.wait_for_everyone()
if accelerator.is_main_process:
unet = unet.to(torch.float32)
unwrapped_unet = accelerator.unwrap_model(unet)
unet_lora_state_dict = convert_state_dict_to_diffusers(
get_peft_model_state_dict(unwrapped_unet))
StableDiffusionPipeline.save_lora_weights(
save_directory=args.output_dir,
unet_lora_layers=unet_lora_state_dict,
safe_serialization=True,
)
if args.push_to_hub:
...
函数还会再测试一次模型。具体方法和之前的验证是一样的。
# Final inference
# Load previous pipeline
if args.validation_prompt is not None:
...
运行完了这里,函数也就结束了。
accelerator.end_training()
为了方便使用,我把这个脚本改写了一下:删除了部分不常用的功能,并且配置参数能通过配置文件而不是命令行参数传入。新的脚本为项目根目录下的 train_lora.py,示例配置文件在 cfg 目录下。
以 cfg 中的某个配置文件为例,我们来回顾一下训练脚本主要用到的参数:
{
"log_dir": "log",
"output_dir": "ckpt",
"data_dir": "dataset/mountain",
"ckpt_name": "mountain",
"gradient_accumulation_steps": 1,
"pretrained_model_name_or_path": "runwayml/stable-diffusion-v1-5",
"rank": 8,
"enable_xformers_memory_efficient_attention": true,
"learning_rate": 1e-4,
"adam_beta1": 0.9,
"adam_beta2": 0.999,
"adam_weight_decay": 1e-2,
"adam_epsilon": 1e-08,
"resolution": 512,
"n_epochs": 200,
"checkpointing_steps": 500,
"train_batch_size": 1,
"dataloader_num_workers": 1,
"lr_scheduler_name": "constant",
"resume_from_checkpoint": false,
"noise_offset": 0.1,
"max_grad_norm": 1.0
}
需要关注的参数:output_dir 为输出 checkpoint 的文件夹,ckpt_name 为输出 checkpoint 的文件名。data_dir 是训练数据集所在文件夹。pretrained_model_name_or_path 为 SD 模型文件夹。rank 是决定 LoRA 大小的参数。learning_rate 是学习率。adam 打头的是 AdamW 优化器的参数。resolution 是训练图片的统一分辨率。n_epochs 是训练的轮数。checkpointing_steps 指每过多久存一次 checkpoint。train_batch_size 是 batch size。gradient_accumulation_steps 是梯度累计步数。
要修改这个配置文件,要先把文件夹的路径改对,填上训练时的分辨率,再通过 gradient_accumulation_steps 和 train_batch_size 决定 batch size,接着填 n_epochs (一般训 10~20 轮就会过拟合)。最后就可以一边改 LoRA 的主要超参数 rank 一边反复训练了。
SD 图像插值
在这个示例中,我们来实现 DiffMorpher 工作的一小部分,完成一个简单的图像插值工具。在此过程中,我们将学会怎么在单张图片上训练 SD LoRA,以验证我们的训练环境。
这个工具的原理很简单:我们对两张图片分别训练一个 LoRA。之后,为了获取两张图片的插值,我们可以对两张图片 DDIM Inversion 的初始隐变量及两个 LoRA 分别插值,用插值过的隐变量在插值过的 SD LoRA 上生成图片就能得到插值图片。
该示例的所有数据和代码都已经在项目文件夹中给出。首先,我们看一下该怎么在单张图片上训 LoRA。训练之前,我们要准备一个数据集文件夹。数据集文件夹及包含所有图片及一个描述文件 metadata.jsonl。比如单图片的数据集文件夹的结构应如下所示:
├── mountain
│ ├── metadata.jsonl
│ └── mountain.jpg
metadata.jsonl 元数据文件的每一行都是一个 json 结构,包含该图片的路径及文本描述。单图片的元数据文件如下:
{"file_name": "mountain.jpg", "text": "mountain"}
如果是多图片,就应该是:
{"file_name": "mountain.jpg", "text": "mountain"}
{"file_name": "mountain_up.jpg", "text": "mountain"}
...
我们可以运行项目目录下的数据集测试文件 test_dataset.py 来看看 datasets 库的数据集对象包含哪些信息。
from datasets import load_dataset
dataset = load_dataset("imagefolder", data_dir="dataset/mountain")
print(dataset)
print(dataset["train"].column_names)
print(dataset["train"]['image'])
print(dataset["train"]['text'])
其输出大致为:
Generating train split: 1 examples [00:00, 66.12 examples/s]
DatasetDict({
train: Dataset({
features: ['image', 'text'],
