







公司项目下一步要用到flink,花了一周还多的时间看了flink的文档(官网给的文档过于简单,刚开始搞,根据自己的需求写demo,api各种搜各种看,花的时间有点多,好在领导并没有怪罪,就像当初搭建微服务架构一样,万事开头难了,加油了),为接下来的项目开发做技术准备铺垫,对于常用的几个api写了几个小demo,在下面的讲解中分享给大家(主要是flink的用法格式),flink和storm的结构有些不同,刚开始搞这个可能会觉得生涩,熟悉了之后只能用两个字概括——好使。
首先讲解几个概念(函数只提理解,用法在官网文档中十分清楚明白,知识点只讲重点理解):
ReductionFuction:tuple=>tuple 通常在接收到数据源传来的数据时对数据进行简单的格式化
MapFunction:String=>tuple 在对数据流进行操作时,对流进行格式化
FlatMapFunction(拆流):String=>SomeThing 同上
Watermark水位线:通常处理含有事件事件的数据,Watermark触发的规则:当该条数据的EventTime<新数据的Watertime时,触发窗口的聚合
窗口分配器WindowAssinger:这里只列举AssignerWithPeriodicWatermark的实现,这个用的很多
public static class SessionTimeExtract implements AssignerWithPeriodicWatermarks<Order> {
private final Long maxOutOfOrderness = 3500L;
private Long currentMaxTimestamp = 0L;
private SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
@Nullable
@Override
public Watermark getCurrentWatermark() {
return new Watermark(currentMaxTimestamp - maxOutOfOrderness);
}
@Override
public long extractTimestamp(Order order, long l) {
long timestamp = order.rowtime;
currentMaxTimestamp = Math.max(timestamp, currentMaxTimestamp);
return timestamp;
}
}这里定义maxOutOfOrderness乱序时间为3.5秒,两个实现的函数,extractTimestamp()提取数据流中的事件时间,getCurrentWatermark(),根据计算获取当前时间的水位线。
窗口Window:
如果大家用no-sql数据库例如mongodb、elasticsearch比较多的话,那么对聚合一定不陌生。而flink中的窗口和非关系数据库中的聚合十分的相近。在flink中常用的窗口有TumbleWindow、SlidingWindow、sessionWindow。
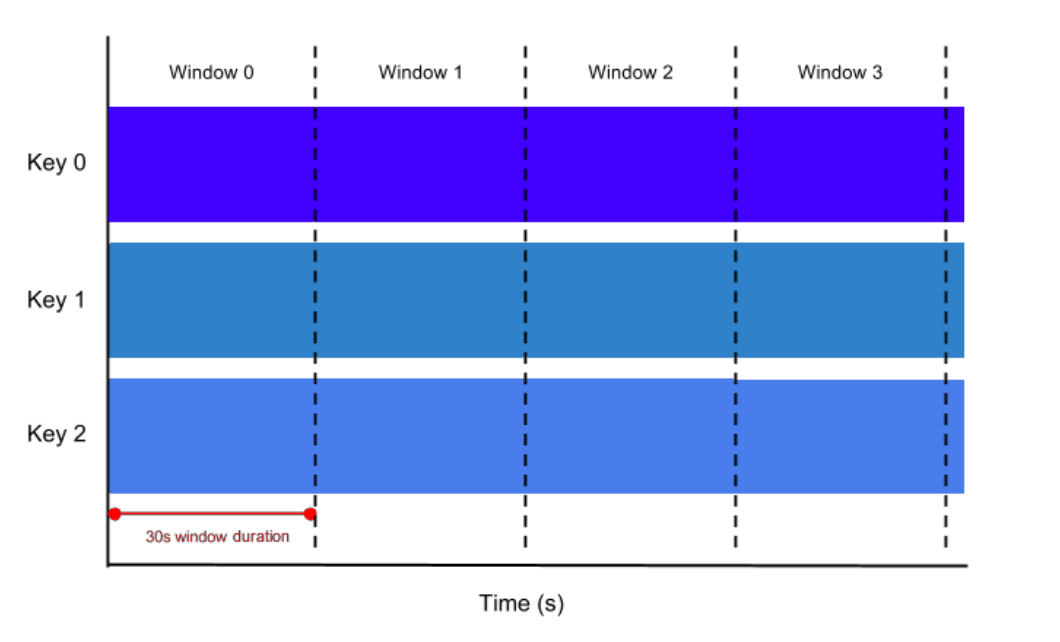
滚动窗口(TUMBLE)将每个元素分配到一个指定大小的窗口中。通常滚动窗口有一个固定的大小,并且不会出现重叠。
例如:如果指定了一个5分钟大小的滚动窗口,无限流的数据会根据时间划分成[0:00 - 0:05), [0:05, 0:10), [0:10, 0:15),… 等窗口。如下图,展示了一个大小划分为30秒的滚动窗口(无重叠)
import com.alibaba.fastjson.JSON;
import com.entity.CarEntity;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.AssignerWithPeriodicWatermarks;
import org.apache.flink.streaming.api.functions.windowing.WindowFunction;
import org.apache.flink.streaming.api.watermark.Watermark;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer08;
import org.apache.flink.util.Collector;
import javax.annotation.Nullable;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.LinkedList;
import java.util.Properties;
public class ReviewCarWindow {
public static void main(String[] args) throws Exception{
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
env.getConfig().setAutoWatermarkInterval(2000);
env.setParallelism(1);
Properties properties = new Properties();
properties.setProperty("bootstrap.servers","localhost:9092");
