







文章比较干,请备好水再看
今天,咱们不讲大道理,直接来点实战——教大家如何从0到1搞定Pandas数据分析的全流程!开干,咱玩的就是真实!

1. 数据导入——把“脏数据”请进来
首先得把数据请进来。数据来源可能是CSV、Excel,甚至数据库。这里咱们就直接模拟生成一份数据,数据里面充满了各种“坑”:
import pandas as pd
import numpy as np
# 模拟生成数据(注意:这里故意加了缺失值、异常值、重复数据以及格式混乱的日期)
data = {
"姓名": ["张三", "李四", "王五", "赵六", "小明", "小红", "老王", "张三", "赵六"],
"年龄": [25, 30, 22, np.nan, 29, 26, 28, 25, 200], # 缺失值 & 异常值
"工龄": [2, 5, 1, 8, np.nan, 3, -1, 2, 10], # 缺失值 & 错误数据(负数)
"薪资": [8000, 12000, 6000, 15000, 10000, 9000, 8500, 8000, 16000], # 重复行
"入职日期": ["2022-06-01", "2020/05/15", "2021-09-10", "2019-12-01",
"2023/01/01", "2021-08-15", "2018-03-10", "2022-06-01", "2019-12-01"], # 日期格式混乱
"部门": ["市场部", "技术部", "市场部", "技术部", "市场部", "人事部", "技术部", "市场部", "财务部"]
}
df = pd.DataFrame(data)
print("导入数据:\n", df)
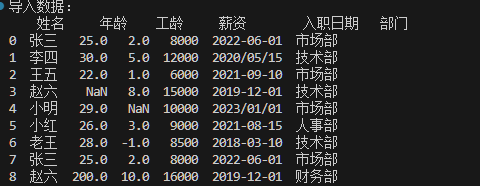
以下帮大家简单给出几个读取Excel、csv、数据库的示例代码,方便新手也能快速上手:
读取CSV文件
import pandas as pd
# 读取CSV文件(确保data.csv文件在当前目录下)
df_csv = pd.read_csv('data.csv')
print("CSV数据预览:")
print(df_csv.head())
说明:pd.read_csv() 非常好用,直接加载CSV数据。记得检查文件路径哦~
读取Excel文件
import pandas as pd
# 读取Excel文件的第一个工作表
df_excel = pd.read_excel('data.xlsx', sheet_name='Sheet1')
print("Excel数据预览:")
print(df_excel.head())
说明:pd.read_excel() 可以指定工作表名(或索引)。
从数据库读取数据
这里用SQLAlchemy作为数据库引擎示例,假设你使用的是SQLite数据库(其他数据库类似,只需更换连接字符串)。
import pandas as pd
from sqlalchemy import create_engine
# 创建数据库引擎(这里使用SQLite数据库,数据库文件为mydatabase.db)
engine = create_engine('sqlite:///mydatabase.db')
# 编写SQL查询语句
query = "SELECT * FROM table_name"
# 读取数据库中的数据
df_db = pd.read_sql(query, engine)
print("数据库数据预览:")
print(df_db.head())
说明:pd.read_sql() 可以直接执行SQL语句,将查询结果转成DataFrame,超方便!💡
2. 数据清洗🛁
数据清洗其实就是对症下药,让数据变得干净、标准,便于后续处理。这里主要包括:
2.1 缺失值处理
首先看看哪些地方数据“不完整”:
print("缺失值统计:\n", df.isnull().sum())
缺失值统计:
姓名 0
年龄 1
工龄 1
薪资 0
入职日期 0
部门 0
dtype: int64
通过缺失值统计可以发现年龄和工龄2列分别有1个缺失值。
处理策略:
年龄缺失值用中位数填充(受极端值影响小)工龄缺失值用部门内均值补全(让每个部门的数据更有说服力)
df["年龄"]=df["年龄"].fillna(df["年龄"].median())
df["工龄"]=df["工龄"].fillna(df.groupby("部门")["工龄"].transform("mean"))
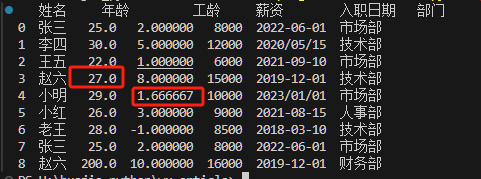
我们可以看到赵六缺失的年龄和
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











