









 本文介绍如何使用Python的pymysql模块进行数据库操作,通过面向对象的方式创建数据库脚本,实现姓名和年龄数据的批量生成与插入。代码示例展示了如何连接数据库、执行SQL命令以及处理异常。
本文介绍如何使用Python的pymysql模块进行数据库操作,通过面向对象的方式创建数据库脚本,实现姓名和年龄数据的批量生成与插入。代码示例展示了如何连接数据库、执行SQL命令以及处理异常。
既然使用python操作数据库必不可少的得使用pymysql模块
可使用两种方式进行下载安装:
1、使用pip方式下载安装
pip install pymysql
2、IDE方式
安装完成后就可以正常导入模块使用
我们这里使用简单的测试,创建一个数据库及表,表里放入字段name,age
我们去网上先找到百家姓及在起名网站里复制一些名字用于生成姓名:
lst_first = [
'赵', '钱', '孙', '李', '周', '吴', '郑', '王', '冯', '陈', '褚', '卫', '蒋', '沈', '韩', '杨', '朱', '秦', '尤', '许',
'何', '吕', '施', '张', '孔', '曹', '严', '华', '金', '魏', '陶', '姜', '戚', '谢', '邹', '喻', '柏', '水', '窦', '章',
'云', '苏', '潘', '葛', '奚', '范', '彭', '郎', '鲁', '韦', '昌', '马', '苗', '凤', '花', '方', '俞', '任', '袁', '柳',
'酆', '鲍', '史', '唐', '费', '廉', '岑', '薛', '雷', '贺', '倪', '汤', '滕', '殷', '罗', '毕', '郝', '邬', '安', '常',
'乐', '于', '时', '傅', '皮', '卞', '齐', '康', '伍', '余', '元', '卜', '顾', '孟', '平', '黄', '和', '穆', '萧', '尹',
'姚', '邵', '堪', '汪', '祁', '毛', '禹', '狄', '米', '贝', '明', '臧', '计', '伏', '成', '戴', '谈', '宋', '茅', '庞',
'熊', '纪', '舒', '屈', '项', '祝', '董', '梁']
lst_last = [
'的', '一', '是', '了', '我', '不', '人', '在', '他', '有', '这', '个', '上', '们', '来', '到', '时', '大', '地', '为',
'子', '中', '你', '说', '生', '国', '年', '着', '就', '那', '和', '要', '她', '出', '也', '得', '里', '后', '自', '以',
'会', '家', '可', '下', '而', '过', '天', '去', '能', '对', '小', '多', '然', '于', '心', '学', '么', '之', '都', '好',
'看', '起', '发', '当', '没', '成', '只', '如', '事', '把', '还', '用', '第', '样', '道', '想', '作', '种', '开', '美',
'总', '从', '无', '情', '己', '面', '最', '女', '但', '现', '前', '些', '所', '同', '日', '手', '又', '行', '意', '动',
'方', '期', '它', '头', '经', '长', '儿', '回', '位', '分', '爱', '老', '因', '很', '给', '名', '法', '间', '斯', '知',
'世', '什', '两', '次', '使', '身', '者', '被', '高', '已', '亲', '其', '进', '此', '话', '常', '与', '活', '正', '感',
'见', '明', '问', '力', '理', '尔', '点', '文', '几', '定', '本', '公', '特', '做', '外', '孩', '相', '西', '果', '走',
'将', '月', '十', '实', '向', '声', '车', '全', '信', '重', '三', '机', '工', '物', '气', '每', '并', '别', '真', '打',
'太', '新', '比', '才', '便', '夫', '再', '书', '部', '水', '像', '眼', '等', '体', '却', '加', '电', '主', '界', '门',
'利', '海', '受', '听', '表', '德', '少', '克', '代', '员', '许', '稜', '先', '口', '由', '死', '安', '写', '性', '马',
'光', '白', '或', '住', '难', '望', '教', '命', '花', '结', '乐', '色', '更', '拉', '东', '神', '记', '处', '让', '母',
'父', '应', '直', '字', '场', '平', '报', '友', '关', '放', '至', '张', '认', '接', '告', '入', '笑', '内', '英', '军',
'候', '民', '岁', '往', '何', '度', '山', '觉', '路', '带', '万', '男', '边', '风', '解', '叫', '任', '金', '快', '原',
