







Centos6.5+java1.7+hadoop2.4 搭建开发环境
1.环境资源
Win7下VMware10 http://pan.baidu.com/s/1qWDJxCg
centos6.5 http://pan.baidu.com/s/1mg3ciVm
JDK1.7 http://pan.baidu.com/s/1mg2wl40
hadoop2.4 http://pan.baidu.com/s/1gdILy1d
2.虚拟机安装和网路配置
虚拟机安装有一点需要注意:三台虚拟机网络模式请选择<桥接模式>

然后查看三台虚拟机ip,并使用ping命令,保证三台虚拟机互相ping通的情况下,修改成静态IP。
具体修改方法如下:ifconfig查看ip

可以看到eht0的配置信息,然后使用vim修改eht0中的信息,改成使用静态IP
使用VI编辑器设置,如 vi /etc/sysconfig/network-scripts/ifcfg-eth0

BOOTPROTO=static 意为静态获得IP
然后设置DNS1, GATEWAY,IPADDR(请参照主机上的配置设置)
最后运行:service network restart 重启网络
检查IP设置是否成功(ifconfig),三台主机IP设置好后,注意检查下是否能互相ping通,若能ping通则进入下一步骤
3.配置Centos的SSH无密码登录
首先修改ssh配置文件
$ vim /etc/ssh/sshd_config(root登录)
找到下列行 去掉注释负号#
RSAAuthentication yes //字面意思..允许RSA认证
PubkeyAuthentication yes //允许公钥认证
AuthorizedKeysFile .ssh/authorized_keys //公钥存放在.ssh/au..文件中

修改后需要重启ssh
$ /sbin/servive sshd restart
然后在所有虚拟机上运行:$ ssh-keygen -t rsa 生成密匙(所有输入都回车)
在主节点上操作:执行cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys (~是你所建用户的用户目录)
在主节点上操作:执行ssh slave1 cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys 将slave1节点上的密匙加入主节点密匙库
在主节点上操作:执行scp ~/.ssh/authorized_keys slave1:~/.ssh/authorized_keys 将密匙库导入到slave1节点上
(slave1 是从节点IP或者是Hosts中对应从节点IP的名称)(几个节点就需要操作几次)
然后使用ssh slave1 逐个验证是否能无密码登录
4.安装并配置java1.7
下载下来java1.7解压到你想要安装的文件夹下
然后执行:vim /etc/profile 在最后添加java环境变量 如图:

最后执行: source /etc/profile
验证jdk安装是否成功

5.下载并配置hadoop
下载hadoop并解压自己想要安装到的路径
在java环境变量下配置hadoop环境变量:同样使用vim 编辑/etc/profile
如图:

然后配置hadoop的配置文件 在etc文件夹下的hadoop文件夹里
修改hadoop-env.sh
添加

修改yarn-env.sh
添加
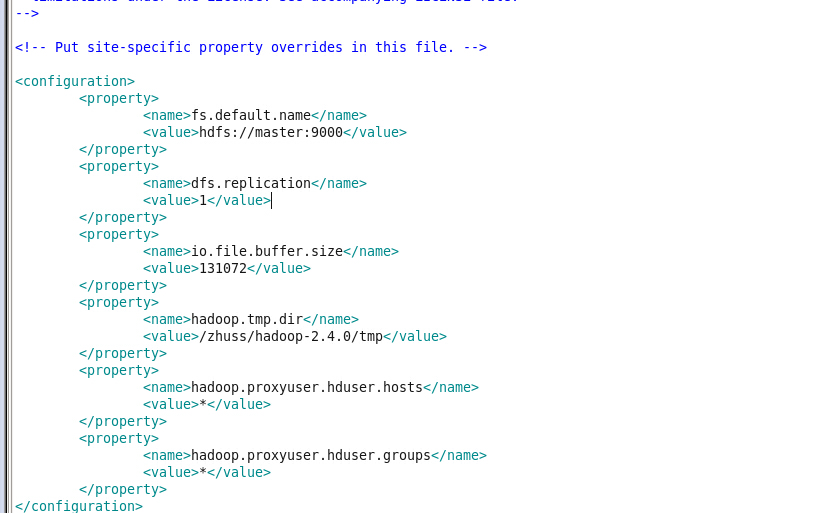
修改core-site.xml
如图
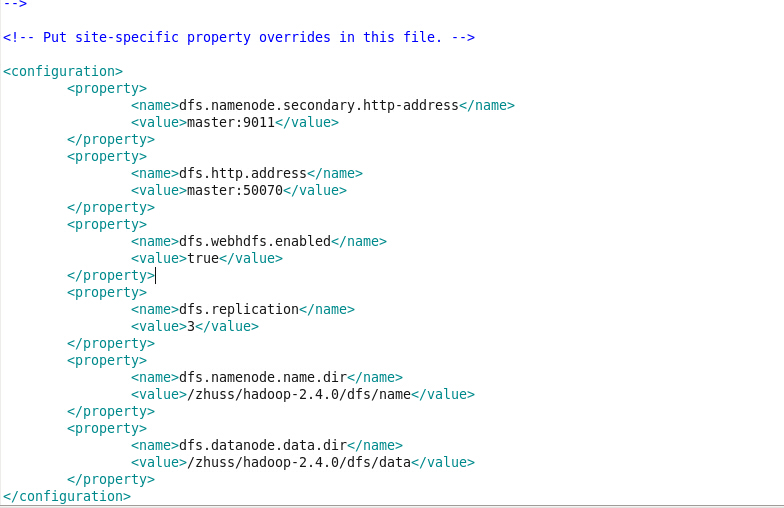
修改hdfs-site.xml
如图
修改yarn-site.xml
如图

