







动态hash方法之一
本文将介绍三种动态hash方法。
散列是一个非常有用的、非常基础的数据结构,在数据的查找方面尤其重要,应用的非常广泛。然而,任何事物都有两面性,散列也存在缺点,即数据的局部集中性会使散列的性能急剧下降,且越集中,性能越低。
数据集中,即搜索键在通过hash函数运算后,得到同一个结果,指向同一个桶,这时便产生了数据冲突。
通常解决数据冲突的方法有:拉链法(open hashing)和开地址法(open addressing)。拉链法我们用的非常多,即存在冲突时,简单的将元素链在当前桶的最后元素的尾部。开放地址法有线性探测再散列、二次线性探测再散列、再hash等方法。
以上介绍的解决冲突的方法,存在一个前提:hash表(又称散列表)的桶的数目保持不变,即hash表在初始化时指定一个数,以后在使用的过程中,只允许在其中添加、删除、查找元素等操作,而不允许改变桶的数目。
在实际的应用中,当hash表较小,元素个数不多时,采用以上方法完全可以应付。但是,一旦元素较多,或数据存在一定的偏斜性(数据集中分布在某个桶上)时,以上方法不足以解决这一问题。我们引入一种称之为动态散列的方法:在hash表的元素增长的同时,动态的调整hash桶的数目。
动态hash不需要对hash表中所有元素进行再次插入操作(重组),而是在原来基础上,进行动态的桶扩展。有多种方法可以实现:多hash表、可扩展的动态散列和线性散列,下面分别介绍之,方法由简单到复杂。
多hash表:顾名思义,即采用多个hash表的方式扩展原hash表。这种方式不复杂,且理解起来也较简单,是三者中最简单的一种。
通常,当一个hash表冲突较多时,需要考虑采用动态hash方式,来减小后续操作继续在该桶上的冲突,减轻该桶负担,最简单且最容易想到的就是采用多hash表的方式。如下图,有一个简单的hash结构:

简单起见,假定(1)hash函数采用模5,即hash(i)=i%5;(2)每个桶中最多只可放4个元素。
在以上基础上,向hash表中插入5,由于桶a存在空闲,直接存入。接着向hash表插入值3,由于d桶中已满,无空闲位置,此时在建立一个hash表,结果如下图

通过图示,一目了然,原来的一个hash表,变为现在的两个hash表。如需要,该“分裂”可继续进行。
需要注意的是:采用这种方式,多个hash表公用一个hash函数,且目录项的个数也随之增多,分别指向对应的桶。实际上,这时存在两个不同的目录项,分别指向各自的桶。
执行插入、查找、删除操作时,均需先求得hash值x。插入时,得到当前的hash表的个数,并分别取得各个目录项的x位置上的目录项,若其中某个项指向的桶存在空闲位置,则插入之。同时,在插入时,可保持多个hash表在某个目录项上桶中元素的个数近似相等。若不存在空闲位置,则简单的进行“分裂”,新建一个hash表,如上图所示。
查找时,由于某个记录值可能存在当前hash结构的多个表中,因此需同时在多个目录项的同一位置上进行查找操作,等待所有的查找结束后,方可判定该元素是否存在。由于该种结构需进行多次查找,当表元素非常多时,为提高效率,在多处理器上可采用多线程,并发执行查找操作。
删除操作,与上述过程基本类似,不赘述。需要注意的是,若删除操作导致某个hash表元素为空,这时可将该表从结构中剔除。
这种解决hash冲突的方法,优点是:思想简单,实现起来也不复杂。由于一存在桶满的情况就另分配一个hash表,因此占用内存空间较大;当数据较集中时,桶利用率会很低。
可扩展的动态散列:引入一个仅存储桶指针的目录数组,用翻倍的目录项数来取代翻倍的桶的数目,且每次只分裂有溢出的桶,从而减小翻倍的代价。这里需要几个参数:H表示hash函数、D表示全局位深度、L表示桶的局部深度。还是来看个例子,参照这个图,你会更明了。