properties.setProperty("zookeeper.connect","localhost:2181");
properties.setProperty("group.id","test");
FlinkKafkaConsumer08<String> consumer = new FlinkKafkaConsumer08<>("carwindow", new SimpleStringSchema(), properties);
DataStream<Tuple3<String,Long, Integer>> raw = env.addSource(consumer).map(new MapFunction<String, Tuple3<String,Long,Integer>>() {
@Override
public Tuple3<String, Long, Integer> map(String result) throws Exception {
CarEntity carEntity = JSON.parseObject(result, CarEntity.class);
return new Tuple3<String,Long,Integer>(carEntity.getCarKind(),carEntity.getTimeStamp(),carEntity.getCarSum());
}
}).assignTimestampsAndWatermarks(new CarTimestampExtractor());
DataStream<String> window = raw.keyBy(0)
.window(TumblingEventTimeWindows.of(Time.seconds(3)))
.allowedLateness(Time.seconds(5))
.apply(new WindowFunction<Tuple3<String, Long, Integer>, String, Tuple, TimeWindow>() {
@Override
public void apply(Tuple tuple, TimeWindow window, Iterable<Tuple3<String, Long, Integer>> input, Collector<String> out) throws Exception {
LinkedList<Tuple3<String, Long, Integer>> data = new LinkedList<>();
for (Tuple3<String,Long,Integer>item:input){
data.add(item);
}
Integer carSum=0;
for (Tuple3<String,Long,Integer> item:input){
carSum=carSum+item.f2;
}
SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
String msg = String.format("key:%s, window:[ %s , %s ), elements count:%d, elements time range:[ %s , %s ]", tuple.getField(0)
, format.format(new Date(window.getStart()))
, format.format(new Date(window.getEnd()))
, data.size()
, format.format(new Date(data.getFirst().f1))
, format.format(new Date(data.getLast().f1))
) + "|||" + carSum;
out.collect(msg);
}
});
window.print();
env.execute();
}
public static class CarTimestampExtractor implements AssignerWithPeriodicWatermarks<Tuple3<String,Long,Integer>>{
Long maxOutOfOrderness=3500L;
Long currentMaxTimeStamp=0L;
@Nullable
@Override
public Watermark getCurrentWatermark() {
System.out.println();
return new Watermark(currentMaxTimeStamp-maxOutOfOrderness);
}
@Override
public long extractTimestamp(Tuple3<String, Long, Integer> element, long l) {
Long timeStamp=element.f1;
currentMaxTimeStamp=Math.max(timeStamp,currentMaxTimeStamp);
return timeStamp;
}
}
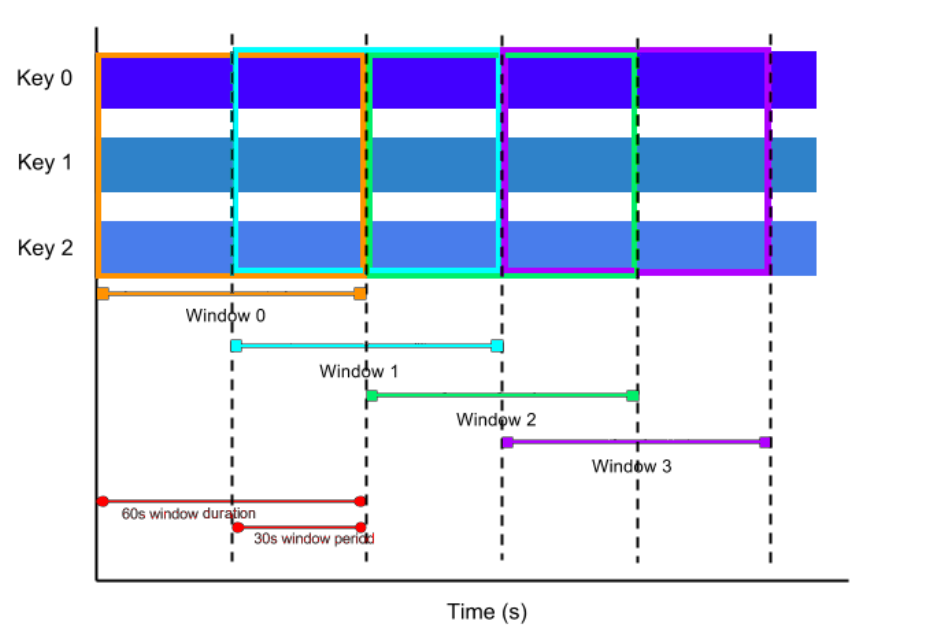