'吃', '妈', '变', '通', '师', '立', '象', '数', '四', '失', '满', '战', '远', '格', '士', '音', '轻', '目', '条', '呢',
'病', '始', '达', '深', '完', '今', '提', '求', '清', '王', '化', '空', '业', '思', '切', '怎', '非', '找', '片', '罗',
'钱', '紶', '吗', '语', '元', '喜', '曾', '离', '飞', '科', '言', '干', '流', '欢', '约', '各', '即', '指', '合', '反',
'题', '必', '该', '论', '交', '终', '林', '请', '医', '晚', '制', '球', '决', '窢', '传', '画', '保', '读', '运', '及',
'则', '房', '早', '院', '量', '苦', '火', '布', '品', '近', '坐', '产', '答', '星', '精', '视', '五', '连', '司', '巴',
'奇', '管', '类', '未', '朋', '且', '婚', '台', '夜', '青', '北', '队', '久', '乎', '越', '观', '落', '尽', '形', '影',
'红', '爸', '百', '令', '周', '吧', '识', '步', '希', '亚', '术', '留', '市', '半', '热', '送', '兴', '造', '谈', '容',
'极', '随', '演', '收', '首', '根', '讲', '整', '式', '取', '照', '办', '强', '石', '古', '华', '諣', '拿', '计', '您',
'装', '似', '足', '双', '妻', '尼', '转', '诉', '米', '称', '丽', '客', '南', '领', '节', '衣', '站', '黑', '刻', '统',
'断', '福', '城', '故', '历', '惊', '脸', '选', '包', '紧', '争', '另', '建', '维', '绝', '树', '系', '伤', '示', '愿',
'持', '千', '史', '谁', '准', '联', '妇', '纪', '基', '买', '志', '静', '阿', '诗', '独', '复', '痛', '消', '社', '算',
'义', '竟', '确', '酒', '需', '单', '治', '卡', '幸', '兰', '念', '举', '仅', '钟', '怕', '共', '毛', '句', '息', '功',
'官', '待', '究', '跟', '穿', '室', '易', '游', '程', '号', '居', '考', '突', '皮', '哪', '费', '倒', '价', '图', '具',
'刚', '脑', '永', '歌', '响', '商', '礼', '细', '专', '黄', '块', '脚', '味', '灵', '改', '据', '般', '破', '引', '食',
'仍', '存', '众', '注', '笔', '甚', '某', '沉', '血', '备', '习', '校', '默', '务', '土', '微', '娘', '须', '试', '怀',
'料', '调', '广', '蜖', '苏', '显', '赛', '查', '密', '议', '底', '列', '富', '梦', '错', '座', '参', '八', '除', '跑',
'亮', '假', '印', '设', '线', '温', '虽', '掉', '京', '初', '养', '香', '停', '际', '致', '阳', '纸', '李', '纳', '验',
'助', '激', '够', '严', '证', '帝', '饭', '忘', '趣', '支', '春', '集', '丈', '木', '研', '班', '普', '导', '顿', '睡',
'展', '跳', '获', '艺', '六', '波', '察', '群', '皇', '段', '急', '庭', '创', '区', '奥', '器', '谢', '弟', '店', '否',
'害', '草', '排', '背', '止', '组', '州', '朝', '封', '睛', '板', '角', '况', '曲', '馆', '育', '忙', '质', '河', '续',
'哥', '呼', '若', '推', '境', '遇', '雨', '标', '姐', '充', '围', '案', '伦', '护', '冷', '警', '贝', '著', '雪', '索',
'剧', '啊', '船', '险', '烟', '依', '斗', '值', '帮', '汉', '慢', '佛', '肯', '闻', '唱', '沙', '局', '伯', '族', '低',
'玩', '资', '屋', '击', '速', '顾', '泪', '洲', '团', '圣', '旁', '堂', '兵', '七', '露', '园', '牛', '哭', '旅', '街',
'劳', '型', '烈', '姑', '陈', '莫', '鱼', '异', '抱', '宝', '权', '鲁', '简', '态', '级', '票', '怪', '寻', '杀', '律',