num_rows: 1
})
})
['image', 'text']
[<PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=512x512 at 0x7F0400246670>]
['mountain']
这说明数据集对象实际上是一个词典。默认情况下,数据集放在词典的 train 键下。数据集的 column_names 属性可以返回每项数据有哪些属性。在我们的数据集里,数据的 image 是图像数据,text 是文本标签。训练脚本默认情况下会把每项数据的第一项属性作为图像,第二项属性作为文本标签。我们的这个数据集定义与训练脚本相符。
认识了数据集,我们可以来训练模型了。用下面的两行命令就可以分别在两张图片上训练 LoRA。
python train_lora.py cfg/mountain.json
python train_lora.py cfg/mountain_up.json
如果要用所有显卡训练,则应该用 accelerate。当然,对于这个简单的单图片训练,不需要用那么多显卡。
accelerate launch train_lora.py cfg/mountain.json
accelerate launch train_lora.py cfg/mountain_up.json
这两个 LoRA 模型的配置文件我们已经在前文见过了。相比普通的风格化 LoRA,这两个 LoRA 的训练轮数非常多,有 200 轮。设置较大的训练轮数能保证模型在单张图片上过拟合。
训练结束后,项目的 ckpt 文件夹下会多出两个 LoRA 权重文件: mountain.safetensor, mountain_up.safetensor。我们可以用它们来做图像插值了。
图像插值的脚本为 morph.py,它的主要内容为:
import torch
from inversion_pipeline import InversionPipeline
lora_path = 'ckpt/mountain.safetensor'
lora_path2 = 'ckpt/mountain_up.safetensor'
sd_path = 'runwayml/stable-diffusion-v1-5'
pipeline: InversionPipeline = InversionPipeline.from_pretrained(
sd_path).to("cuda")
pipeline.load_lora_weights(lora_path, adapter_name='a')
pipeline.load_lora_weights(lora_path2, adapter_name='b')
img1_path = 'dataset/mountain/mountain.jpg'
img2_path = 'dataset/mountain_up/mountain_up.jpg'
prompt = 'mountain'
latent1 = pipeline.inverse(img1_path, prompt, 50, guidance_scale=1)
latent2 = pipeline.inverse(img2_path, prompt, 50, guidance_scale=1)
n_frames = 10
images = []
for i in range(n_frames + 1):
alpha = i / n_frames
pipeline.set_adapters(["a", "b"], adapter_weights=[1 - alpha, alpha])
latent = slerp(latent1, latent2, alpha)
output = pipeline(prompt=prompt, latents=latent,
guidance_scale=1.0).images[0]
images.append(output)
对于每一个 Diffusers 的 Pipeline 类实例,都可以用 pipeline.load_lora_weights 来读取 LoRA 权重。如果我们在同一个模型上使用了多个 LoRA,为了区分它们,我们要加上 adapter_name 参数为每个 LoRA 命名。稍后我们会用到这些名称。
pipeline.load_lora_weights(lora_path, adapter_name='a')
pipeline.load_lora_weights(lora_path2, adapter_name='b')
读好了文件,使用已经写好的 DDIM Inversion 方法来得到两张图片的初始隐变量。
img1_path = 'dataset/mountain/mountain.jpg'
img2_path = 'dataset/mountain_up/mountain_up.jpg'
prompt = 'mountain'
latent1 = pipeline.inverse(img1_path, prompt, 50, guidance_scale=1)
latent2 = pipeline.inverse(img2_path, prompt, 50, guidance_scale=1)
最后开始生成不同插值比例的图片。根据混合比例 alpha,我们可以用 pipeline.set_adapters(["a", "b"], adapter_weights=[1 - alpha, alpha]) 来融合 LoRA 模型的比例。随后,我们再根据 alpha 对隐变量插值。用插值隐变量在插值 SD LoRA 上生成图片即可得到最终的插值图片。
n_frames = 10
images = []
for i in range(n_frames + 1):
alpha = i / n_frames
pipeline.set_adapters(["a", "b"], adapter_weights=[1 - alpha, alpha])
latent = slerp(latent1, latent2, alpha)
output = pipeline(prompt=prompt, latents=latent,
guidance_scale=1.0).images[0]
images.append(output)
下面两段动图中,左图和右图分别是无 LoRA 和有 LoRA 的插值结果。可见,通过 LoRA 权重上的插值,图像插值的过度会更加自然。