滑动窗口 Sliding Window(含有数据重叠,参数中配置窗口的大小及滑动大小)。不同于滚动窗口,滑动窗口的窗口可以重叠。滑动窗口有两个参数:size 和slide。size为窗口的大小,slide为每次滑动的步长。如果slide < size,则窗口会重叠,每个元素会被分配到多个窗口。如果 slide = size,则等同于滚动窗口(TUMBLE)。如果 slide > size,则为跳跃窗口,窗口之间不重叠且有间隙。
通常情况下大部分元素符合多个窗口情景,窗口是重叠的。因此,滑动窗口在计算移动平均数(moving averages)时很实用。例如,计算过去5分钟数据的平均值,每10秒钟更新一次,可以设置size=5分钟slide=10秒钟。
下图展示了一个窗口大小为1分钟,间隔为30秒的滑动窗口。
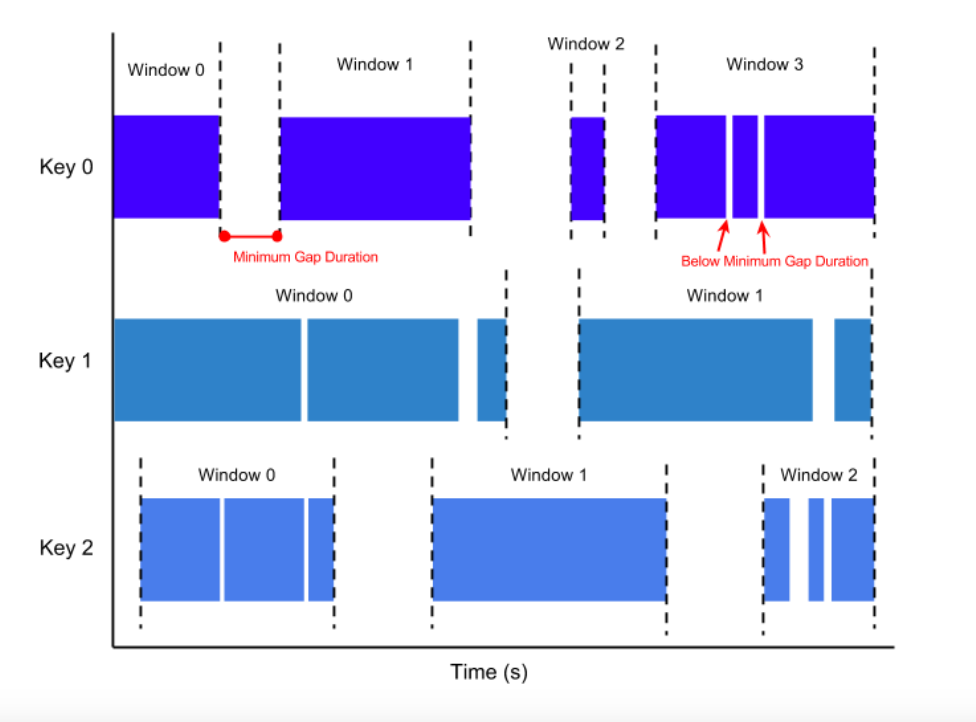
会话窗口通过session活动来对元素进行分组。会话窗口与滚动窗口和滑动窗口相比,没有窗口重叠,没有固定窗口大小。相反,当它在一个固定的时间周期内不再收到元素,即会话断开时,这个窗口就会关闭。
会话窗口通过一个间隔时间(gap)来配置,这个间隔定义了非活跃周期的长度。例如,一个表示鼠标点击活动的数据流可能具有长时间的空闲时间,并在其间散布着高浓度的点击。 如果数据在最短指定的间隔持续时间之后到达,则会开始一个新的窗口。通过淘宝京东的商品访问更能去理解这个窗口,例如我们在购物时,对不同的接口例如食品类、化妆品进行请求,实时统计用户在哪个请求中停顿的时间更长,从而知道该用户对哪块商品更感兴趣,为用户更多的推荐该类商品,每次请求都存在gap,可以把gap为一条线段的若干个分割点,分割出来的线段即为该窗口的长度。参数中可配gap的长度。
StreamSql: flink中加入了sql,简直十分完美,本来50行的代码一条sql语句就能完成,而且不用考虑代码的效率,十分好用,并且sql是每一位程序员的入门课必修。贴出实例:
import com.alibaba.fastjson.JSON;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.AssignerWithPeriodicWatermarks;
import org.apache.flink.streaming.api.watermark.Watermark;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer08;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.TableEnvironment;
import org.apache.flink.table.api.java.StreamTableEnvironment;
import org.apache.flink.table.api.java.Tumble;
import javax.annotation.Nullable;
import java.sql.Timestamp;
import java.text.SimpleDateFormat;
import java.util.Properties;
public class KafkaTable {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
env.setParallelism(1);
StreamTableEnvironment tEnv = TableEnvironment.getTableEnvironment(env);
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "127.0.0.1:9092");
properties.setProperty("zookeeper.connect", "127.0.0.1:2181");
properties.setProperty("group.id", "test");
FlinkKafkaConsumer08<String> consumer08 = new FlinkKafkaConsumer08<>("sqltime", new SimpleStringSchema(), properties);
DataStream<Order> raw = env.addSource(consumer08).map(new MapFunction<String, Order>() {
@Override
public Order map(String s) throws Exception {
if (s.contains("@")) {
String[] split = s.split("@");
Integer p1 = Integer.parseInt(split[0]);
String p2 = split[1];
Integer p3 = Integer.parseInt(split[2]);
Long p4 = System.currentTimeMillis();
return new Order(p1, p2, p3, p4);
} else {
Order order = JSON.parseObject(s, Order.class);
if (order.rowtime == null)
order.rowtime = System.currentTimeMillis();
return order;
}
}
}).assignTimestampsAndWatermarks(new SessionTimeExtract());
