









Description
As the new term comes, the Ignatius Train Station is very busy nowadays. A lot of student want to get back to school by train(because the trains in the Ignatius Train Station is the fastest all over the world ^v^). But here comes a problem, there is only one railway where all the trains stop. So all the trains come in from one side and get out from the other side. For this problem, if train A gets into the railway first, and then train B gets into the railway before train A leaves, train A can't leave until train B leaves. The pictures below figure out the problem. Now the problem for you is, there are at most 9 trains in the station, all the trains has an ID(numbered from 1 to n), the trains get into the railway in an order O1, your task is to determine whether the trains can get out in an order O2.
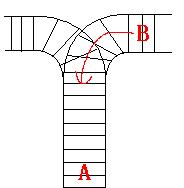
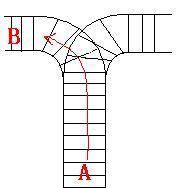
Input
The input contains several test cases. Each test case consists of an integer, the number of trains, and two strings, the order of the trains come in:O1, and the order of the trains leave:O2. The input is terminated by the end of file. More details in the Sample Input.
Output
The output contains a string "No." if you can't exchange O2 to O1, or you should output a line contains "Yes.", and then output your way in exchanging the order(you should output "in" for a train getting into the railway, and "out" for a train getting out of the railway). Print a line contains "FINISH" after each test case. More details in the Sample Output.
Sample Input
3 123 321
3 123 312
Sample Output
Yes.
in
in
in
out
out
out
FINISH
No.
FINISH
Hint
Hint For the first Sample Input, we let train 1 get in, then train 2 and train 3. So now train 3 is at the top of the railway, so train 3 can leave first, then train 2 and train 1. In the second Sample input, we should let train 3 leave first, so we have to let train 1 get in, then train 2 and train 3. Now we can let train 3 leave. But after that we can't let train 1 leave before train 2, because train 2 is at the top of the railway at the moment. So we output "No."
#include<stdio.h>
#include<stack>
#include<iostream>
#include<algorithm>
#include<string.h>
#include<queue>
using namespace std;
int main()
{
int k,i,u,h;
while(scanf("%d",&k)!=EOF)
{ int cd[11]={-1};
char a[10],b[10];
stack<int> q;
queue<int> m;
queue<int> n;
scanf("%s",a);
scanf("%s",b);
for(i=0;i<k;i++)
{
m.push(a[i]-'0');
n.push(b[i]-'0');
}
u=0;h=0;
while(1)
{
if(q.size()==0)
{
if(m.front()==n.front())
{
m.pop();
n.pop();
cd[u++]=0;
cd[u++]=1;
}
else if(m.front()!=n.front())
{
q.push(m.front());
cd[u++]=0;
m.pop();
}
}
else if(q.size()!=0)
{
if(q.top()==n.front())
{
cd[u++]=1;
q.pop();
n.pop();
}
else if(q.top()!=n.front())
{
q.push(m.front());
cd[u++]=0;
m.pop();
}
}
if(m.size()==0&&q.size()!=0&&q.top()!=n.front())
{
h=1;
break;
}
if(n.size()==0)
break;
}
if(h==1)
printf("No.\nFINISH\n");
else if(h!=1)
{ printf("Yes.\n");
for(i=0;i<u;i++)
{
if(cd[i]==0)
printf("in\n");
else if(cd[i]==1)
printf("out\n");
}
printf("FINISH\n");
}
}
return 0;
}














 277
277











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









