




1、简介
上一篇文章解释了什么是 mmap 内存映射及其在 Linux 内核中的实现原理,然后深入到源码中一步一步分析 mmap 在内核中的源码实现。mmap内存映射的核心就是在进程虚拟内存空间中为该次映射分配一段虚拟内存出来,然后将这段虚拟内存与磁盘文件建立映射关系。但此时内核并不会为映射分配物理内存,物理内存的分配工作需要延后到这段虚拟内存被CPU访问的时候,通过缺页中断来进入内核来分配物理内存,并在页表中建立好映射关系。那么,接下来就跟随笔者一步步深入源码,查看内核是如何分配物理内存并建立虚拟内存与物理内存之间映射关系的?
2、缺页中断
Linux 利用虚拟内存极大的扩展了程序地址空间,使得原来物理内存不能容下的程序也可以通过内存和硬盘之间的不断交换(把暂时不用的内存页交换到硬盘,把需要的内存页从硬盘读到内存)来赢得更多的内存,看起来就像物理内存被扩大了一样。事实上这个过程对程序是完全透明的,程序完全不用理会自己哪一部分、什么时候被交换进内存,一切都有内核的虚拟内存管理来完成。当程序启动的时候,Linux内核首先检查CPU的缓存和物理内存,如果数据已经在内存里就忽略,如果数据不在内存里就引起一个缺页中断(Page Fault),然后从硬盘读取缺页,并把缺页缓存到物理内存里。
缺页中断可分为主缺页中断(Major Page Fault)、次缺页中断(Minor Page Fault):
- 要从磁盘读取数据而产生的中断是主缺页中断;
- 数据已经被读入内存并被缓存起来,从内存缓存区中而不是直接从硬盘中读取数据而产生的中断是次缺页中断。
缺页异常被触发通常有以下几种情况:
- 程序设计的不当导致访问了进程的非法地址区域,SIGSEGV 信号杀死进程;
- 访问的地址是合法的,但是虚拟内存地址 address 还未被映射过,该地址还未分配物理页框,其在页表中对应的各级页目录项以及页表项都还是空的,进程首次访问时触发(接下来重点要分析这种情况);
- 内存不足的状态下,即虚拟内存地址 address 之前被映射过,但是映射的这块物理内存(进程的匿名页/文件页)被内核 swap out 到磁盘上;
- 虚拟内存地址 address 背后映射的物理内存还在,只是由于访问权限不够引起的缺页中断,比如:写时复制(COW)机制就属于这一种。
3、页表
