






 本文介绍了SEU_PML数据集,专为城市混合交通中的交通参与者检测设计,包含高质量标注和丰富场景。YOLOSOD检测器利用SRFEM模块和知识蒸馏技术改进小目标检测。同时,一种新型损失函数S-IoU被提出以增强对小物体的关注。
本文介绍了SEU_PML数据集,专为城市混合交通中的交通参与者检测设计,包含高质量标注和丰富场景。YOLOSOD检测器利用SRFEM模块和知识蒸馏技术改进小目标检测。同时,一种新型损失函数S-IoU被提出以增强对小物体的关注。
介绍
基于监控的交通参与者检测(TPD)是一个非常理想但具有挑战性的任务。到目前为止,基于深度学习的方法在TPD任务上取得了显著的进步,但由于缺乏相关的数据集和合适的检测器,在城市混合交通中常常失败。因此文章作者提出了一个名为SEU_PML的大型详细数据集,专门用于城市混合交通中基于监测的TPD。该数据集共包含270,684个2D边界框标注对象,涵盖13个子类别,具有高分辨率图像(1920 × 1080 ~ 4096 × 2160像素)、高质量标注(标注准确率达到98%)和丰富的交通场景,涵盖了不同的交通场景以及不同的天气和光照条件。混合流量伴随着高质量的标注带来了各种各样的小对象。
为了进一步解决小目标检测问题,作者提出了一种新的检测器YOLO SOD,该检测器嵌入超分辨率特征提取模块,并使用知识蒸馏来学习具有高分辨率输入的检测器如何感知小目标的知识。此外,还设计了一种名为S-IoU的新型损失函数,使YOLO SOD能够更多地关注小物体。
创新点
数据集
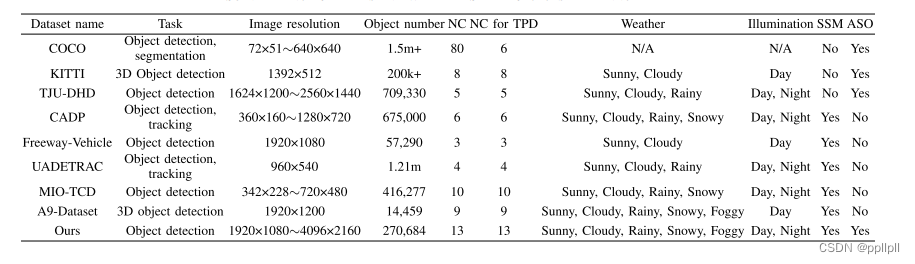
从作者给出的图中看,他们提出的数据集是一种目标检测数据集,同时包含了更多种在不同天气条件下的车辆数据,有着更好的泛化性。同时,数据集包含6,558张图像,这些图像来自位于江苏和浙江城市道路上的数百个路边监控摄像头。这些图像的分辨率从1920×1080到4096×2160像素不等,保留了交通参与者的基本外观细节,总共有270,684个对象被标注为2D边界框。值得注意的是,作者标注的是被遮挡物体的可见部分,而不是它们在遮挡后的假定物理范围。
