







 本文详细介绍了BeautifulSoup在解析HTML时遇到的问题,包括四种主要节点类型:Tag、NavigableString、BeautifulSoup和Comment。文章通过实例展示了遍历文档树、搜索文档树的方法,如find_all()、find_parent()等,并讨论了编码、解析器选择以及效率问题。此外,还提供了如何修改文档树和输出格式化的建议。
本文详细介绍了BeautifulSoup在解析HTML时遇到的问题,包括四种主要节点类型:Tag、NavigableString、BeautifulSoup和Comment。文章通过实例展示了遍历文档树、搜索文档树的方法,如find_all()、find_parent()等,并讨论了编码、解析器选择以及效率问题。此外,还提供了如何修改文档树和输出格式化的建议。
文章目录
遇到的问题
今天爬取一个新闻网站时,返回了一个的自闭标签,解析后为
<item><title>美丽乡村・吉林光东村:中俄朝边境的“老人村” 种稻旅游两不误</title><link/>http://www.chinanews.com/tp/hd2011/2018/12-05/855105.shtml<description></description><pubdate>2018-12-05 11:03:02</pubdate></item>
用item.link.text返回为空。为了解决该问题,查找资料后,发现用content[2]便可获得完整的链接。
随后,我又开始疑惑为何下标为2?因为正常不应该从0开始计数么?
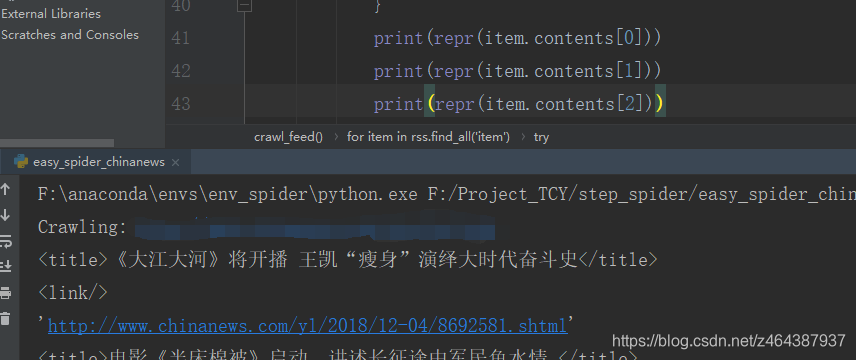
为了解决该问题,遂自行测试了以下代码,并根据python console中调试值窥探了soup的完整结构,由于结构复杂,查阅其官方文档后,给出以下总结。
html_doc = """
<html>
<head>
<title>The Dormouse's story</title>
</head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">
Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.
</p>
<p class="story">...</p>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_doc, 'html.parser')
// BeautifulSoup4解析该文件,文档树结构
BeautifulSoup
BeautifulSoup将复杂的HTML文档转换为一个复杂的树形结构,每个节点都是一个Python对象,对象可以归四类。Tag,NavigableString,BeautifulSoup,Comment
四类主要节点
Tag
主要两个属性:
{
name : 标签类别。如: u'b' , u'a' , u'head'...
attributes : 属性。如: <b class="boldset">有个"class"的属性,值为"boldset"。
其操作方法与字典相同,tag['class'] // u'boldset'
也可以直接获取属性。tag.attrs //{u'clas 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