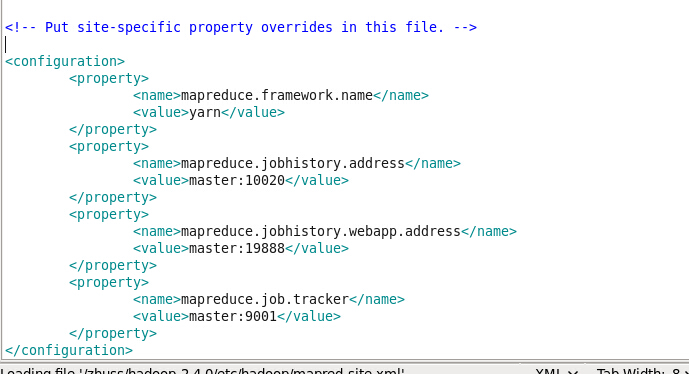
根据mapred-site.xml.template 创建mapred-site.xml 修改
如图
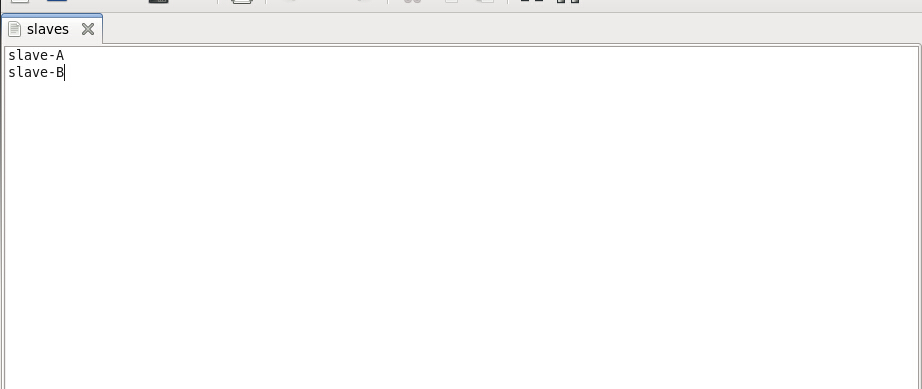
修改slaves文件
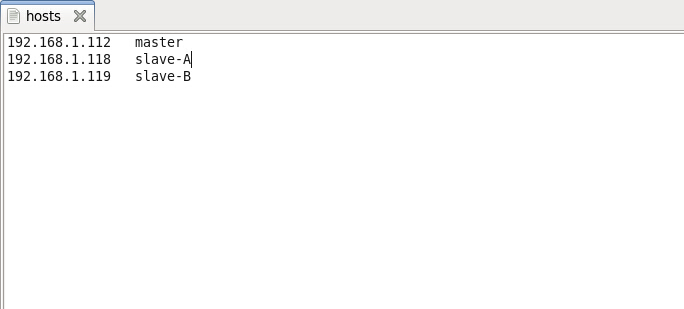
/etc/hosts文件如下
slaves文件修改如下
《注意:如果没有配置hosts文件的话,请配置从节点的IP》
然后将配置好的hosts,profile,jDK,hadoop 进行copy分别放到从节点的相同目录下 重启从节点
主节点执行 hadoop namenode -format
成功后运行sbin目录下的start-all.sh
