







本来想继续翻译simple Java的,不过看到The contract between hashCode() and equals()这篇觉得突然发现自己对HashMap背后的实现并不是很了解。查了一天的资料,自己也参照jdk6源码试着写了个简洁版的HashMap,这里总结下吧。
HashMap的结构
我们都明白,HashMap里面存放的是键值对,可以通过键(key)来获取到值(value),那么它背后实现的结构是什么呢?
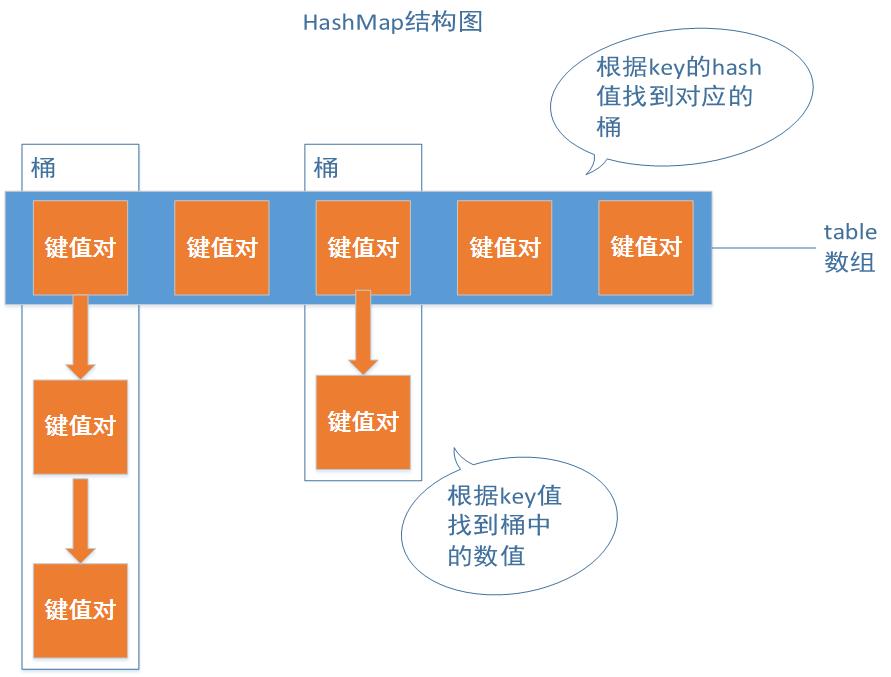
从图中可以知道,HashMap的键值对存放在一个table数组里,而数组中的键值对又指向下一个键值对依次形成了链表(也有一个称呼“桶”)。
这个结构咋看上去很怪异,我们分析下HashMap的取值方法的过程就明白了。
首先,我们要知道java是通过hash值以及equal()方法来保证HashMap的Key值不重复的。每次调用get(String key)这个方法来获取对应值时,有两步要走:
- 计算出key的hash值,对hash值进行特殊运算后,我们可以得到目标键值对所在桶在table数组中的下标
- 找到桶后,我们再迭代桶中的元素,对比key值是否相同(equal方法),若相同则返回键值对的value
也就说说,table数组的每个位置放的是“key的hash值计算出的索引”相同的键值对的集合。我们获得这个集合后还要继续比较key值才能找出真正要的值。
如何保证快速的取值?
知道HashMap的结构后,我们会对几个细节产生疑惑:
- 如何保证key的hash值生成的索引在一个数组的范围内的?因为初始化数组的时候必须设定数组的大小,总不能无穷大吧
- 因为
get(String key)时我们需要依次迭代数组,如何保证放入元素时它们距离的合理性?要是只有两个元素,一个table中的下标为0,另一个是100;或者两个计算出的下标都是100。这样显然会造成取值速度的大大降低 - 放入的元素多后,链表会增加,利用数组下标检索的优势会明显降低,HashMap是否会扩容?
