






基于BP神经网络的数据分类预测
matlab 代码
这段程序是一个简单的神经网络模型,用于分类任务。下面我将对程序进行详细分析和解释。
首先,程序开始时清空环境变量、关闭报警信息、关闭图窗、清空变量和命令行。这些操作是为了确保程序运行时的环境干净。
接下来,程序读取名为"数据集.xlsx"的Excel文件中的数据,并将数据存储在变量"res"中。
然后,程序通过统计"res"中的类别数和样本数,计算出训练集和测试集的划分比例。默认情况下,训练集占数据集的70%。
接着,程序根据类别将数据集划分为训练集和测试集。对于每个类别,根据划分比例,将相应数量的样本分配给训练集和测试集。
然后,程序对训练集和测试集进行数据转置,以便后续处理。
接下来,程序对训练集和测试集进行数据归一化处理。使用mapminmax函数将输入数据映射到0到1的范围内,以便更好地进行神经网络训练。
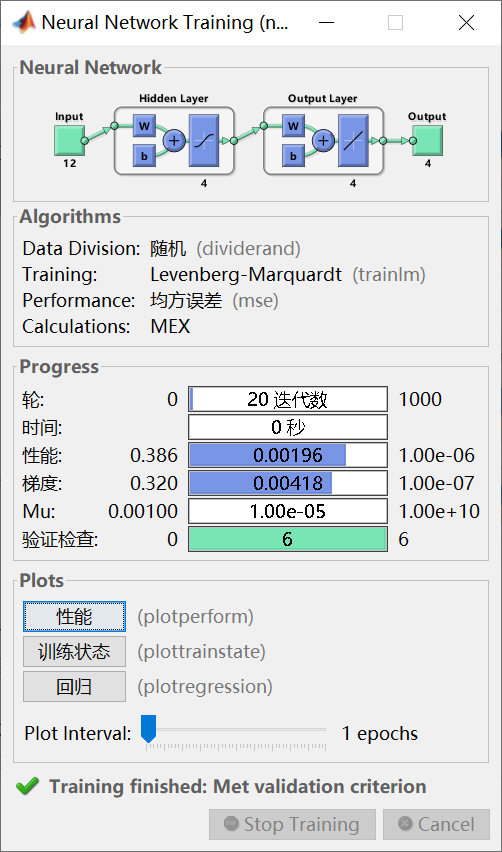
然后,程序定义了一些超参数,包括最大训练次数、学习率和隐藏层节点数。
接下来,程序开始进行模型训练。调用net_train函数,传入训练集数据、训练集标签、隐藏层节点数、学习率和最大训练次数。net_train函数会返回训练好的神经网络模型和损失函数值。
然后,程序使用训练好的模型对训练集和测试集进行预测。调用net_sim函数,传入训练集和测试集数据以及训练好的模型。net_sim函数会返回预测结果。
接下来,程序对预测结果进行反归一化处理,将预测结果转换为类别标签。
