







在日常【借鉴】他人的代码或者其他内容时,有时候我们拷贝出来会遇到形入下的文本
1. 192.30.253.113 github.com
2. 151.101.113.194 github.global.ssl.fastly.net
3. 151.101.184.133 assets-cdn.github.com
4. 151.101.184.133 raw.githubusercontent.com
5. 151.101.184.133 gist.githubusercontent.com
6. 151.101.184.133 cloud.githubusercontent.com
7. 151.101.184.133 camo.githubusercontent.com
8. 151.101.184.133 avatars0.githubusercontent.com
9. 151.101.184.133 avatars1.githubusercontent.com
10. 151.101.184.133 avatars2.githubusercontent.com
11. 151.101.184.133 avatars3.githubusercontent.com
12. 151.101.184.133 avatars4.githubusercontent.com
13. 151.101.184.133 avatars5.githubusercontent.com
14. 151.101.184.133 avatars6.githubusercontent.com
15. 151.101.184.133 avatars7.githubusercontent.com
16. 151.101.184.133 avatars8.githubusercontent.com
如果有几百行几千行,我们手动一行一行删除前面的1.、2.之类的前缀是非常不现实的,所以我们就新建一个html文件,然后写一点东西进去:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title></title>
<script type="text/javascript">
function f(obj){
document.getElementById("d1").innerHTML='';
// 获取文本的内容
var textVa = obj.value;
// 逐行获取,并将其第一个.以及前面的东西删掉
textVa.trim().split('\n').forEach(function(v, i) {
v = v.substring(v.indexOf('.') + 1, v.length)+'\n';
document.getElementById("d1").innerHTML += v;
})
}
</script>
</head>
<body>
<textarea name="getStr" id="1" rows="4" cols="100"></textarea>
<button type="submit" onclick="f(document.getElementById('1'))">转换</button>
<textarea name="result" id="d1" rows="4" cols="100"></textarea>
</body>
</html>
然后在浏览器中打开
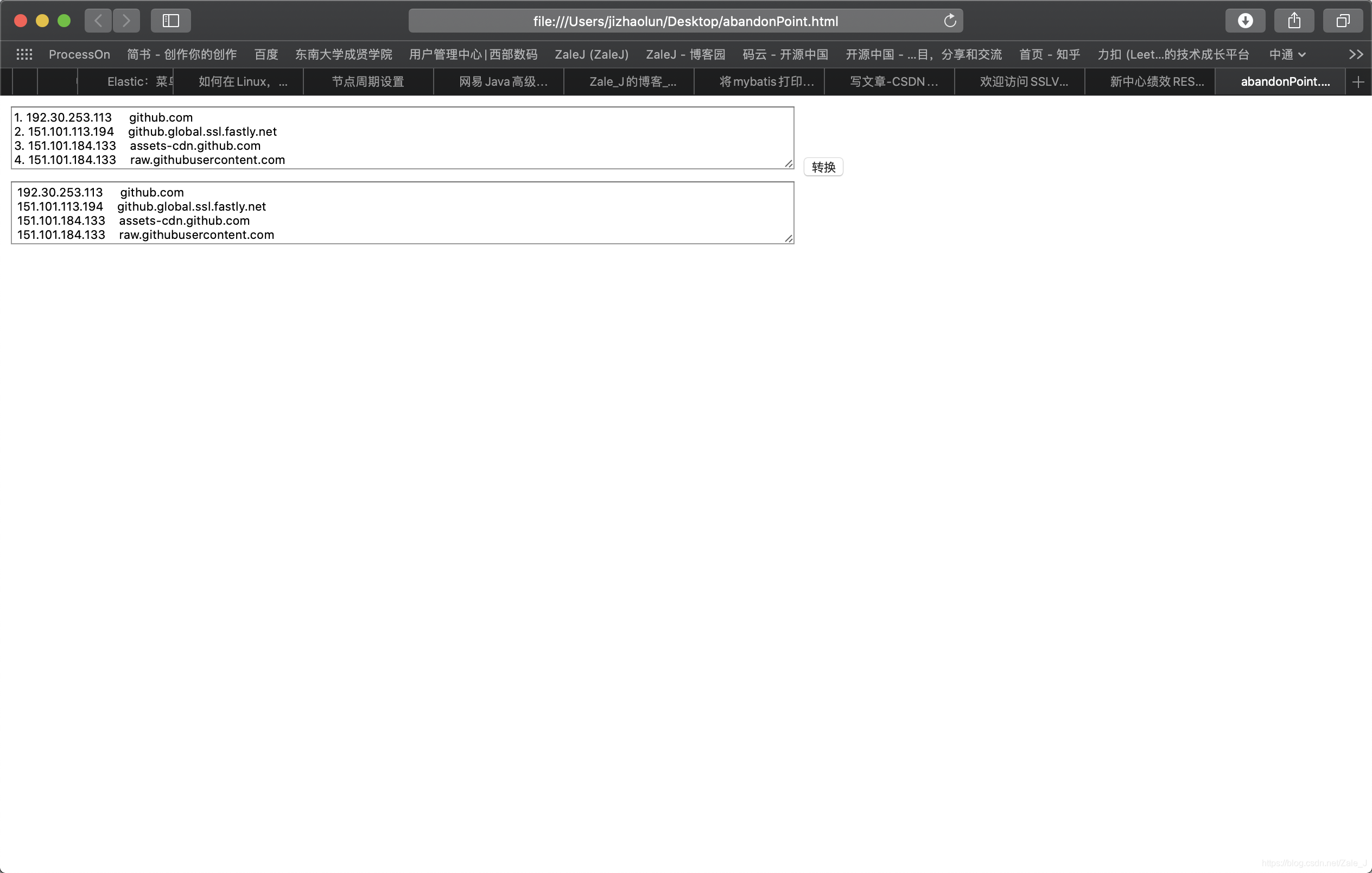
上面是处理前的,下面是处理后的,可以看到大致完成了这么一个效果。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