图片风格迁移
接下来,我们来实现最流行的 LoRA 应用——风格化 LoRA。当然,训练一个每张随机输出图片都质量很高的模型是很困难的。我们退而求其次,来实现一个能对输入图片做风格迁移的 LoRA 模型。
训练风格化 LoRA 对技术要求不高,其主要难点其实是在数据收集上。大家可以根据自己的需求,准备自己的数据集。我在本文中会分享我的实验结果。我希望把《弹丸论破》的画风——一种颜色渐变较多的动漫画风——应用到一张普通动漫画风的图片上。

由于我的目标是拟合画风而不是某一种特定的物体,我直接选取了 50 张左右的游戏 CG 构成训练数据集,且没有对图片做任何处理。训风格化 LoRA 时,文本标签几乎没用,我把所有数据的文本都设置成了游戏名 danganronpa。
{"file_name": "1.png", "text": "danganronpa"}
...
{"file_name": "59.png", "text": "danganronpa"}
我的配置文件依然和前文的相同,LoRA rank 设置为 8。我一共训了 100 轮,但发现训练后期模型的过拟合很严重,其实令 n_epochs 为 10 到 20 就能有不错的结果。50 张图片训 10 轮最多几十分钟就训完。
由于训练图片的内容不够多样,且图片预处理时加入了随机裁剪,我的 LoRA 模型随机生成的图片质量较低。于是我决定在图像风格迁移任务上测试该模型。具体来说,我使用了 ControlNet Canny 加上图生图 (SDEdit)技术。相关的代码如下:
from diffusers import StableDiffusionControlNetImg2ImgPipeline, ControlNetModel
from PIL import Image
import cv2
import numpy as np
lora_path = '...'
sd_path = 'runwayml/stable-diffusion-v1-5'
controlnet_canny_path = 'lllyasviel/sd-controlnet-canny'
prompt = '1 man, look at right, side face, Ace Attorney, Phoenix Wright, best quality, danganronpa'
neg_prompt = 'longbody, lowres, bad anatomy, bad hands, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, {multiple people}'
img_path = '...'
init_image = Image.open(img_path).convert("RGB")
init_image = init_image.resize((768, 512))
np_image = np.array(init_image)
# get canny image
np_image = cv2.Canny(np_image, 100, 200)
np_image = np_image[:, :, None]
np_image = np.concatenate([np_image, np_image, np_image], axis=2)
canny_image = Image.fromarray(np_image)
canny_image.save('tmp_edge.png')
controlnet = ControlNetModel.from_pretrained(controlnet_canny_path)
pipe = StableDiffusionControlNetImg2ImgPipeline.from_pretrained(
sd_path, controlnet=controlnet
)
pipe.load_lora_weights(lora_path)
output = pipe(
prompt=prompt,
negative_prompt=neg_prompt,
strength=0.5,
guidance_scale=7.5,
controlnet_conditioning_scale=0.5,
num_inference_steps=50,
image=init_image,
cross_attention_kwargs={"scale": 1.0},
control_image=canny_image,
).images[0]
output.save("tmp.png")
StableDiffusionControlNetImg2ImgPipeline 是 Diffusers 中 ControlNet 加图生图的 Pipeline。使用它生成图片的重要参数有:
-
strength:0~1 之间重绘比例。越低越接近输入图片。 -
controlnet_conditioning_scale: 0~1 之间的 ControlNet 约束比例。越高越贴近约束。 -
cross_attention_kwargs={"scale": scale}:此处的scale是 0~1 之间的 LoRA 混合比例。越高越贴近 LoRA 模型的输出。
这里贴一下输入图片和两张编辑后的图片。



可以看出,输出图片中人物的画风确实得到了修改,颜色渐变更加丰富。我在几乎没有调试 LoRA 参数的情况下得到了这样的结果,可见虽然训练一个高质量的随机生成新画风的 LoRA 难度较高,但只是做风格迁移还是比较容易的。
尽管实验的经历不多,我还是基本上了解了 SD LoRA 风格化的能力边界。LoRA 风格化的本质还是修改输出图片的分布,数据集的质量基本上决定了生成的质量,其他参数的影响不会很大(包括训练图片的文本标签)。数据集最好手动裁剪至 512x512。如果想要生成丰富的风格化内容而不是只生成人物,就要丰富训练数据,减少人物数据的占比。训练时,最容易碰到的机器学习上的问题是过拟合问题。解决此问题的最简单的方式是早停,即不用最终的训练结果而用中间某一步的结果。如果你想实现改变输出数据分布以外的功能,比如精确生成某类物体、向模型中加入一些改变画风的关键词,那你应该使用更加先进的技术,而不仅仅是用最基本的 LoRA 微调。
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
对于0基础小白入门:
如果你是零基础小白,想快速入门AI绘画是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:stable diffusion安装包、stable diffusion0基础入门全套PDF,视频学习教程。带你从零基础系统性的学好AI绘画!
零基础AI绘画学习资源介绍
👉stable diffusion新手0基础入门PDF👈

👉AI绘画必备工具👈

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉AI绘画基础+速成+进阶使用教程👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉12000+AI关键词大合集👈

这份完整版的AI绘画全套学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