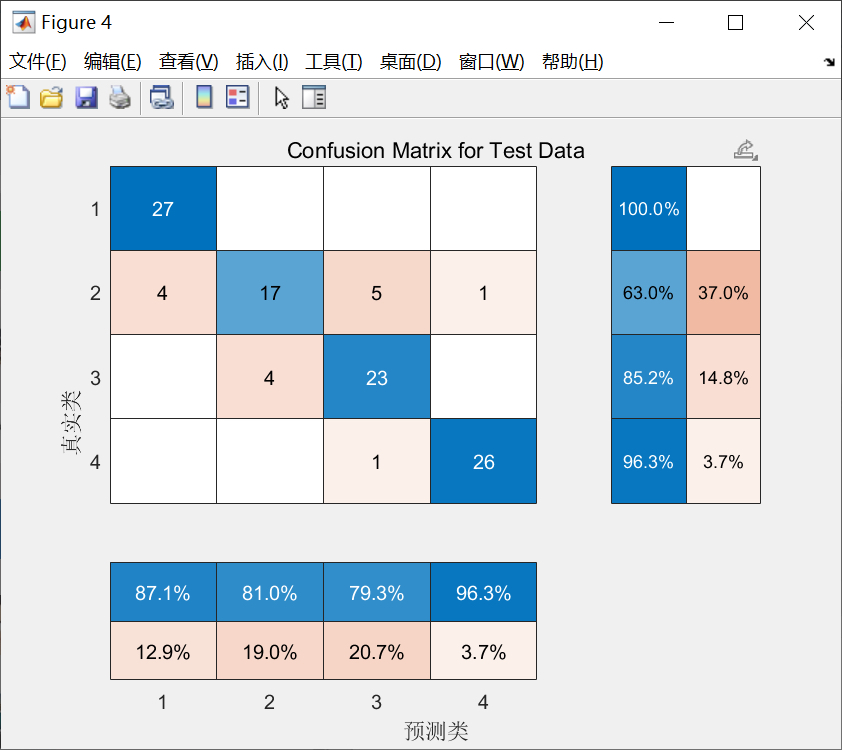
然后,程序计算训练集和测试集的准确率。
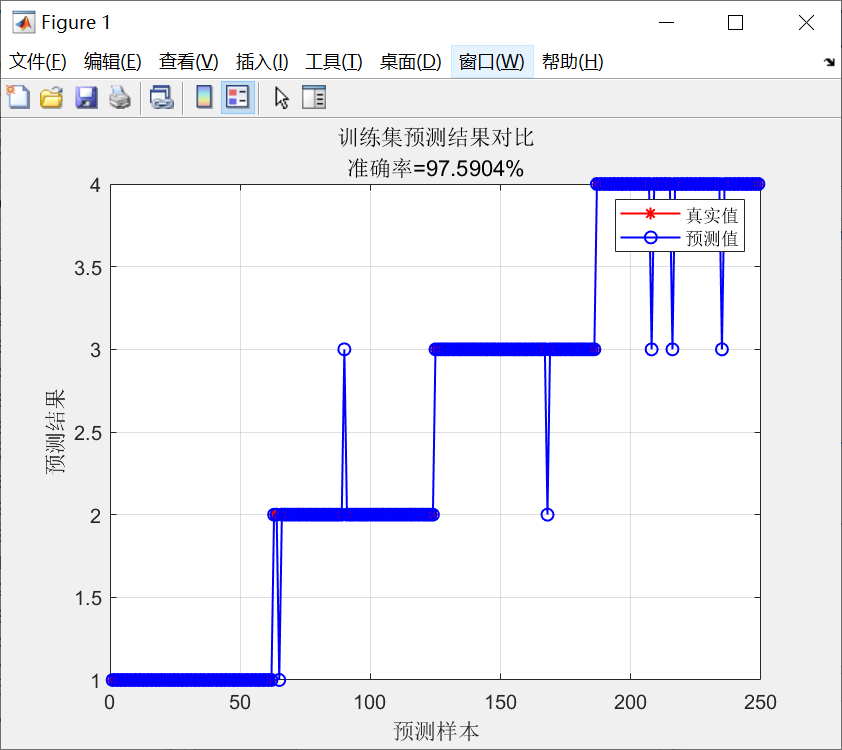
接着,程序绘制了训练集和测试集的预测结果对比图。图中包含真实值和预测值,以及准确率的显示。
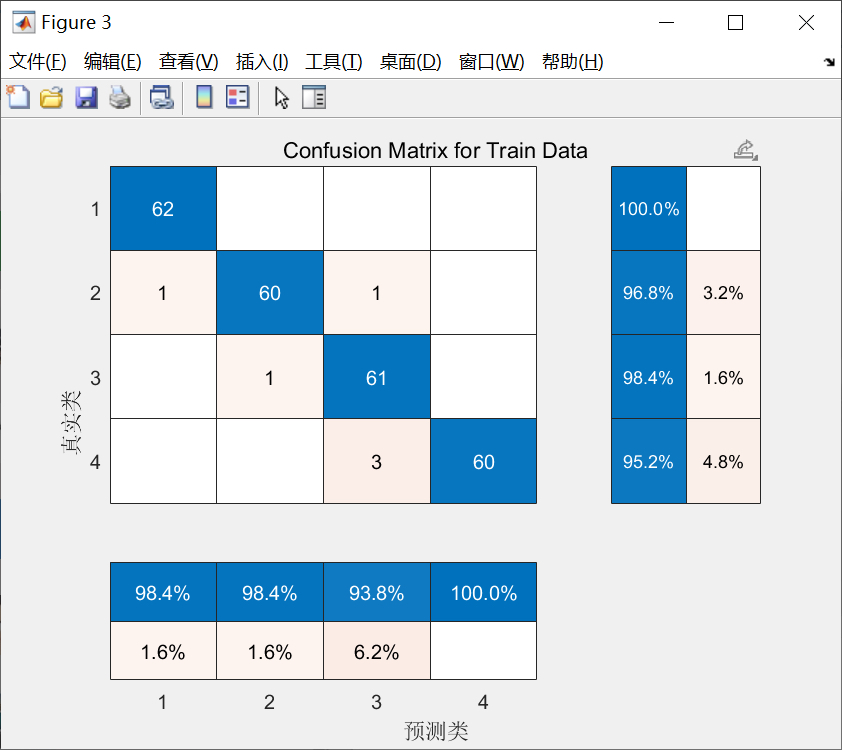
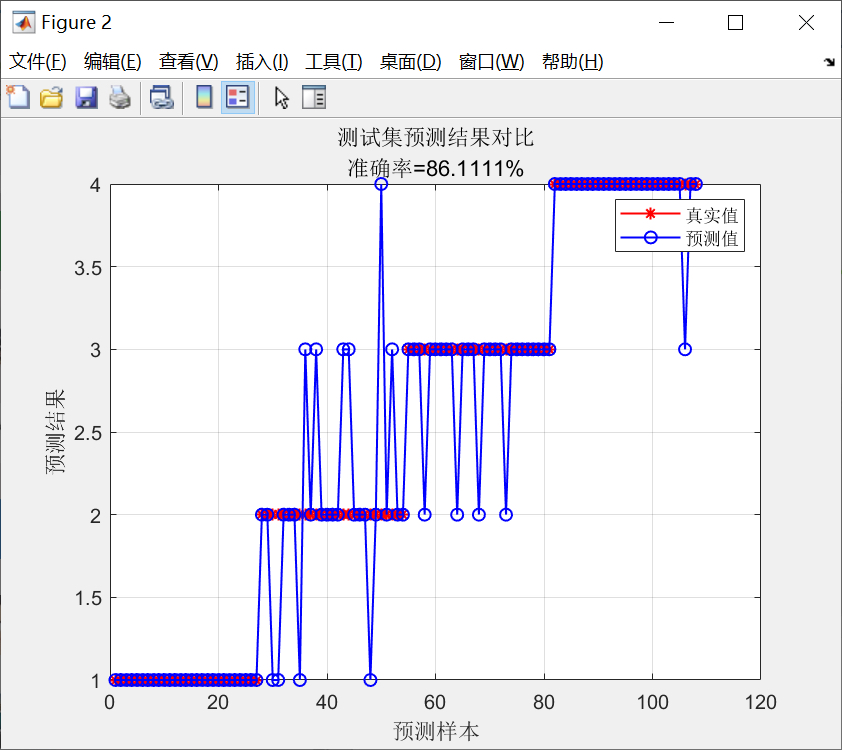
然后,程序根据标志位判断是否绘制混淆矩阵。如果标志位为1,则绘制训练集和测试集的混淆矩阵。
接下来,程序绘制了损失函数的曲线图,用于显示训练过程中损失函数的变化情况。
最后,程序结束。
总结起来,这段程序主要是一个简单的神经网络模型,用于分类任务。它读取数据集,划分训练集和测试集,对数据进行归一化处理,定义超参数,进行模型训练和预测,计算准确率,绘制预测结果对比图和损失函数曲线图。它涉及到的知识点包括神经网络、数据处理、数据归一化和性能评价等。
YID:6729642951760873
誩宝
基于BP神经网络的数据分类预测
神经网络是一种模拟人脑神经元网络结构和工作方式的计算模型。在数据分类预测任务中,神经网络能够通过学习样本的特征和标签之间的映射关系,实现对未知样本的分类预测。本文将对一段基于BP神经网络的数据分类预测程序进行详细分析和解释。
程序开始时进行一系列的初始化操作,包括清空环境变量、关闭报警信息、关闭图窗、清空变量和命令行。这些操作的目的是为了确保程序运行时的环境干净。