页表(Page Table)是一种用于存储虚拟内存地址与物理内存地址映射关系的数据结构。在使用虚拟内存的系统中,每个进程都有自己的虚拟地址空间,而这些虚拟地址空间被分割成许多页(通常大小为4KB或更大),而不是一整块连续的内存。因此,当进程需要访问某个虚拟地址时,需要将其翻译成对应的物理地址,翻译过程就是通过页表来完成的。
页表的基本原理是将虚拟地址划分成一个页号和一个偏移量。页号用于在页表中查找对应的物理页帧号,而偏移量则用于计算该虚拟地址在物理页帧中的偏移量。通过这种方式,就可以将虚拟地址映射到物理地址,使得进程可以访问对应的内存区域。
页表一般由操作系统来维护,因为操作系统需要掌握虚拟地址和物理地址之间的映射关系。在使用MMU的硬件支持的系统中,当进程访问虚拟地址时,MMU会通过页表将虚拟地址转换为物理地址,并将访问指向正确的物理地址。这样,进程就可以在不知道自己真实物理地址的情况下访问内存。
Linux 内核 4 级页表模型如下:
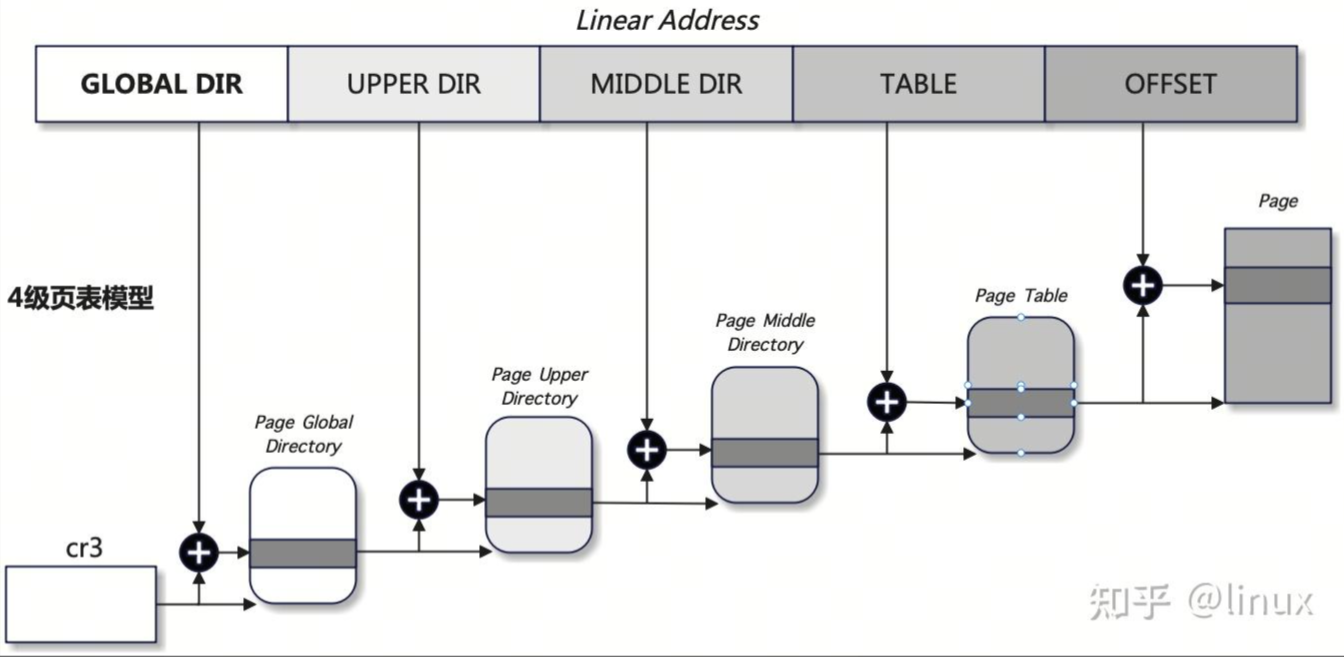
- 页全局目录:Page Global Directory,缩写 PGD,其包含若干页上级目录的地址;
- 页上级目录;Page Upper Directory,缩写 PUD,其包含若干页中间目录的地址;
- 页中间目录:Page Middle Directory,缩写 PMD,其包含若干页表的地址;
- 页表:Page Table,缩写 PT,其内部的每一个页表项 PTE 指向一个页框 Page。
Linux分别采用pgd_t、pmd_t、pud_t和pte_t四种数据结构来表示页全局目录项、页上级目录项、页中间目录项和页表项,这四种数据结构本质上都是无符号长整型unsigned long。
首先CR3寄存器(x86)里面存储的是pgd的基地址,用pgd基地址+对应偏移量可以在pgd中找到下一级页面pud的基地址。以此类推分别可以找到pmd,pte和物理页框page的基地址,然后使用物理页框的基地址+页内偏移可以得到最终的物理地址,并在最终的物理地址中找到了使用 sprintf 写入的数据,说明这个虚拟地址到物理地址的转换是正确的。
注意:用户态的页表结构,存储位置在 mm_struct 中。
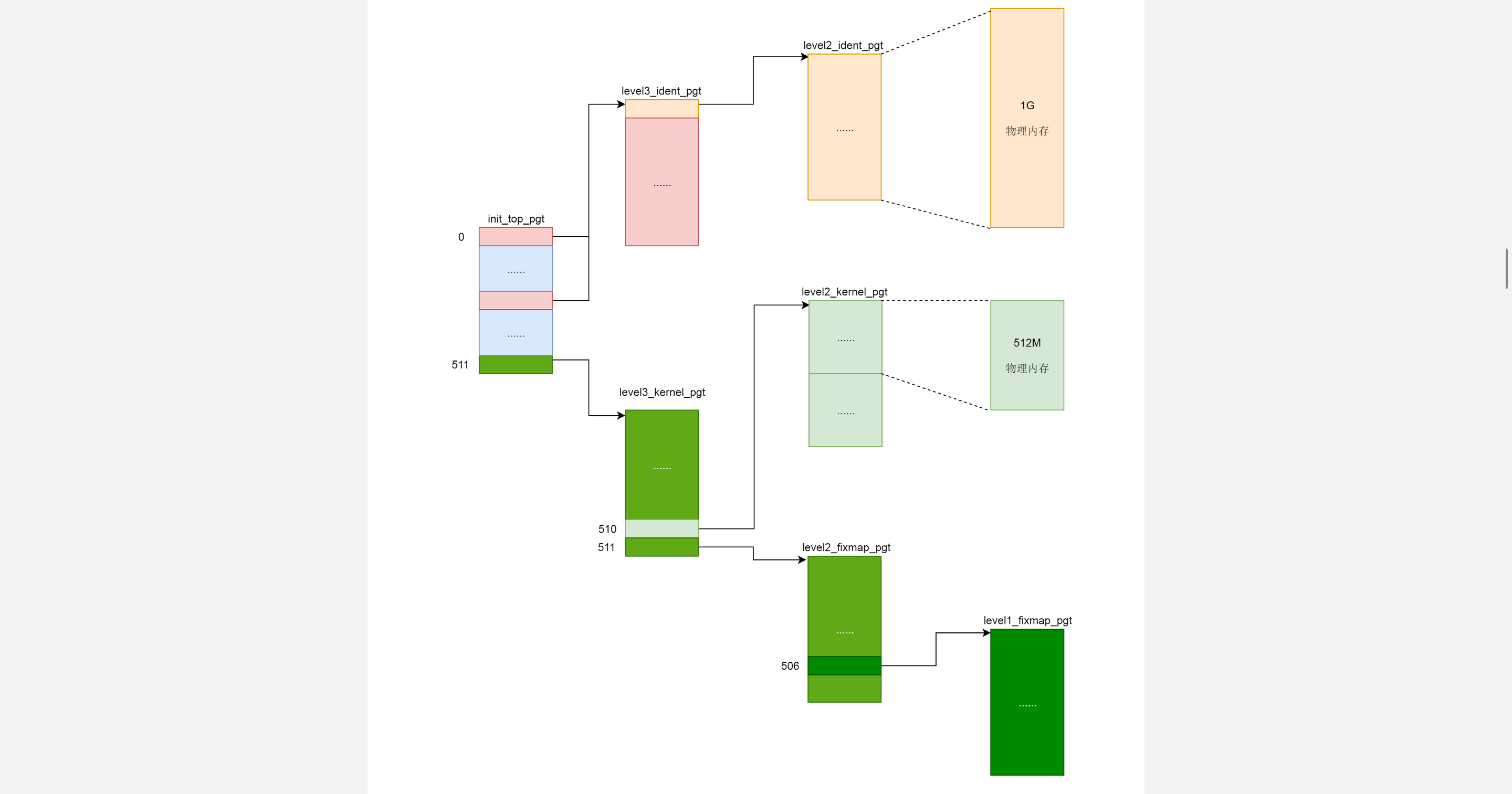
内核态页表:内核态页表, 系统初始化时就创建。
- swapper_pg_dir 指向内核顶级页目录 pgd
- xxx_ident/kernel/fixmap_pgt 分别是直接映射/内核代码/固定映射的xxx级页表目录
- 创建内核态页表
