






视学算法报道
机器之心编辑部
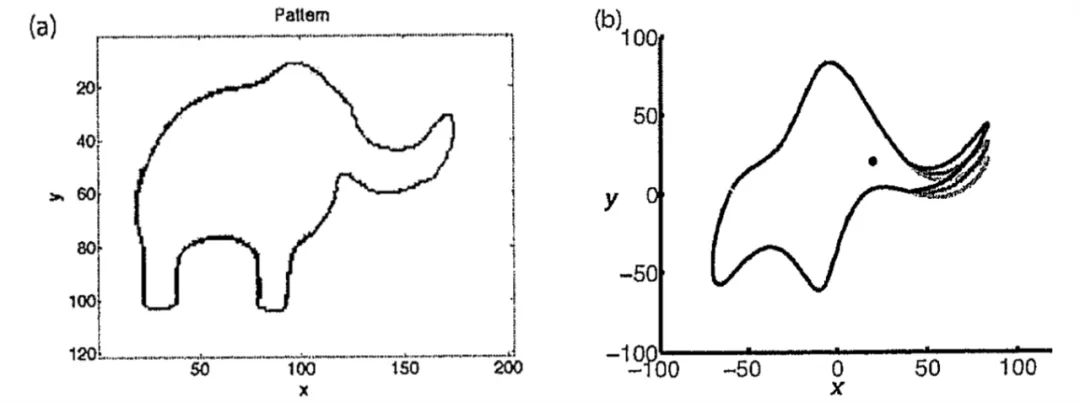
一个参数画出大象。
据说,冯 · 诺依曼有次参加一个会议,某物理研究员在报告一个研究进展,用了一个非常复杂的模型,试图论证实验数据点都落在同一条曲线上,符合模型预期。于是冯 · 诺依曼就说了一句,还不如说这些点都在同一个平面上。最后,冯 · 诺依曼留下了一句名言:「With four parameters I can fit an elephant, and with five I can make him wiggle his trunk.」
这就是冯 · 诺依曼经典的「四个参数画大象,五个参数鼻子晃」的故事。
2010 年,来自德国马克斯普朗克分子细胞生物学和遗传学研究所和欧洲分子生物学实验室的三位研究者发表的论文实现了四个参数画大象,具体如下:
图源:https://publications.mpi-cbg.de/Mayer_2010_4314.pdf
相同的思想,近日,一篇发表于 2019 年 4 月的老论文《 Real numbers, data science and chaos: How to fit any dataset with a single parameter 》,在推特上又引来一波讨论量。论文作者 Laurent Boué 现为微软高级机器学习科学家,他讲述了「如何使用单个参数拟合任何数据集」。

论文地址:https://arxiv.org/pdf/1904.12320.pdf
发帖者为普林斯顿博士生、DeepMind 研究科学家实习生 Miles Granmer,他表示,「该论文提供了一个具有单个参数的标量函数,并且这个函数是可微和连续的!」

对于这项研究,有人认为:「从技术上讲,这篇文章存在一些『作弊』,因为该论文使用了任意精度的浮点数。由于浮点数所需的位数非常少,因此本文可能是压缩表示的一个很好的候选者。 但它绝对不是『单一』参数。我同意这篇论文是一种将数据集编码为数字,然后将其解码回重建单个点的聪明方法。」
还有人对这项研究的拟合参数标准误差产生了兴趣,如果它是单个参数,误差将有多大?
还有人表示:「1 个参数的连续可微函数可以生成无限 VC 维族。这篇论文似乎是该技巧的某个版本。」

论文内容介绍
该论文介绍了如何通过具有单个实值参数的标量函数(连续、可微...)来近似化任何不同模态(时间序列、图像、声音...)的数据集。基于混沌理论的基本概念,研究者采用教学(pedagogical)方法来演示如何调整这个实值参数,以实现对所有数据样本的任意精度拟合。
现实世界的数据有各种各样的形状和大小,其模式包括从传统的结构化数据库模式到非结构化媒体源,如视频源和录音。然而,任何数据集最终都可以被认为是一个数值列表 X = [x_0, · · · , x_n] ,该列表描述了数据内容而忽略了数据底层模态。并且该论文旨在证明任何数据集 X 的所有样本都可以通过一个简单的微分方程重现:

其中 α ϵ R 是要从数据中学习的实值参数,x ϵ [0, · · · , n] 取整数值。(τ ϵ N 是一个常数,可有效控制所需的准确率)。按照「拟合大象」的传统,该研究首先展示了如何通过选择合适的α值生成不同的动物形状,如图 1 所示。