接下来,程序读取名为"数据集.xlsx"的Excel文件中的数据,并将数据存储在变量"res"中。这个数据集包含了用于分类预测的样本数据。
然后,程序根据样本数据的类别数和样本数,计算出训练集和测试集的划分比例。默认情况下,训练集占数据集的70%。这个划分比例可以根据实际情况进行调整。
接着,程序根据类别将数据集划分为训练集和测试集。对于每个类别,根据划分比例,将相应数量的样本分配给训练集和测试集。这样可以保证训练集和测试集中各类别的样本数量比例与原始数据集相同。
然后,程序对训练集和测试集进行数据转置,以便后续处理。数据转置可以使得每个样本的特征值在矩阵中对齐,方便后续的数据处理。
接下来,程序对训练集和测试集进行数据归一化处理。数据归一化是一种常用的数据预处理方法,可以将输入数据映射到0到1的范围内,以便更好地进行神经网络训练。程序使用mapminmax函数实现数据归一化处理。
然后,程序定义了一些超参数,包括最大训练次数、学习率和隐藏层节点数。这些超参数可以根据实际情况进行调整,以获得更好的分类预测性能。
接下来,程序开始进行模型训练。调用net_train函数,传入训练集数据、训练集标签、隐藏层节点数、学习率和最大训练次数。net_train函数会返回训练好的神经网络模型和损失函数值。通过不断调整神经网络的权重和偏置,使得模型能够更好地拟合训练集的样本特征和标签之间的关系。
然后,程序使用训练好的模型对训练集和测试集进行预测。调用net_sim函数,传入训练集和测试集数据以及训练好的模型。net_sim函数会返回预测结果。预测结果是对样本的分类标签进行预测。
