






OCR技术现已广泛应用于金融、航天、教育、医疗等领域。商汤科技、旷视科技、云从科技、依图科技、百度、阿里、腾讯等大量科技公司都在高薪招聘相关人才。
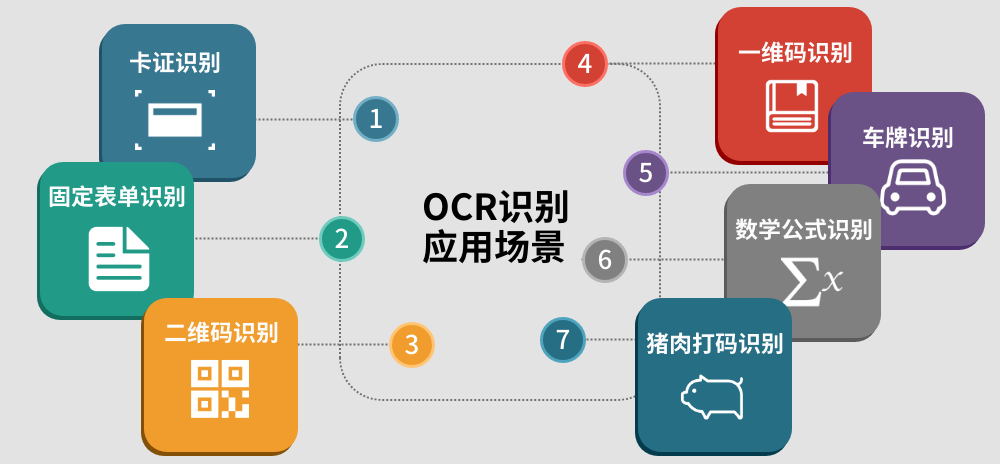
OCR任务的难题有很多,文字识别准确率的长尾效应、字体、图像质量问题、卷曲折叠等等。其中,数学公式识别是一个非常难解决的问题。

公式识别除了识别出字符,还需要通过字符之间的相对位置、大小及数学符号,识别出其中的逻辑包含关系,才能得到正确的表达式。
现在,我们请到了赵明明老师,他将在1个小时内带同学们揭开概念上的迷雾,直击算法内核。通过将原理讲解,计算流梳理,代码运行三种方式紧密结合,带你快速掌握数学公式识别的核心。

原价:¥299元
限时早鸟价:9.8元
解决你的OCR数学公式识别难题
仅限前200人
↓ ↓ ↓

赶紧长按二维码进入学习群吧
3招解决你的OCR数学公式识别难题,让你迅速脱颖而出!带你迅速掌握以下知识:
1、掌握OCR应用场景与职业需求
2、学会数学公式的实用场景显示
3、了解attention的思路原理、计算流与实战
金牌讲师带你学习

赵明明
专注算法10年
国内top数据类企业 图像算法leader
参与边境安检,银联竞标等国家级基础人工智能项目
公开课详情
上课内容:《3招解决你的OCR数学公式识别难题》
上课时间:3月10日(周二)晚8点20:00-21:30
原价:¥299元
限时早鸟价:9.8元
解决你的OCR数学公式识别难题
仅限前200人
赶紧长按二维码进入学习群吧
↓ ↓ ↓
扫描二维码立即9.8元抢购(限200人)
更多AI工程师成长规划、BAT大厂面试技巧等干货,直播等你来聊!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