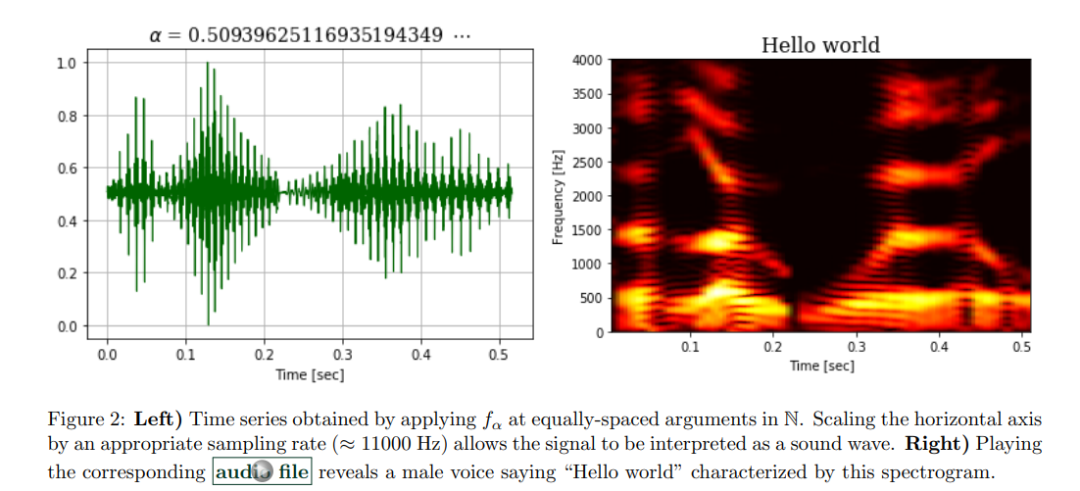
在演示完 f_α 可以生成任何类型的上述涂鸦绘图之后,该论文继续使用文字「Hello world」进行了展示,以进一步说明该方法的功能。下图 2 展示了如何使用精心选择的 α 值来生成复杂的高维声学信号,编码实际表达的是「Hello world」。
在图像这种数据模态上,随着专用硬件和新型神经网络架构的不断涌现,人们普遍认为可用的大规模标记训练数据已成为促使计算机视觉「成熟」的最重要因素之一。
在这种情况下,CIFAR-10 数据集被认为是衡量新学习算法性能的有力标准。该研究表明:如下图 3 所示,总是能够找到一个α值,使得 f_α能够构建出反映 CIFAR-10 类别的人工图像。

基于上述几个模态的例子,该论文得出结论:一个具有简单且可微公式的模型 f_α能够产生任何类型的语义相关散点图、音频或视觉数据(文本也类似),而只需要单个实值参数。这一点就引起了研究者们的质疑。
此外,该论文中阐述了该方法无法实现泛化的事实。这是因为该方法中所有信息都是被直接编码的,没有任何的压缩或「学习」。从数学的角度看,实数有无限多个,因此不应与编程语言实现的有限精度的数据类型混淆。基于此,f_α不可能实现真正的泛化,下图 9 就是一个例子。
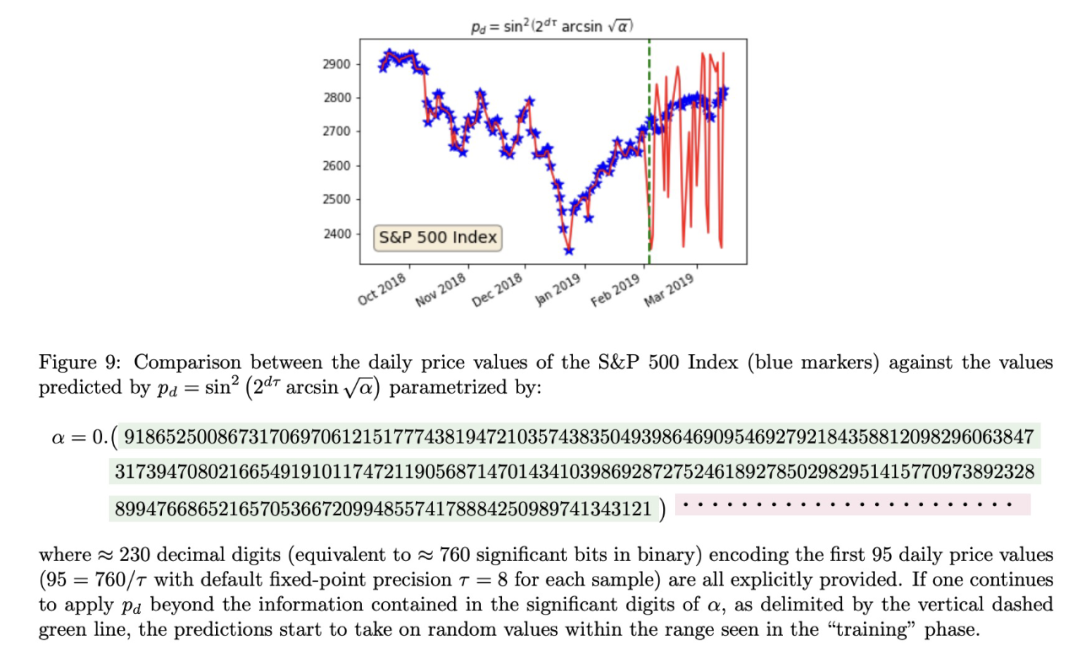
对此,你有什么看法呢?
© THE END
转载请联系原公众号获得授权
投稿或寻求报道:content@jiqizhixin.com


点个在看 paper不断!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









