







我们知道,JVM在进行垃圾收集时,需要先标记所有可达对象,然后再清除不可达对象,释放内存空间。那么,如何快速的找到所有可达对象呢?
最简单粗暴的实现,就是每次进行垃圾收集时,都对整个堆中的所有对象进行扫描,找到所有存活对象。逻辑是简单,但性能比较差。
简单粗暴的实现方式,通常都是不可取的。那JVM是如何实现快速标记可达对象的?
答案是GC Roots。
GC Roots是垃圾收集器寻找可达对象的起点,通过这些起始引用,可以快速的遍历出存活对象。GC Roots最常见的是静态引用和堆栈的局部引用变量。然而,这不是我们这讲的重点:)
现代JVM,堆空间通常被划分为新生代和老年代。由于新生代的垃圾收集通常很频繁,如果老年代对象引用了新生代的对象,那么,需要跟踪从老年代到新生代的所有引用,从而避免每次YGC时扫描整个老年代,减少开销。
对于HotSpot JVM,使用了卡标记(Card Marking)技术来解决老年代到新生代的引用问题。具体是,使用卡表(Card Table)和写屏障(Write Barrier)来进行标记并加快对GC Roots的扫描。
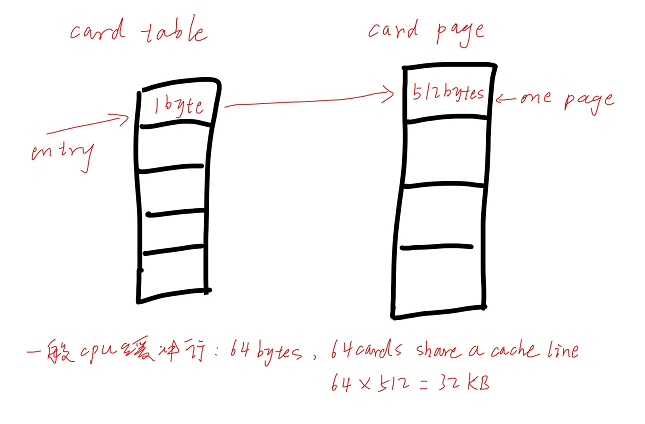
卡表(Card Table)
基于卡表(Card Table)的设计,通常将堆空间划分为一系列2次幂大小的卡页(Card Page)。
卡表(Card Table),用于标记卡页的状态,每个卡表项对应一个卡页。
HotSpot JVM的卡页(Card Page)大小为512字节,卡表(Card Table)被实现为一个简单的字节数组,即卡表的每个标记项为1个字节。
当对一个对象引用进行写操作时(对象引用改变),写屏障逻辑将会标记对象所在的卡页为dirty。
OpenJDK/Oracle 1.6/1.7/1.8 JVM默认的卡标记简化逻辑如下:
CARD_TABLE [this address >> 9] = 0;首先,计算对象引用所在卡页的卡表索引号。将地址右移9位,相当于用地址除以512(2的9次方)。可以这么理解,假设卡表卡页的起始地址为0,那么卡表项0、1、2对应的卡页起始地址分别为0、512、1024(卡表项索引号乘以卡页512字节)。
其次,通过卡表索引号,设置对应卡标识为dirty。
带来的2个问题
1.无条件写屏障带来的性能开销
每次对引用的更新,无论是否更新了老年代对新生代对象的引用,都会进行一次写屏障操作。显然,这会增加一些额外的开销。但是,与YGC时扫描整个老年代相比较,这个开销就低得多了。
不过,在高并发环境下,写屏障又带来了虚共享(false sharing)问题。
2.高并发下虚共享带来的性能开销
在高并发情况下,频繁的写屏障很容易发生虚共享(false sharing),从而带来性能开销。
假设CPU缓存行大小为64字节,由于一个卡表项占1个字节,这意味着,64个卡表项将共享同一个缓存行。
HotSpot每个卡页为512字节,那么一个缓存行将对应64个卡页一共64*512=32KB。
如果不同线程对对象引用的更新操作,恰好位于同一个32KB区域内,这将导致同时更新卡表的同一个缓存行,从而造成缓存行的写回、无效化或者同步操作,间接影响程序性能。
一个简单的解决方案,就是不采用无条件的写屏障,而是先检查卡表标记,只有当该卡表项未被标记过才将其标记为dirty。
这就是JDK 7中引入的解决方法,引入了一个新的JVM参数-XX:+UseCondCardMark,在执行写屏障之前,先简单的做一下判断。如果卡页已被标识过,则不再进行标识。
