







 本文通过R语言分析不同品牌手机用户满意度的调查数据,运用因子分析探究影响满意度和忠诚度的关键因素,发现用户体验、象征价值和性价比对满意度与忠诚度有显著影响,建议手机厂商优化这三个方面以提高用户满意度和忠诚度。
本文通过R语言分析不同品牌手机用户满意度的调查数据,运用因子分析探究影响满意度和忠诚度的关键因素,发现用户体验、象征价值和性价比对满意度与忠诚度有显著影响,建议手机厂商优化这三个方面以提高用户满意度和忠诚度。
写在最前面
这是我今年R语言结课作业,如果你的老师是wqm,建议慎用,这里主打一个助人为乐。
当是课堂汇报的时候被批的劈头盖脸,但最后成绩给的蛮高的,给了满绩。

软件用到如下三个:



具体下载方式随便搜搜会有很多。
点击下方连接可以下载到ppt、论文还有数据(内容都做打码处理了)。代码在结尾有,那个文件地址你改改就能跑了。(数据很乱啊,也其实并不是真实数据,还有那个问卷结果图片也是批图批的,你可以自己真实发布一个问卷,自己能搞来数据还是蛮好的)
https://wwf.lanzouj.com/ibwVz1n7harg
一、背景介绍
随着市场竞争愈加激烈,企业越来越重视消费者的满意度和忠诚度,对此,手机厂商们推出了形形色色的手机供消费者选择,但是不同品牌的手机却有不同的定位和评价。究竟什么样的手机最得消费者喜爱?
本项目收集了不同品牌手机用户满意度的调查数据,尝试通过建立统计模型分析影响满意度和忠诚度的影响因素,并为手机厂商提升满意度提出建议。
二、数据来源与说明
通过问卷星设计调查问卷,该问卷共包含围绕用户体验、性价比、象征价值、满意度、忠诚度这五个方面设计了29个问题,通过发布社交平台及问卷星官方样本服务收集问卷,截止至撰写报告时共收集答卷431份。
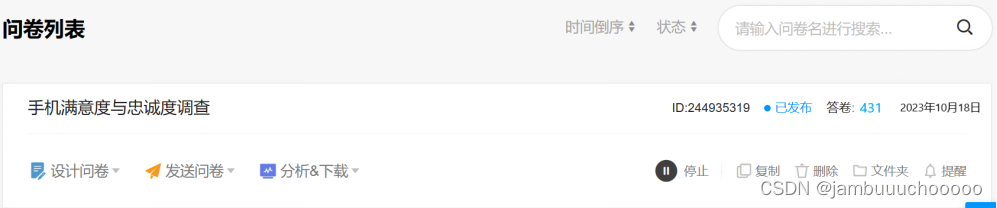 图1 问卷信息
图1 问卷信息

图2 问卷内容

图3 问卷发布
导出问卷结果,选取小米、华为、苹果、三星这4款具有代表性的手机品牌数据为实验数据,关于这4种品牌的有效数据共286条。
数据共包含286条记录,将问卷中每个问题归结为1个变量,总计29个变量,如上表所示。其中,除了手机品牌外,其余 28 个变量为取值范围在1-7之间的变量。

图4 导出问卷信息
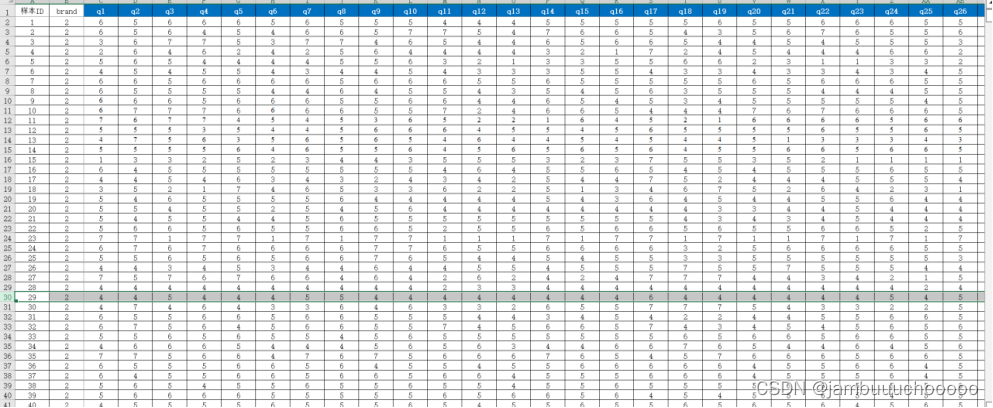
图5 整理数据
满意度因子,由总体满意度、预期满意度、相对满意度三个变量的取值求均值得到;忠诚度因子,由总体忠诚度、行为忠诚度、口碑忠诚度三个变量的取值求均值得到。其余变量有 22 个,可归纳为三个因子:用户体验因子,性价比因子,象征价值因子。
| 潜在因子 |
观测指标 |
| 用户体验 |
总体质量、外观造型、通话质量、功能齐全、安全耐用、电池续航时间、 维修方便、科技含量 |
| 性价比 |
价格满意、物有所值 |
| 象征价值 |
有面子、体现个性与形象、象征身份、功能体验、使用感觉、使用心情、 受青睐程度、身份认同感、价值观、受喜爱深度、购买明智、值得青睐 |
| 满意度 |
总体满意度、预期满意度、相对满意度 |
| 忠诚度 |
总体忠诚度、行为忠诚度、口碑忠诚度 |
表1 变量与因子关系说明图
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