下面我们带着这些问题来看代码
//根据hash值和table数组长度,获得下标
static int indexFor(int h, int length) {
return h & (length - 1);
}通过(key的hash值)和(数组长度-1)相与,我们得到了table数组中的下标,这个算法看似很简单,其实暗藏玄机:
- 保证了下标永远在数组范围内。因为0&1=0,所有A&B<=min(A,B)。例如5&15=5,16&15=0。(可以转换成二进制自己慢慢体会)
- 看源代码我们会发现,数组的长度都是设置的2的指数。HashMap默认的数组大小是16。原因是2^n-1得到的二进制为全1,相与产生相同值的几率会降低。例如1000(8)&1110(14)=1000,而1001(9)&1110(14)=1000,产生了重复。而1000(8)&1111(15)=1000,而1001(9)&1111(15)=1001。
上面已经分析过取值的过程,我们再结合代码来看下放值的过程,其实差不多
public V put(K key, V value) {
int hash = hash(key.hashCode());
// 根据key的hash值计算出应放入的table数组下标
int index = indexFor(hash, table.length);
// 找到table数组中对应的下标的桶,迭代桶中的键值对元素
for (Entry<K, V> e = table[index]; e != null; e = e.next) {
Object ek = e.key;
// 如果该元素的key值和要放入元素的key值相同,覆盖该元素的value值
if (e.hash == hash && (key == ek || key.equals(ek))) {
V oldValue = e.value;
e.value = value;
return oldValue;
}
}
// 如果没有找到相同key值的元素,新放入这个元素进map
addEntry(hash, key, value, index);
return null;
}先通过key的hash值获得table数组下标,再迭代该下标所在的链表中,如果存在key值相等的,则覆盖value,不存在则新添一个键值对放入table。
我们来看下新添的过程:
void addEntry(int hash, K key, V value, int bucketIndex) {
// 获取对应下标的桶的头节点
Entry<K, V> e = table[bucketIndex];
// 设置头节点为新的元素,并设定新元素的next为旧头节点
table[bucketIndex] = new Entry<K, V>(key, value, hash, e);
// 如果map中的元素>容量*负载因子,进行数组空间扩容
if (size++ >= (capacity * loadFactor))
//每次扩大为原来容量的两倍
reSize(2 * table.length);
}
/**
* table数组的扩容
*/
void reSize(int newCapacity) {
Entry[] oldTable = table;
// 创建新容量的table数组
Entry[] newTable = new Entry[newCapacity];
// 把旧talbe数组中的元素重新放入新table数组
transfer(newTable);
// 设置map的table为新数组
table = newTable;
// 更新map的容量
capacity = newCapacity;
}由于我们已经知道了数组下标,所以添加的过程就是在下标所在的链表上添加结点而已。通过代码我们知道,每次新添的结点都是头结点,它指向旧头结点。
值得注意的是,添加后会进行数组扩容的判断。如果map中的元素>数组长度*负载因子(默认为0.75),则进行数组空间扩容。扩容会极大的耗费时间,所以我们要尽量的避免扩容,即初始化HashMap时指定合理的容量大小(table数组长度)
HashMap的使用优化
前面已经提到,HashMap的扩容会带来极大的性能消耗(要重新创建新的table数组并把旧元素重新放入),那么学会创建合理容量和负载因子的HashMap会给我们带来很大效率性能的提高。
容量的确定
如果我确定自己要使用HashMap存放1000个元素,那显然不能创建默认容量(16)的HashMap,不然会扩容7次(16->32->64->128->256->512->1024->2048),啊,那简直是噩梦。
那设置多少呢?既然我们已经很确定将存放的元素为1000左右,那把容量设置成1001不就好了吗?还可以多一个保险哈哈。但显然不行,因为还有负载因子,当size>=容量*负载因子时才会扩容。这里默认为0.75,也就意味1000*0.75=750,要扩容到2048*0.75=1536时才行。
负载因子的确定
现在,我们再来谈谈负载因子。
如果负载因子设置的低,那么扩容会更加容易,hash表(table数组)的空间会变大。但同样,下标碰撞的几率降低,迭代链表的几率降低,检索速度提高。
如果负载因子设置的高,则hash表空间减少。但下标碰撞几率增加,迭代链表几率提高,检索速度降低。
默认的0.75是时间和空间的一种折中。
最后,补充equal()和hashCode
先看一下equal()和hashCode的设计原则
1. 如果两个对象有同样的hash code,那它们不一定equal()相等
2. 如果两个对象equal()相等,那它们一定有相同的hash code
为什么这么设计?试想两个对象equal返回true,但hashCode却不相等那不很怪异吗?