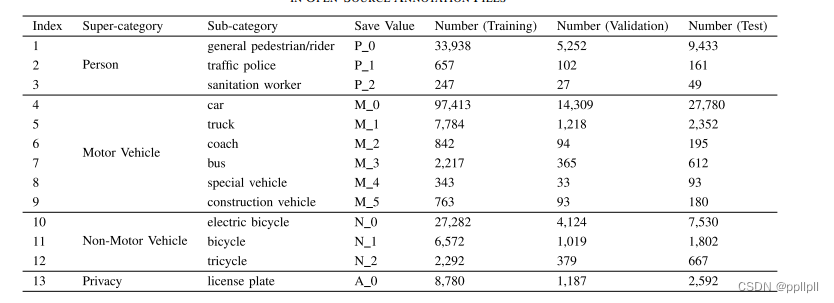
下图为标注的数据类型及数量
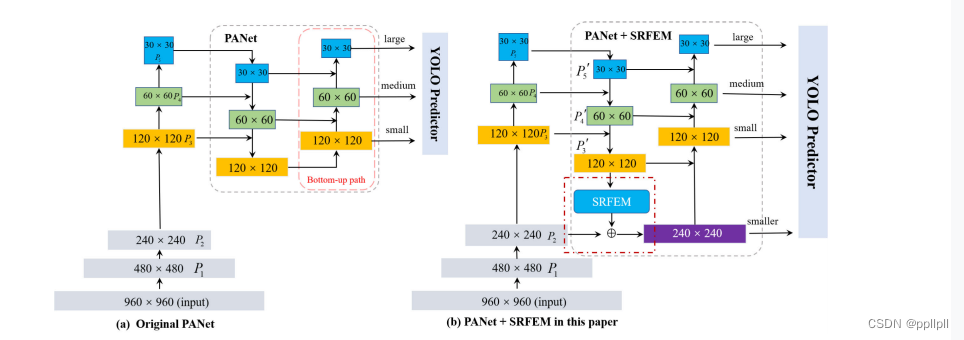
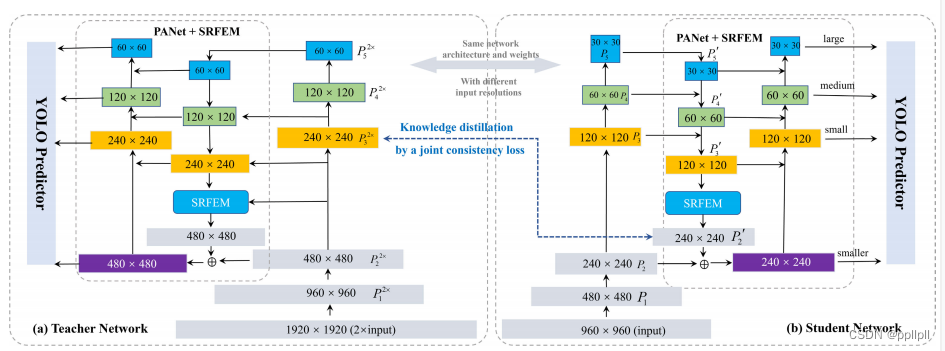
SRFEM模块
文章中在YOLO V5的PANet的底部金字塔层中嵌入一个超分辨率特征提取模块(SRFEM),得到一个更高分辨率的额外金字塔层。
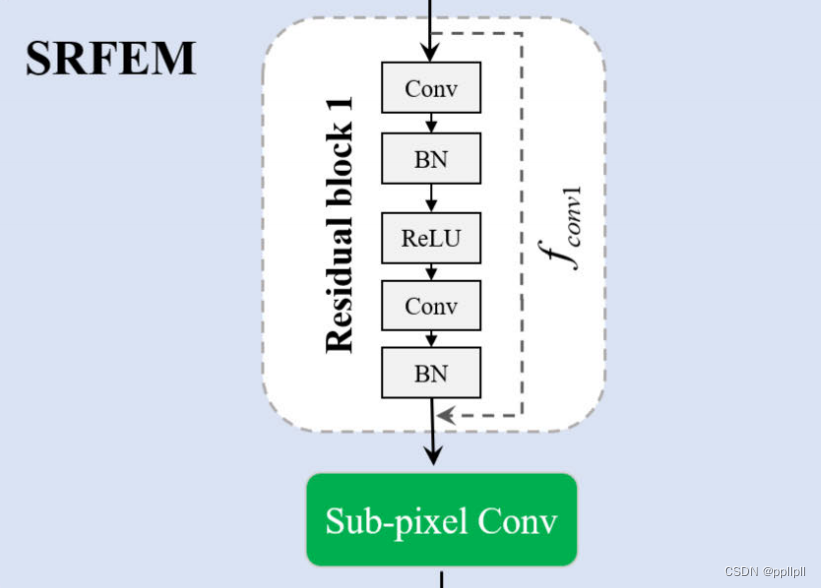
SRFEM的结构,由残差块和亚像素卷积组成,其中SRFEM模块结构如下
知识蒸馏
文中的作者发现,在没有额外的监督来训练亚像素卷积的情况下,直接使用亚像素卷积来生成更高分辨率的特征图并不能提高对小物体的检测性能。因此作者使用知识蒸馏的方式来提高小目标精度。在本文的知识蒸馏过程中,将正常分辨率输入(960 × 960像素,从原始图像下采样)的YOLO SOD检测器称为学生网络(图8 (b)),而同样的网络采用两倍大的输入(1920 × 1920像素)。
siou
文中提出了一种新型的损失函数称之为siou,但是其实就是在ciou的基础上乘以一个权重系数η,公式如下:
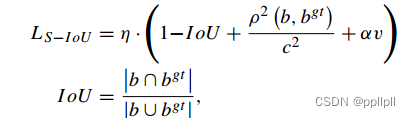
其中权重η的公式如下:
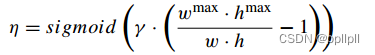
式中(w, h)是b和的宽度和高度,wmax和hMax分别为训练集中面积最大的包围框对应的宽度和高度。在推理过程中,wmax和hmax的设置与训练过程中的设置一致;γ是一个预先定义的参数,用于调整对小物体的灵敏度。
论文和代码
论文
本文论文并未在arxiv公布,可以去ieeexplore搜索
论文地址:论文
代码
本文并未开源代码,只开源了数据集
数据集地址:数据集


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