'胜', '份', '汽', '右', '洋', '范', '床', '舞', '秘', '午', '登', '楼', '贵', '吸', '责', '例', '追', '较', '职', '属',
'渐', '左', '录', '丝', '牙', '党', '继', '托', '赶', '章', '智', '冲', '叶', '胡', '吉', '卖', '坚', '喝', '肉', '遗',
'救', '修', '松', '临', '藏', '担', '戏', '善', '卫', '药', '悲', '敢', '靠', '伊', '村', '戴', '词', '森', '耳', '差',
'短', '祖', '云', '规', '窗', '散', '迷', '油', '旧', '适', '乡', '架', '恩', '投', '弹', '铁', '博', '雷', '府', '压',
'超', '负', '勒', '杂', '醒', '洗', '采', '毫', '嘴', '毕', '九', '冰', '既', '状', '乱', '景', '席', '珍', '童', '顶',
'派', '素', '脱', '农', '疑', '练', '野', '按', '犯', '拍', '征', '坏', '骨', '余', '承', '置', '臓', '彩', '灯', '巨',
'琴', '免', '环', '姆', '暗', '换', '技', '翻', '束', '增', '忍', '餐', '洛', '塞', '缺', '忆', '判', '欧', '层', '付',
'阵', '玛', '批', '岛', '项', '狗', '休', '懂', '武', '革', '良', '恶', '恋', '委', '拥', '娜', '妙', '探', '呀', '营',
'退', '摇', '弄', '桌', '熟', '诺', '宣', '银', '势', '奖', '宫', '忽', '套', '康', '供', '优', '课', '鸟', '喊', '降',
'夏', '困', '刘', '罪', '亡', '鞋', '健', '模', '败', '伴', '守', '挥', '鲜', '财', '孤', '枪', '禁', '恐', '伙', '杰',
'迹', '妹', '藸', '遍', '盖', '副', '坦', '牌', '江', '顺', '秋', '萨', '菜', '划', '授', '归', '浪', '听', '凡', '预',
'奶', '雄', '升', '碃', '编', '典', '袋', '莱', '含', '盛', '济', '蒙', '棋', '端', '腿', '招', '释', '介', '烧', '误',
'乾', '坤']
利用面向对象来创建一个正规一点的脚本
直接上代码
import pymysql
import random
class DatabaseAccess():
#初始化属性
def __init__(self):
self.__db_host = "localhost"
self.__db_port = 3306
self.__db_user = "root"
self.__db_password = "123"
self.__db_database = "school"
#链接数据库
def isConnectionOpen(self):
self.__db = pymysql.connect(
host=self.__db_host,
port=self.__db_port,
user=self.__db_user,
password=self.__db_password,
database=self.__db_database,
charset='utf8'
)
插入数据
def linesinsert(self,names,ages):
try:
#连接数据库
self.isConnectionOpen()
# 创建游标
global cursor
cursor = self.__db.cursor()
# sql命令
sql = "insert into student(name,age) value(%s,%s)"
# 执行sql命令
cursor.execute(sql, (names, ages))
except Exception as e:
print(e)
finally:
# 关闭游标
cursor.close()
# 提交
self.__db.commit()
# 关闭数据库连接
self.__db.close()
#数据生成,姓名,年龄,并调用数据插入方法
def data_update(self):
ret1 = random.choice(lst_first)
ret2 = random.choice(lst_last)
ret3 = random.choice(lst_last)
name = ret1 + ret2 + ret3
age = random.randint(18, 25)
self.linesinsert(name, age)
if __name__ == "__main__":
#创建实例化对象
db=DatabaseAccess()
#循环100次,插入100条数据
for record in range(1,101):
#调用方法
db.data_update()
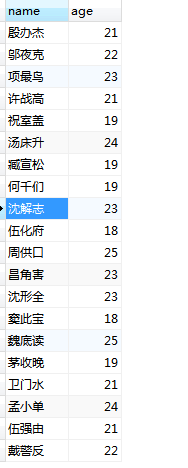
查看数据库表中数据,已经成功生成:


















 1135
1135

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