所以key值的判重是同时根据equal()方法和hashCode的,改变某对象key值的判重时,必须重写两个方法。来确保equal()相等时,hashCode也相等
最后,放一下参照源码实现的HashMap代码:
/**
* 手写HashMap,实现了put和get方法,可以自动扩容
*
* @param <K>
* @param <V>
* @author wsz
*/
public class MyHashMap<K, V> {
/** 默认的table数组大小 */
static final int DEFAULTCAPACITY = 2;
int capacity;
/** 默认的负载因子 */
final float loadFactor;
/** 键值对桶数组 */
Entry[] table;
/** 放入的键值对数目 */
int size;
/**
* 默认构造方法
*/
public MyHashMap() {
capacity = DEFAULTCAPACITY;
this.table = new Entry[capacity];
this.loadFactor = 0.75f;
this.size = 0;
}
/**
* 指定table大小和负载因子的构造方法
*/
public MyHashMap(int capacity, float loadFactor) {
this.capacity = capacity;
this.table = new Entry[capacity];
this.loadFactor = loadFactor;
this.size = 0;
}
/**
* 获取哈希值
*/
static int hash(int h) {
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
/**
* 根据对象的哈希值和table数组长度,计算出对象在table数组中的下标
*
* @param h
* 对象的哈希值
* @param length
* table数组长度
* @return 计算出的table数组中的下标
*/
static int indexFor(int h, int length) {
// 源代码中一直保持length为2的倍数,这样可使算出的index相同的几率较小
return h & (length - 1);
}
/**
* 获取map中key值对应的value
*/
public V get(K key) {
int hash = hash(key.hashCode());
// 根据key的hash值计算出应放入的table数组下标
int index = indexFor(hash, table.length);
// 找到table数组中对应的下标的桶,迭代桶中的键值对元素
for (Entry<K, V> e = table[index]; e != null; e = e.next) {
Object ek = e.key;
// 如果该元素的key值和要放入元素的key值相同,返回value值
if (e.hash == hash && (key == ek || key.equals(ek))) {
return e.value;
}
}
// 没有找到,返回Null
return null;
}
/**
* 向map中放值
*/
public V put(K key, V value) {
int hash = hash(key.hashCode());
// 根据key的hash值计算出应放入的table数组下标
int index = indexFor(hash, table.length);
// 找到table数组中对应的下标的桶,迭代桶中的键值对元素
for (Entry<K, V> e = table[index]; e != null; e = e.next) {
Object ek = e.key;
// 如果该元素的key值和要放入元素的key值相同,覆盖该元素的value值
if (e.hash == hash && (key == ek || key.equals(ek))) {
V oldValue = e.value;
e.value = value;
return oldValue;
}
}
// 如果没有找到相同key值的元素,新放入这个元素进map
addEntry(hash, key, value, index);
return null;
}
/**
* 将键值对放入table中,若元素个数>=capacity * loadFactor,进行table数组的扩容
*/
void addEntry(int hash, K key, V value, int bucketIndex) {
// 获取对应下标的桶的头节点
Entry<K, V> e = table[bucketIndex];
// 设置头节点为新的元素,并设定新元素的next为旧头节点
table[bucketIndex] = new Entry<K, V>(key, value, hash, e);
// 如果map中的元素>容量*负载因子,进行数组空间扩容
if (size++ >= (capacity * loadFactor))
reSize(2 * table.length);
}
/**
* table数组的扩容
*/
void reSize(int newCapacity) {
Entry[] oldTable = table;
// 创建新容量的table数组
Entry[] newTable = new Entry[newCapacity];
// 把旧talbe数组中的元素重新放入新table数组
transfer(newTable);
// 设置map的table为新数组
table = newTable;
// 更新map的容量
capacity = newCapacity;
}
/**
* 把旧table数组中的元素放入扩容后的table数组中
*/
void transfer(Entry[] newTable) {
Entry[] oldTable = table;
int newCapacity = newTable.length;
// 迭代旧table中的桶
for (int j = 0; j < oldTable.length; j++) {
// 旧桶的第一个节点
Entry<K, V> e = oldTable[j];
if (e != null) {
oldTable[j] = null;
// 迭代旧桶,把旧桶中的元素放入新数组
do {
// 保留下旧节点的下一个节点
Entry<K, V> next = e.next;
// 获取扩容后该节点的数组下标
int i = indexFor(e.hash, newCapacity);
// 设置该节点的下个节点指向新桶的头节点
e.next = newTable[i];
// 设置新桶的第一个节点为该节点
newTable[i] = e;
// e为旧桶的下一个节点
e = next;
} while (e != null);
}
}
}
public static void main(String[] args) {
MyHashMap<String, String> map = new MyHashMap<String, String>();
map.put("a", "wsza");
map.put("b", "wszb");
map.put("c", "wszc");
map.put("a", "wszaa");
System.out.println(map.get("a"));
System.out.println(map.get("b"));
System.out.println(map.get("c"));
System.out.println(map.capacity);
}
/**
* 键值对类,由于每个类有指向下一个类的引用,所以也称为"桶"(可以看作键值对的链表)
*
* @param <K>
* key值类型
* @param <V>
* value值类型
* @author wsz
*/
static class Entry<K, V> {
final K key;
V value;
final int hash; // key值的hash值
Entry<K, V> next; // 下一个键值对
public Entry(K key, V value, int hash, Entry<K, V> next) {
this.key = key;
this.value = value;
this.hash = hash;
this.next = next;
}
}
}/**output:
wszaa
wszb
wszc
4
*/

















 339
339

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