- - swapper_pg_dir 指向 init_top_pgt, 是 ELF 文件的全局变量, 因此再内存管理初始化之间就存在
- init_top_pgt 先初始化了三项
- 第一项指向 level3_ident_pgt (内核代码段的某个虚拟地址) 减去 __START_KERNEL_MAP (内核代码起始虚拟地址) 得到实际物理地址
- 第二项也是指向 level3_ident_pgt
- 第三项指向 level3_kernel_pgt 内核代码区
- init_top_pgt 先初始化了三项
- - swapper_pg_dir 指向 init_top_pgt, 是 ELF 文件的全局变量, 因此再内存管理初始化之间就存在
- 初始化各页表项, 指向下一集目录
- 页表覆盖范围较小, 内核代码 512MB, 直接映射区 1GB
- 内核态也定义 mm_struct 指向 swapper_pg_dir
- 初始化内核态页表, start_kernel→ setup_arch
- load_cr3(swapper_pg_dir) 并刷新 TLB
- 调用 init_mem_mapping→kernel_physical_mapping_init, 用 __va 将物理地址映射到虚拟地址, 再创建映射页表项
- CPU 在保护模式下访问虚拟地址都必须通过 cr3, 系统只能照做
- 在 load_cr3 之前, 通过 early_top_pgt 完成映射
4、mmap 提前分配物理内存
上一篇文章在分析 vm_mmap_pgoff 函数的核心流程时,其内部调用 do_mmap_pgoff 函数开始 mmap 内存映射,在进程虚拟内存空间中分配一段虚拟内存区域vma,并建立相关映射关系,其返回值ret表示映射的这段虚拟内存区域的起始地址。此时,如果调用mmap函数进行内存映射时,在flags参数中设置了MAP_POPULATE或者MAP_LOCKED标志位,Linux内核将调用mm_populate函数,为mmap刚刚映射出来的这段虚拟内存区域[ret , ret + populate]提前分配物理内存。
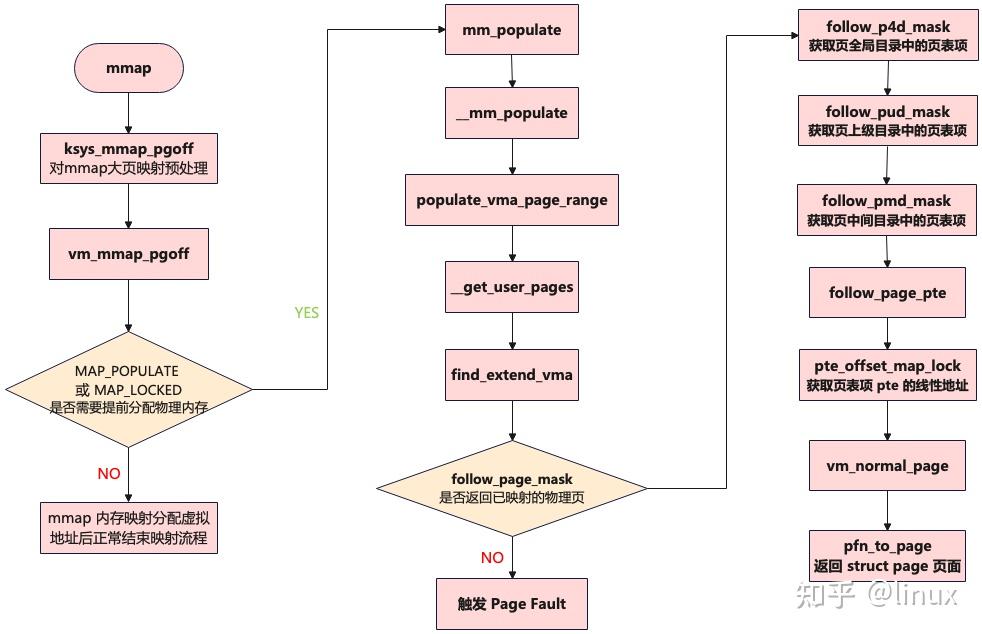
4.1 mm_populate 函数
/include/linux/mm.h
// __mm_populate 函数的实现是在 /mm/gup.c 文件中
extern int __mm_populate(unsigned long addr, unsigned long len,