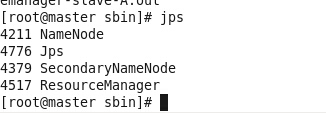
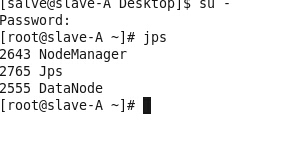
然后执行jps命令
master(主)
slave(从)
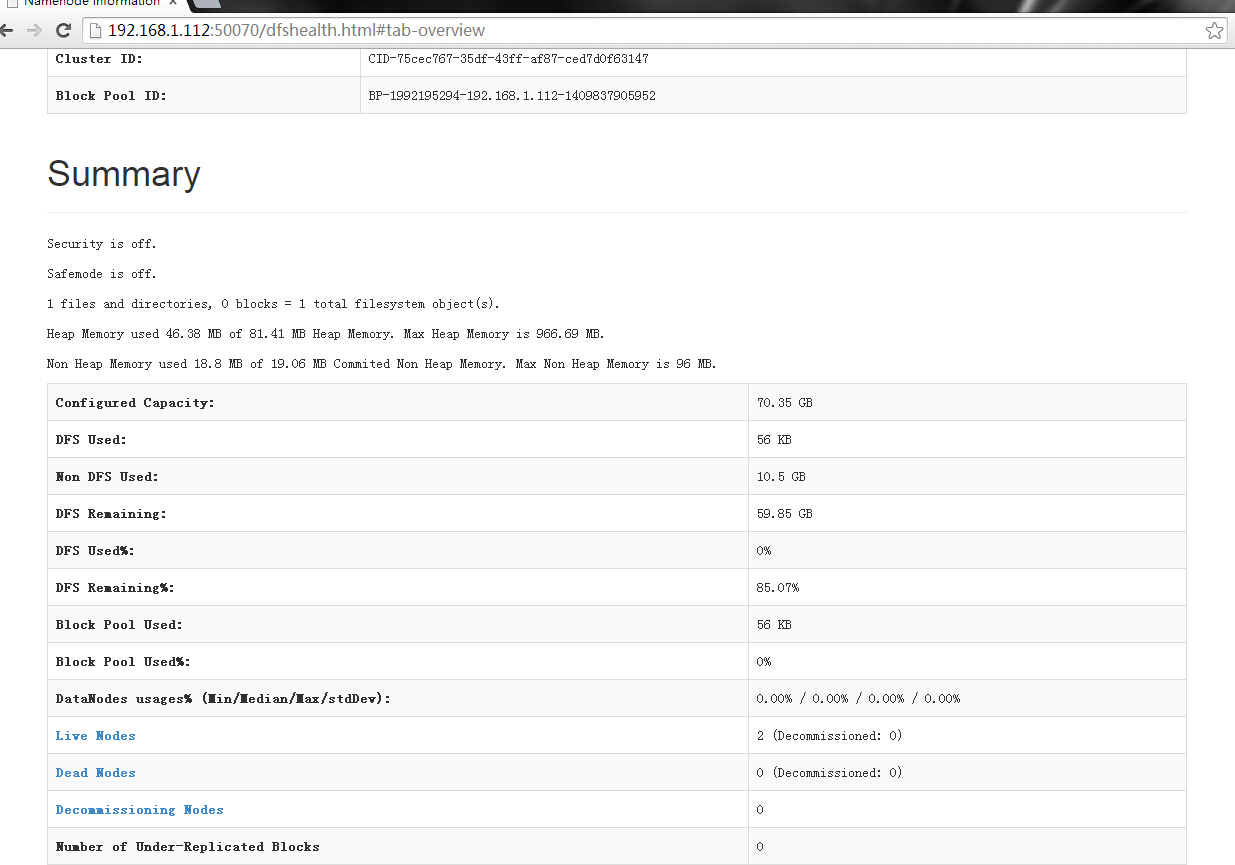
最后访问
master:50070
master:8088
(master是主节点服务器IP的映射)
我自己也是刚学习hadoop, 这个是我的QQ号码:714303584 欢迎一起学习进步















 1400
1400

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