图中,每个目录项有一个指向桶的指针,为介绍方便,我们假定(1)每个桶只可存放4个元素;(2)每个桶中存放的元素j*表示H(i)=j,为方便起见,只图示了j的值,并以’ *’标注。当前有4个目录项,目录项的编号从00~11,用两个位即可表示所有的目录项,因此全局位深度D=2;所有的桶目前最多只可放4个元素,因此所有桶的局部位深度为L=2。
在上图的基础上,我们插入数据d1和d2,且假定,经过hash函数求值后分别得到H(d1)=13;H(d2)=20。因为13=1101,因全局位深度为2,故选用最后两位01,找到编号为01的目录项,从而找到其指向的桶b,由于该桶还有空间,可直接存入数据。因20=10100,全局位深度为2,选用最后两位00,选定第一个目录项,这时我们发现其指向的桶a中已经放满了数据,于是该桶进行分裂,分裂的桶的局部位深度从2变为3,若这个数据比全局位深度还大,则全局位深度也等于该数,并进行目录项的翻倍操作。分裂的桶中的所有数据,需进行局部的重组。下图列出了分裂后的hash表的情况。

对a桶进行分裂后,得到两个桶a1和a2,其局部深度加1。由于局部深度大于全局位深度,因此目录数组进行翻倍,从4变为8,且目录编号扩展一位(如图)。桶a分裂为a1桶和a2桶,分别设置指针。对原来a桶中的所有元素进行重组操作,32和16的后三位均为000,于是放入a1桶,4和12的后三位均为100,于是放入a2桶。对目录项数组中其它未赋值的目录项,进行赋值,使指针指向对应的桶。至此,插入操作完毕。可以看到,有多个目录指向同一个桶。
对于查找操作,步骤如下:
1、对于需要查找的x,hash(x) = y
2、根据当前hash表的全局位深度,决定对y取其后D位,位数不够用0填充
3、找到对应的目录项,从而找到对应的桶,在桶中逐一进行比较。
对于删除操作,和查找操作类似,先定位元素,删除之。若删除时发现桶为空,则可以考虑将该桶与其兄弟桶进行合并,并使局部位深度减1。
可扩展散列的好处在于可动态进行桶的增长,且增长的同时,用目录项的翻倍的较小的代价换取桶数翻倍的传统做法,效率得到提升。然而,它也存在一定问题:(1)当散列的数据分布不均或偏斜较大时,会使得目录项的数目很大,数据桶的利用率很低;(2)目录的增长速度,是指数级增长,扩展较快。
动态hash思想方法之二
======》接动态hash方法之一
动态hash方法之二
线性散列:动态hash常用的另一种方法为线性散列,它能随数据的插入和删除,适当的对hash桶数进行调整,与可扩展散列相比,线性散列不需要存放数据桶指针的专门目录项,且能更自然的处理数据桶已满的情况,允许更灵活的选择桶分裂的时机,因此实现起来相比前两种方法要复杂。
理解线性散列,需要引入“轮转分裂进化”的概念,各个桶轮流进行分裂,当一轮分裂完成之后,进入下一轮分裂,于是分裂将从头开始。用Level表示当前的“轮数”,其值从0开始。假定hash表初始桶数为N(要求N是2的幂次方),则值logN(以2为底)是指用于表示N个数需要的最少二进制位数,用d0表示,即d0=logN。
以上提到,用Level表示当前轮数,则每轮的初始桶数为N*2^Level个(2^Level表示2的Level次方)。例如当进行第0轮时,level值为0,则初始桶数为N*2^0=N。桶将按桶编号从小到大的顺序,依次发生分裂,一次分裂一个桶,这里我们使用Next指向下次将被分裂的桶。
每次桶分裂的条件可灵活选择,例如,可设置一个桶的填充因子r(r<1),当桶中记录数达到该值时进行分裂;也可选择当桶满时才进行分裂。
需要注意的时,每次发生分裂的桶总是由Next决定,与当前值被插入的桶已满或溢出无关。为处理溢出情况,可引入溢出页解决。话不多说,先来看一个图示:

