






点击上方“视学算法”,选择加"星标"或“置顶”
重磅干货,第一时间送达
行早 发自 凹非寺
量子位 报道 | 公众号 QbitAI
今年NeurIPS大会论文已经放榜,终于可以学习一下大佬们的研究了。
不过,打开电脑,随便点开一篇,就是一大段密密麻麻的文字糊脸……只是摘要就有这么长,还有2300多篇,这工作量实在劝退。

能不能让论文们都做一道经典的语文题:“用一句话概括全文内容”?
还真可以。
最近Reddit上的一位博主发布了一篇今年的NeurIPS大会论文汇总,其中的每篇论文下方(红框中)都有一句由AI生成的高度凝练的总结。
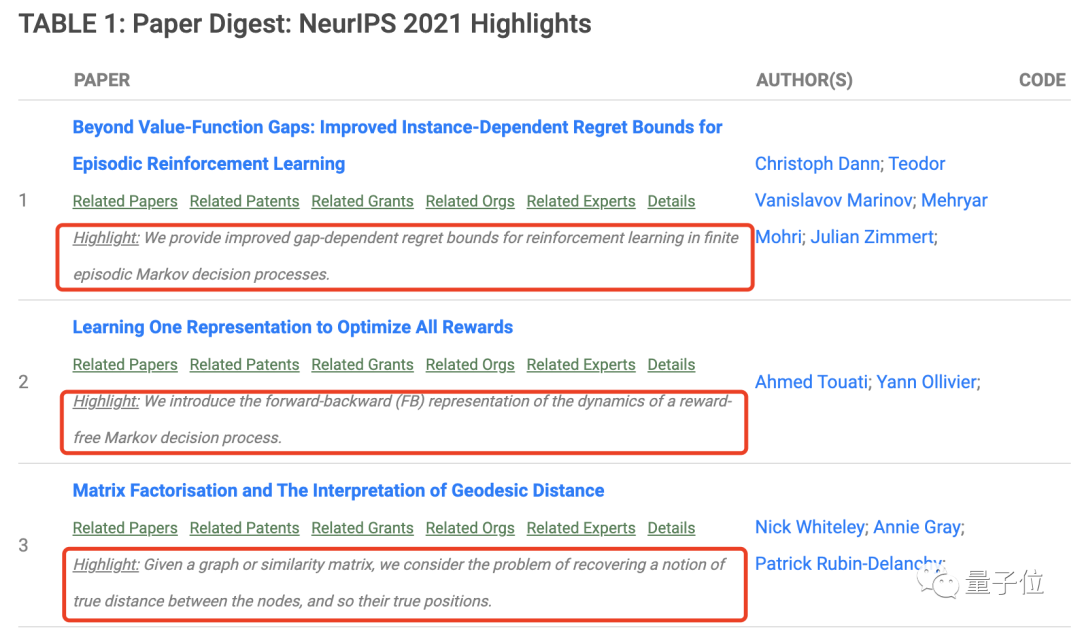
而这款AI文本分析软件,其实就是东京工业大学团队开发的Paper Digest。
它号称能帮你把论文阅读时间减少到3分钟:

除了总结论文内容以外,它还可以筛选出已经发布代码的论文。
同样,这次NeurIPS大会上的200多篇已发布代码的文章也被汇总了出来(可能会有疏漏)。
点击“code”,就可以直接跳转到相应的GitHub页面。

AI如何做好概括题
那这个AI文本分析神器应该怎么用呢?
很简单,先打开Paper Digest的官网(见文末链接)。
完成一些注册工作后,滑到一个搜索框的界面:

在这个搜索框里填上你要总结概括的论文的DOI号。
DOI号就像论文的身份证号,是独一无二的。以随便打开的一篇论文为例,它长这样(红框中即为DOI号):

填完之后,点击“Digest”就开始总结了:

只需几秒钟,就会有一句话的总结输出,你也可以选择一个最合适反馈给Paper Digest,帮他们丰富数据库。

除了输入DOI号,如果你有本地的论文PDF文件,也可以直接导入。
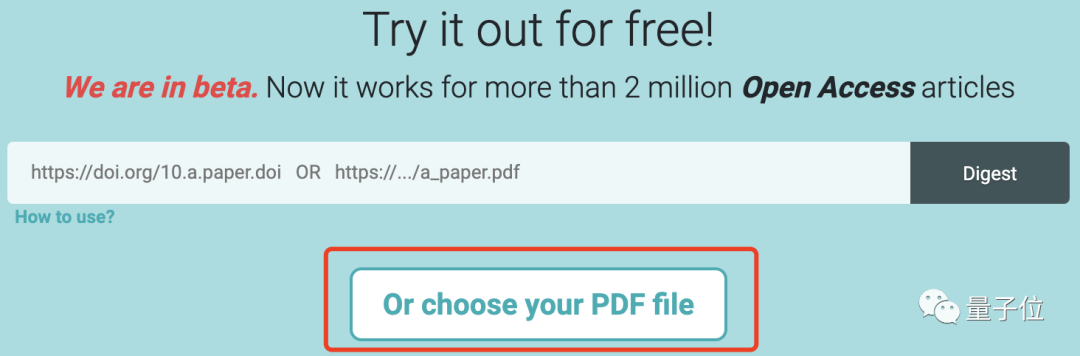
是不是很方便?
其实这样方便好用的模型还不止一种。
比如,在一款免费学术搜索引擎Semantic Scholar里,也加入了一个类似的高度概括AI:TLDR。
TLDR(Too Long,Don’t Read),其实就是太长不看的意思……
在Semantic Scholar上搜索论文时,带有TLDR(红框)标志的就是AI生成的一句话总结。