简单理解如下:
if (CARD_TABLE [this address >> 9] != 0)
CARD_TABLE [this address >> 9] = 0;与原来的实现相比,只是简单的增加了一个判断操作。
虽然开启-XX:+UseCondCardMark之后多了一些判断开销,但是却可以避免在高并发情况下可能发生的并发写卡表问题。通过减少并发写操作,进而避免出现虚共享问题(false sharing)。
也用于CMS GC
CMS在并发标记阶段,应用线程和GC线程是并发执行的,因此可能产生新的对象或对象关系发生变化,例如:
- 新生代的对象晋升到老年代;
- 直接在老年代分配对象;
- 老年代对象的引用关系发生变更;
- 等等。
对于这些对象,需要重新标记以防止被遗漏。为了提高重新标记的效率,并发标记阶段会把这些发生变化的对象所在的Card标识为Dirty,这样后续阶段就只需要扫描这些Dirty Card的对象,从而避免扫描整个老年代。
https://ezlippi.com/blog/2018/01/jvm-card-table-turning.html
网上关于JVM调优的文章很多,这篇文章主要介绍JVM里Card Table的作用。我们知道JVM GC可以分为MinorGC、MajorGC和FullGC,对于Mirnor GC来讲它的耗时主要由两个因素决定:
- 复制活跃对象的时间
- 扫描card table(老年代对象引用新生代对象)的时间
Java虚拟机用了一个叫做CardTable(卡表)的数据结构来标记老年代的某一块内存区域中的对象是否持有新生代对象的引用,卡表的数量取决于老年代的大小和每张卡对应的内存大小,每张卡在卡表中对应一个比特位,当老年代中的某个对象持有了新生代对象的引用时,JVM就把这个对象对应的Card所在的位置标记为dirty(bit位设置为1),这样在Minor GC时就不用扫描整个老年代,而是扫描Card为Dirty对应的那些内存区域。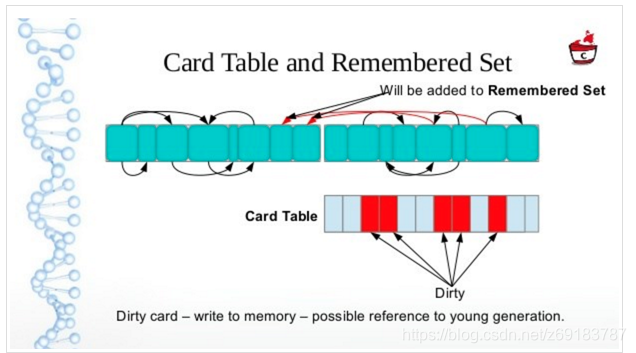
这样子可以提高效率减少MinorGC的停顿时间。
在JVM中,一个Card的大小是512字节,在多个线程并行收集时,JVM通过ParGCCardsPerStrideChunk参数设置每个线程每次扫描的Card数量,默认是256,相当于是把老年代分成许多strides,每个线程每次扫描一个stride,每个stride大小为512*256 = 128K,如果你的老年代大小为4G,那总共有4G/128K=32K个Strides。多线程在扫描这么多的strides时就涉及到调度和分配的问题,stride数量太多就会导致线程在stride之间切换的开销增加,进而导致GC暂停时间增长。因此JVM提供了ParGCCardsPerStrideChunk这个参数来配置每个stride对应的card数量,这个数量要根据实际的业务场景进行调优,网上一般流传3个魔术数字:32768、4K和8K。
-XX:+UnlockDiagnosticVMOptions
-XX:ParGCCardsPerStrideChunk=4096这个值不能设置的太大,因为GC线程需要扫描这个stride中老年代对象持有的新生代对象的引用,如果只有少量引用新生代的对象那就导致浪费了很多时间在根本不需要扫描的对象上。
参考文档:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