int ignore_errors);
static inline void mm_populate(unsigned long addr, unsigned long len)
{
/* Ignore errors */
(void) __mm_populate(addr, len, 1);
}mm_populate 函数是一个内联函数,其内部调用 /mm/gup.c 文件内的 __mm_populate 函数。
extern:在 C 语言中, extern 关键字用于声明一个变量或者函数是在别的文件中定义的,或者说在别的文件中声明的。实现跨文件共享变量和函数声明,提高代码模块化和可维护性。使用 extern 时需确保正确链接,否则会导致编译或运行时错误。
4.2 __mm_populate 函数
/mm/gup.c
int __mm_populate(unsigned long start, unsigned long len, int ignore_errors)
{
struct mm_struct *mm = current->mm;
unsigned long end, nstart, nend;
struct vm_area_struct *vma = NULL;
int locked = 0;
long ret = 0;
end = start + len;
// 依次遍历进程地址空间中 [start , end] 这段虚拟内存范围的所有 vma
for (nstart = start; nstart < end; nstart = nend) {
if (!locked) {
locked = 1;
down_read(&mm->mmap_sem);
// 以 start 为起始地址,先通过 find_vma 查找 vma,如果没找到 vma,则退出循环
vma = find_vma(mm, nstart);
} else if (nstart >= vma->vm_end)
vma = vma->vm_next;
if (!vma || vma->vm_start >= end)
break;
/*
* Set [nstart; nend) to intersection of desired address
* range with the first VMA. Also, skip undesirable VMA types.
