









一、适用场景
将A系统中的数据迁移到B系统中,对迁移的数据进行完整性、一致性、可用性的验证
二、 测试前需要了解
- 了解需要迁移的数据范围,比如时间范围、哪些模块要迁移
- 清楚迁移数据是一次性的全量迁移,还是会涉及到增量迁移
- 迁移数据的方法,是通过什么方式来进行迁移的
三、根据迁移方案制定测试方案
在迁移方案制定过程要也要参与到其中,一方面是为了验证迁移方案是否合理,另一方面是为了能制定出合理的测试方案和测试计划
以下以某某省旧业务系统迁移到新业务系统为例(从SQLserver数据库迁移到postgre数据库)
1、基础数据对应关系建立
- 单值对应关系建立:验证单值对应关系,要保证旧系统中有的单值在新系统中都能对应上
- 部门/人员组织机构关系建立:对于在旧系统存在,而新系统库中不存在的进行抽取,若旧系统和新系统库中均存在则不更新,以新系统库为准(每家监狱都需要进行初始化)
- 特殊情况处理:词组情况(在旧系统中页面上看着是单值,但存储在数据库中是文本格式的字段,需要整理出这样的字段,并且在业务库中新加一个对应的字段来存储)
2、迁移过程验证分析
使用的**PDI(Pentaho Data Integration)**这款工具(没有深入了解过,但知道怎么操作,能看懂SQL和转换关系就能完成测试工作了),数据过程如图所示
说明:旧系统是每个地方各部署一套,然后定期进行数据集中汇总,迁移到的新系统是集中部署的,所以需要将各地方部署的数据库一个个的都迁移到新业务系统的数据库中
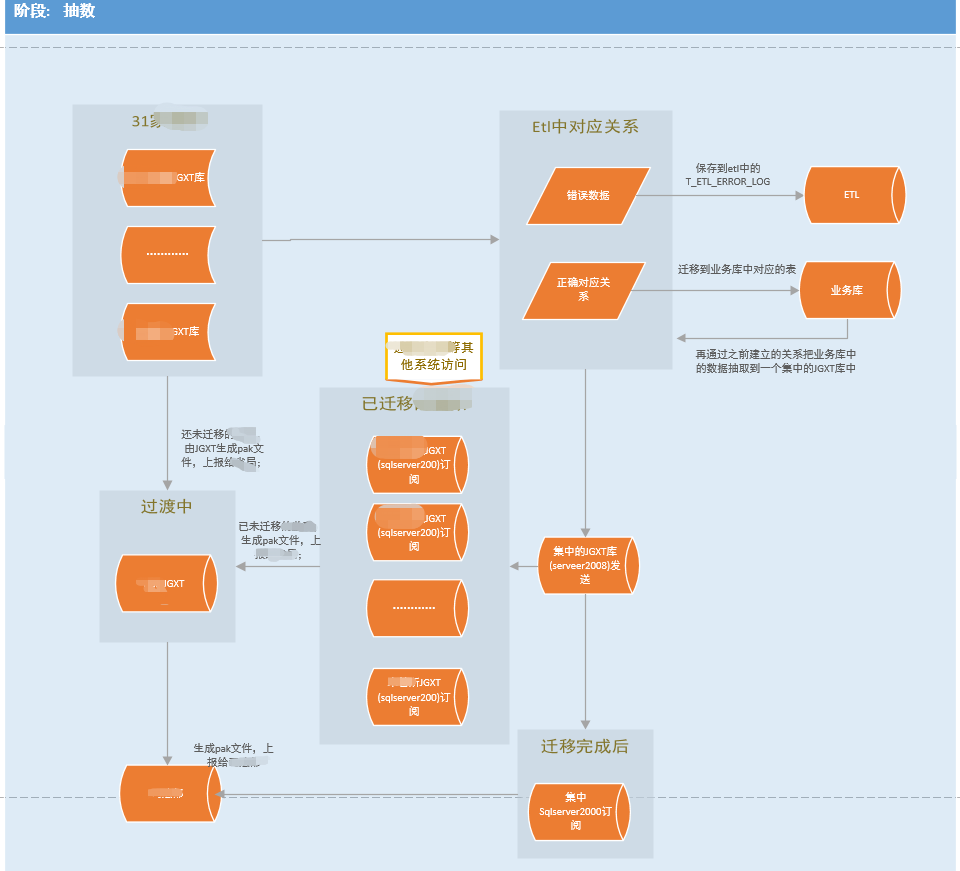
3、测试验证过程,确保数据的完整性、一致性、可用性:
- 迁移每类数据前,先了解PDI程序中对应的作业,明白整个作业中需要做什么事(需要了解原数据表是哪些,目标表对应的是哪些,并且对应关系是怎样的)
- 查看PDI中从原数据库查询SQL的数据范围正确性
- 验证PDI中的转换程序对应关系的正确性
- 迁移完后 比对各业务表中数据量
- 查看ETL库中错误信息表(t_etl_error_log),了解哪些表抽数失败,并分析原因;在t_etl_nor_log存放已抽取过来的数据,c_flag字段会标志此数据是新增还是更新过来的
- 由于在迁移的过程中可能存在用户使用老系统的情况,需要考虑增量抽取的情况,并且在造数据时注意以下内容的覆盖和验证:
- 增量抽取情况(需要根据抽取频率、数据量,考虑抽取数据的效率)
- 迁移所涉及到的业务需要都进行录入数据,并且最好每类都能覆盖到
- 可为空字段都为空
- 允许输入的字段输入允许的最大值
- 对于可以输入亦可以选择,两种情况都需要覆盖(即上面说的词组情况)
- 修改数据后,验证是否是修改后的内容
- 可以删除的数据被删除后,数据是否同步
- 在业务系统中操作迁移过来的数据,查看是否能正确处理,需要特别注意
- 必填项是空值的情况
- 在系统中无对应代码值的情况
- 对于文本类,两边设置的长度是否一样
- 日期字段显示是否符合规范
- 重点模块的业务
- 由于数据迁移导致新业务系统新加字段,并且需要在页面上显示,重点测试

















 6845
6845

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