假定初始时,数据分布如上,hash函数为h(x)。桶数N=4,轮数Level为0,Next处于0位置;采用“发生溢出分裂”作为触发分裂的条件。此时d=logN=2,即使用两个二进位可表示桶的全部编号。
简单解释一下,为什么32*、25*、18*分别位于第一、二、三个桶中。因为h(x)=32=100000,取最后两个二进制位00,对应桶编号00;h(y)=25=11001,取最后两个二进制位01,对应桶编号01;h(z)=18=10010,最后两位对应桶编号10。
接下来,向以上hash表中插入两个新项h(x1)=43和h(x2)=37,插入结果如下图所示:

我们来分析一下。当插入h(x1)=43=101011时,d值为2,因此取末尾两个二进制位,应插入11桶。由于该桶已满,故应增加溢出页,并将43*插入该溢出页内。由于触发了桶分裂,因此在Next=0位置上(注意不是在11桶上),进行桶分裂,产生00桶的映像桶,映像桶的编号计算方式为N+Next=4+0=100,且将原来桶内的所有元素进行重新分配,Next值移向下一个桶。
当插入h(x2)=37=100101时,d值仍为2,取末尾两个二进制位,应插入01桶,该桶中有空余空间,直接插入。
分析到这里,读者应该基本了解了线性散列的分裂方式。我们发现,桶分裂是依次进行的,且后续产生的映像桶一定位于上一次产生的映像桶之后。
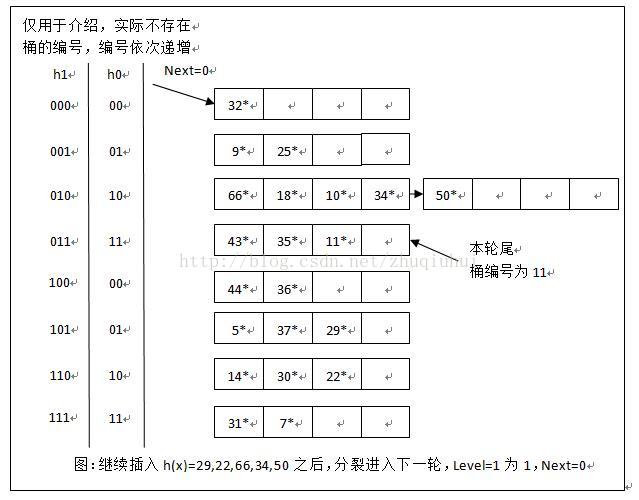
读者不妨继续尝试插入h(x)=29,22,66,34,50,情况如下图所示,这里不再详细分析。
线性散列的查找操作,例如要查询h(x)=18,32,44。假定查询时,hash表状态为N=4,Level=0,Next=1,因此d值为2。
(1) 查找h(x)=18=10010,取末两位10,由于10位于Next=1和N=4之间,对用桶还未进行分裂,直接取10作为桶编号,在该桶中进行查找。
(2) 查找h(x)=32=10000,取末两位00,由于00不在Next=1和N=4之间,表示该桶已经分裂,再向前取一位,因此桶编号为000,在该桶中进行查找。
(3) 查找h(x)=44=101100,取末两位00,由于00不在Next=1和N=4之间,表示该桶已经分裂,再向前取一位,因此桶编号为100,在该桶中进行查找。
线性散列的删除操作是插入操作的逆操作,若溢出块为空,则可释放。若删除导致某个桶元素变空,则Next指向上一个桶。当Next减少到0,且最后一个桶也是空时,则Next指向N/2 -1的位置,同时Level值减1。
线性散列比可扩展动态散列更灵活,且不需要存放数据桶指针的专门目录项,节省了空间;但如果数据散列后分布不均匀,导致的问题可能会比可扩展散列还严重。
至此,三种动态散列方式介绍完毕。
附:对于多hash表和可扩展的动态散列,桶内部的组织,可采用(1)链式方法,一个元素一个元素的链接起来,则上例中的4表示最多只能链接4个这样的元素;也可采用(2)块方式,每个块中可放若干个元素,块与块之间链接起来,则上例中的4表示最多只能链接4个这样的块。
转自:http://blog.sina.com.cn/s/blog_5e4516af01019frj.html
参考书籍:高级数据库系统及其应用,谢兴生主编,清华大学出版社(北京),2010.1














 1918
1918











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