接下来,程序对预测结果进行反归一化处理,将预测结果转换为类别标签。这样可以使得预测结果与原始类别标签保持一致,方便后续的准确率计算和结果展示。
然后,程序计算训练集和测试集的准确率。准确率是评价分类预测模型性能的重要指标之一,它表示模型对数据的正确预测比例。
接着,程序绘制了训练集和测试集的预测结果对比图。图中包含了真实值和预测值,以及准确率的显示。通过对比真实值和预测值,可以直观地评估分类预测模型的性能。
然后,程序根据标志位判断是否绘制混淆矩阵。混淆矩阵是评价分类预测模型性能的另一个重要工具,它可以反映模型对各个类别的分类情况。如果标志位为1,则绘制训练集和测试集的混淆矩阵。
接下来,程序绘制了损失函数的曲线图,用于显示训练过程中损失函数的变化情况。损失函数是衡量模型预测值与真实值之间差异的指标,通过观察损失函数的变化可以评估模型的训练效果。
最后,程序结束。通过对这段程序的详细分析和解释,我们可以了解到神经网络在数据分类预测任务中的应用过程。这段程序主要涉及到数据处理、数据归一化、超参数调整、神经网络训练和预测、准确率计算、结果展示等知识点。熟练掌握这些知识点,对于进行数据分类预测任务具有重要的意义。
相关的代码,程序地址如下:http://imgcs.cn/642951760873.html
















 1770
1770











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