*/
nend = min(end, vma->vm_end);
if (vma->vm_flags & (VM_IO | VM_PFNMAP))
continue;
if (nstart < vma->vm_start)
nstart = vma->vm_start;
// 为这段地址范围内的所有 vma 分配物理内存
ret = populate_vma_page_range(vma, nstart, nend, &locked);
if (ret < 0) {
if (ignore_errors) {
ret = 0;
continue; /* continue at next VMA */
}
break;
}
// 继续为下一个 vma (如果有的话)分配物理内存
nend = nstart + ret * PAGE_SIZE;
ret = 0;
}
if (locked)
up_read(&mm->mmap_sem);
return ret; /* 0 or negative error code */
}__mm_populate函数的作用主要是在进程虚拟内存空间中,找出[ret, ret + populate]这段虚拟地址范围内的所有vma,并调用populate_vma_page_range函数为每一个vma填充物理内存。
4.3 populate_vma_page_range 函数
/mm/gup.c
long populate_vma_page_range(struct vm_area_struct *vma,
unsigned long start, unsigned long end, int *nonblocking)
{
struct mm_struct *mm = vma->vm_mm;
// 计算 vma 中包含的虚拟内存页个数,后续会按照 nr_pages 分配物理内存
unsigned long nr_pages = (end - start) / PAGE_SIZE;
int gup_flags;
/*做一些错误判断,start 和 end 地址必须以页面对齐,VM_BUG_ON_VMA 和 VM_BUG_ON_MM 宏需要
打开 CONFIG_DEBUG_VM 配置才会起作用,内存管理代码常常使用这些宏来做 debug。*/
VM_BUG_ON(start & ~PAGE_MASK);
VM_BUG_ON(end & ~PAGE_MASK);
VM_BUG_ON_VMA(start < vma->vm_start, vma);
VM_BUG_ON_VMA(end > vma->vm_end, vma);
VM_BUG_ON_MM(!rwsem_is_locked(&mm->mmap_sem), mm);
gup_flags = FOLL_TOUCH | FOLL_POPULATE | FOLL_MLOCK; // 设置分配掩码
if (vma->vm_flags & VM_LOCKONFAULT)
gup_flags &= ~FOLL_POPULATE;
/*
* We want to touch writable mappings with a write fault in order
* to break COW, except for shared mappings because these don't COW
* and we would not want to dirty them for nothing.
*/
// 如果 vma 的标志域 vm_flags 具有可写的属性 VM_WRITE,那么这里必须设置 FOLL_WRITE 标志位
if ((vma->vm_flags & (VM_WRITE | VM_SHARED)) == VM_WRITE)
gup_flags |= FOLL_WRITE;
/*
* We want mlock to succeed for regions that have any permissions
* other than PROT_NONE.
*/
if (vma->vm_flags & (VM_READ | VM_WRITE | VM_EXEC))
gup_flags |= FOLL_FORCE; // 如果 vm_flags 是可读、可写和可执行的,那么设置 FOLL_FORCE 标志位
// 循环遍历 vma 中的每一个虚拟内存页,依次为其分配物理内存页并建立映射关系
return __get_user_pages(current, mm, start, nr_pages, gup_flags,
NULL, NULL, nonblocking);
}populate_vma_page_range函数是在__mm_populate函数处理的基础上,为指定地址范围[start , end]内的每一个虚拟内存页,通过__get_user_pages函数为其分配物理内存页并建立映射关系。
4.4 __get_user_pages 函数
/mm/gup.c
/*参数说明:
@tsk: 表示进程的struct task_struct数据结构
@mm: 表示进程管理的struct mm_struct数据结构
@start: 表示进程地址空间 vma 的起始地址
@nr_pages: 表示需要分配多少个内存页面
@gup_flags: 分配掩码
@pages:表示物理页面的二级指针
@vmas: 进程地址空间 vma
@nonblocking: 表示是否等待 I/O 操作
*/
static long __get_user_pages(struct task_struct *tsk, struct mm_struct *mm,
unsigned long start, unsigned long nr_pages,
unsigned int gup_flags, struct page **pages,
struct vm_area_struct **vmas, int *nonblocking)
{
long ret = 0, i = 0;
struct vm_area_struct *vma = NULL;
struct follow_page_context ctx = { NULL };
if (!nr_pages)
return 0;
start = untagged_addr(start);
VM_BUG_ON(!!pages != !!(gup_flags & FOLL_GET));
/*
* If FOLL_FORCE is set then do not force a full fault as the hinting
