






题目
给你一个整数数组 rewardValues,长度为 n,代表奖励的值。
最初,你的总奖励 x 为 0,所有下标都是 未标记 的。你可以执行以下操作 任意次 :
- 从区间
[0, n - 1]中选择一个 未标记 的下标i。 - 如果
rewardValues[i]大于 你当前的总奖励x,则将rewardValues[i]加到x上(即x = x + rewardValues[i]),并 标记 下标i。
以整数形式返回执行最优操作能够获得的 最大 总奖励。
示例 1:
- 输入:rewardValues = [1,1,3,3]
- 输出:4
- 解释:依次标记下标 0 和 2,总奖励为 4,这是可获得的最大值。
示例 2:
- 输入:rewardValues = [1,6,4,3,2]
- 输出:11
- 解释:依次标记下标 0、2 和 1。总奖励为 11,这是可获得的最大值。
提示:
1 <= rewardValues.length <= 20001 <= rewardValues[i] <= 2000
解题方法
1. 暴力解法
思路:暴力解法就是每个位置的元素都有被标记和不被标记两种可能,列举所有可能的序列和,然后取最大值。
需要特别注意一点,之后执行标记的操作的每一次奖励的值
rewardValues[i]都大于执行操作前的奖励之和x,因此可以知道rewardValues的标记顺序需要时单调递增的,需要预先对这个列表进行排序。
class Solution:
def maxTotalReward(self, rewardValues: List[int]) -> int:
x_list = [0]
rewardValues.sort() # 注意此处必须按照从大到小排序,否则因为reward机制限制,无法列举出逆序标记的情况
for i in rewardValues:
length = len(x_list)
for item in range(length):
if x_list[item] < i:
x_list.append(x_list[item] + i)
return max(x_list)
分析时间复杂度:
Python list是指针动态数组的形式存储的,排序的时间复杂度是,穷举所有序列的时间复杂度是
,因此总体时间复杂度是
2. 动态规划
通常,指数级的穷举法对应的优化算法是动态规划。
如何定义动态规划的状态数组呢?
通过定义可知,对升序排列后的rewardValue, 最大的奖励
,因此,可以定义奖励状态数组为:
,
其中每个元素
,
- 如果可以取得奖励值k, 则
,否则
状态是如何转移的呢?
以当前选中元素值
为例,则当前可获得的奖励范围是
。根据
的奖励状态。状态转移方程为:
class Solution:
def maxTotalReward(self, rewardValues: List[int]) -> int:
x_list = [0]
rewardValues.sort()
# 初始化状态数组
dp = [0] * (2 * rewardValues[-1])
dp[0] = 1
for i in rewardValues:
for j in range(2 * i - 1, i - 1, -1):
if dp[j - i] == 1:
dp[j] = 1
for i in range(len(dp) - 1, -1, -1):
if dp[i] == 1:
return i
分析时间复杂度
记rewardValues长度为n, 最大值为m,
- 数组排序时间复杂度
- 计算状态方程的过程事件复杂度为
- 寻找最大值时间复杂度是
- 综合来看时间复杂度为
(因为有nm,所以O(m)忽略不计)
分析空间复杂度
- 数组排序空间复杂度
(TimeSort, 如果C++快排的话是O(nlogn))
- 状态数组空间复杂度为
- 综合来看空间复杂度是
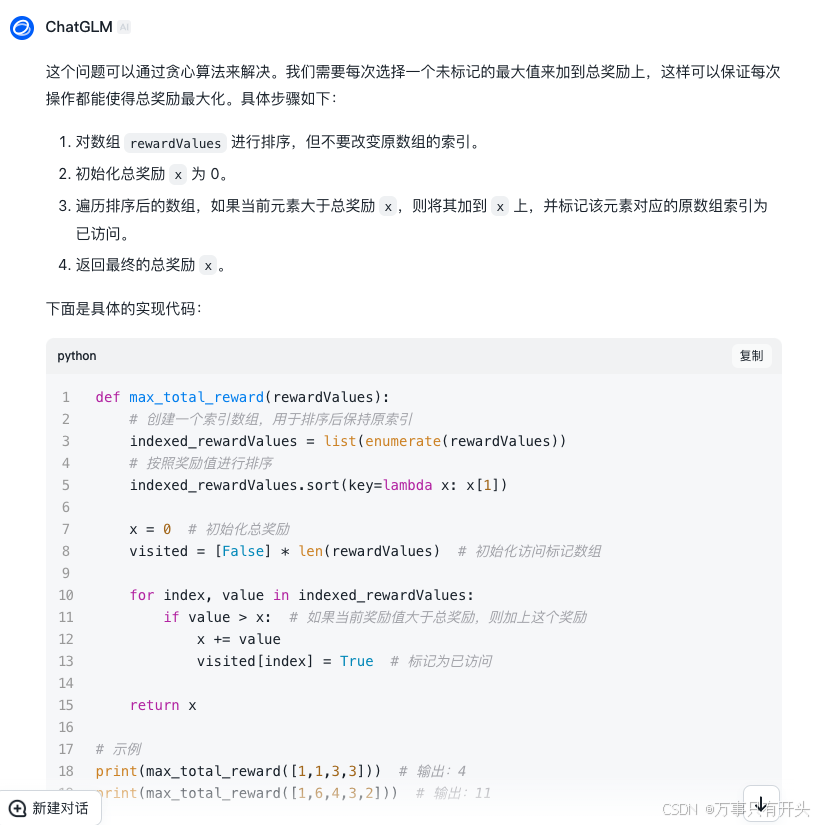
对比下AI:(智谱清言)
贪心算法思路错误,第二个例子验证不通过。
人类战胜AI的一天,哦吼~~


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