具体到方法原理上,我们不妨以TLDR为例一起来看看。
举个例子,下图中上边的格子中是摘要,简介,结论中相对重要的段落和句子。TLDR会标记出突出的部分,然后组合成一个新的句子。

它的训练逻辑也很容易理解。
简单来说,就是先确定一个标准答案,然后把标准答案打乱,再让TLDR尝试复原。
这和人类提炼概括的过程也很像。
概括本身也需要忽视一些干扰,然后提取出最重要的部分。
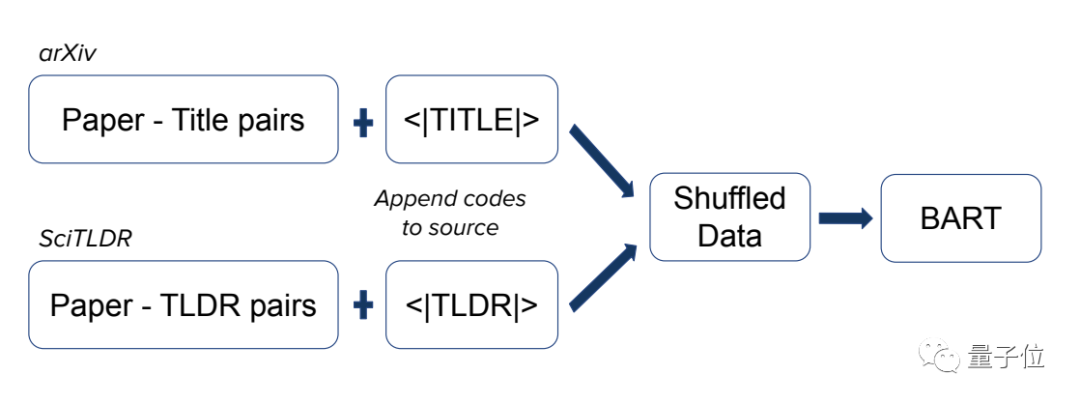
所以在训练之前要准备两个数据库,也就是标准答案:一个是SciTLDR,它包含接近2000篇计算机科学相关论文,每篇论文都有一个最好的总结。
另一个是论文-标题对数据库。由于标题中一般有很多重要的语句,对生成TLDR来说很有帮助。
将这两个数据库分别加上控制码“<TITLE>”和“<TLDR>”之后进行混合,送入BART模型。
最后的BART模型是一个基于Transformer的预训练sequence-to-sequence去噪自编码器,它的训练步骤主要有两步:
首先用任意噪声破坏函数文本,相当于把标准答案打乱。
然后让模型学习重建原来的文本。
这整个学习策略就是CATTS。
来看看效果如何。
下图中TLDR-Auth是论文作者本人写的总结,TLDR-PR是本科学生读完论文写的总结。
BART和CATTS分别是原有模型和CATTS模型给出的总结。

从重合度看起来效果还是不错的。
相关推荐还需下功夫
不过,不论是TLDR还是Paper Digest,都有不完善的地方。
TLDR只针对计算机科学的论文进行了总结。
而对于Paper Digest,网友表示它虽然概括做得很好,但是相关推荐实在是不行,今后仍需改进。

而且Paper Digest并不适用于所有论文。
目前,它只对来源于开放获取期刊的论文或者本地PDF文件导入的论文有效。
但是不论哪种文本分析AI,都可以快速获取论文高度凝练的概括信息。
如果大家想快速了解今年NeurIPS大会的论文情况,可以从文末链接中找到这次的汇总。
参考链接:
[1]https://www.reddit.com/r/MachineLearning/comments/r0gnej/r_one_sentence_highlight_for_every_neurips2021/
[2]https://aclanthology.org/2020.findings-emnlp.428.pdf
[3]https://www.paperdigest.org/2021/11/neurips-2021-highlights/
[4]https://www.paper-digest.com/
— 完 —
本文系网易新闻•网易号特色内容激励计划签约账号【量子位】原创内容,未经账号授权,禁止随意转载。


点个在看 paper不断!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