* fault information is unrelated to the reference behaviour of a task
* using the address space
*/ // 如果设置了 FOLL_FORCE,则不强制执行完整错误,因为提示错误信息与使用地址空间的任务的引用行为无关
if (!(gup_flags & FOLL_FORCE))
gup_flags |= FOLL_NUMA;
do { // do...while 循环遍历 vma 中的每一个虚拟内存页
struct page *page;
unsigned int foll_flags = gup_flags;
unsigned int page_increm;
if (!vma || start >= vma->vm_end) {
// find_extend_vma 函数查找 vma,内部会调用 find_vma 查找 vma,如果 vma->vma_start 大于查找地址 start,
// 那将尝试去扩增 vma,把 vma->vm_start 边界扩大到 start。如果没有找到合适的 vma,
// 且 start 地址恰好在 gate_vma 中,那么使用 gate 页面,当然这种情况比较罕见。
vma = find_extend_vma(mm, start);
if (!vma && in_gate_area(mm, start)) {
ret = get_gate_page(mm, start & PAGE_MASK,
gup_flags, &vma,
pages ? &pages[i] : NULL);
if (ret)
goto out;
ctx.page_mask = 0;
goto next_page;
}
if (!vma || check_vma_flags(vma, gup_flags)) {
ret = -EFAULT;
goto out;
}
if (is_vm_hugetlb_page(vma)) {
if (should_force_cow_break(vma, foll_flags))
foll_flags |= FOLL_WRITE;
i = follow_hugetlb_page(mm, vma, pages, vmas,
&start, &nr_pages, i,
foll_flags, nonblocking);
continue;
}
}
if (should_force_cow_break(vma, foll_flags))
foll_flags |= FOLL_WRITE;
retry: // retry 标签的作用:整个 while 循环的目的是获取请求页队列中的每个页,然后反复操作直到满足构建所有内存映射的需求
/*
* If we have a pending SIGKILL, don't keep faulting pages and
* potentially allocating memory.
*/ // 如果当前进程收到一个 SKIGILL 信号,则不需要继续分配内存,直接报错退出
if (fatal_signal_pending(current)) {
ret = -ERESTARTSYS;
goto out;
}
// cond_resched()判断当前进程是否需要被调度,内核代码通常在while()循环中添加cond_resched()来优化系统的延迟
cond_resched();
// 调用 follow_page_mask 函数检查进程页表中 vma 中的虚拟页面是否已经分配了物理内存
page = follow_page_mask(vma, start, foll_flags, &ctx);
if (!page) {
// 如果虚拟内存页在进程页表中并没有物理内存页映射,那么这里调用 faultin_page
// 底层会调用到 handle_mm_fault 触发一个缺页中断,进入缺页处理流程来分配物理内存,并在页表中建立好映射关系
ret = faultin_page(tsk, vma, start, &foll_flags,
nonblocking);
switch (ret) {
case 0:
goto retry;
case -EBUSY:
ret = 0;
/* FALLTHRU */
case -EFAULT:
case -ENOMEM:
case -EHWPOISON:
goto out;
case -ENOENT:
goto next_page;
}
BUG();
} else if (PTR_ERR(page) == -EEXIST) {
goto next_page; // 存在适当的页表项,但没有相应的结构页
} else if (IS_ERR(page)) {
ret = PTR_ERR(page);
goto out;
}
if (pages) {
// 分配完页面后,pages 指针数组指向这些 page
pages[i] = page;
// 调用 flush_anon_page 和 flush_dcache_page 来刷新这些页面对应的 cache
flush_anon_page(vma, page, start);
flush_dcache_page(page);
ctx.page_mask = 0;
}
next_page:
if (vmas) { // 为下一次循环做准备
vmas[i] = vma;
ctx.page_mask = 0;
}
page_increm = 1 + (~(start >> PAGE_SHIFT) & ctx.page_mask);
if (page_increm > nr_pages)
page_increm = nr_pages;
i += page_increm;
start += page_increm * PAGE_SIZE;
nr_pages -= page_increm;
} while (nr_pages);
out:
if (ctx.pgmap)
put_dev_pagemap(ctx.pgmap);
return i ? i : ret;
}__get_user_pages&n
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3477
3477

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