Table table = tEnv.fromDataStream(raw, "user,product,amount,rowtime.rowtime");
tEnv.registerTable("tOrder", table);
Table table1 = tEnv.scan("tOrder")
.window(Tumble.over("10.second").on("rowtime").as("w"))
.groupBy("w,user,product")
.select("user,product,amount.sum as sum_amount,w.start");
String sql_tumble = "select user ,product,sum(amount) as sum_amount from tOrder group by TUMBLE(rowtime, INTERVAL '10' SECOND),user,product";
String sql_hope = "select user ,product,sum(amount) as sum_amount from tOrder group by hop(rowtime, INTERVAL '5' SECOND, INTERVAL '10' SECOND),user,product";
String sql_sesstion = "select user ,product,sum(amount) as sum_amount from tOrder group by session(rowtime, INTERVAL '12' SECOND),user,product";
String sql_window_start = "select tumble_start(rowtime, INTERVAL '10' SECOND) as wStart,user ,product,sum(amount) as sum_amount from tOrder group by TUMBLE(rowtime, INTERVAL '10' SECOND),user,product";
Table table2 = tEnv.sqlQuery(sql_window_start);
DataStream<Tuple2<Boolean, Result>> resultStream = tEnv.toRetractStream(table2, Result.class);
resultStream.map(new MapFunction<Tuple2<Boolean, Result>, String>() {
@Override
public String map(Tuple2<Boolean, Result> tuple2) throws Exception {
return "user:" + tuple2.f1.user + " product:" + tuple2.f1.product + " amount:" + tuple2.f1.sum_amount + " wStart:" + tuple2.f1.wStart;
}
}).print();
env.execute();
}
public static class Order {
public Integer user;
public String product;
public int amount;
public Long rowtime;
public Order() {
super();
}
public Order(Integer user, String product, int amount, Long rowtime) {
this.user = user;
this.product = product;
this.amount = amount;
this.rowtime = rowtime;
}
}
public static class Result {
public Integer user;
public String product;
public int sum_amount;
public Timestamp wStart;
public Result() {
}
}
public static class SessionTimeExtract implements AssignerWithPeriodicWatermarks<Order> {
private final Long maxOutOfOrderness = 3500L;
private Long currentMaxTimestamp = 0L;
private SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
@Nullable
@Override
public Watermark getCurrentWatermark() {
return new Watermark(currentMaxTimestamp - maxOutOfOrderness);
}
@Override
public long extractTimestamp(Order order, long l) {
long timestamp = order.rowtime;
currentMaxTimestamp = Math.max(timestamp, currentMaxTimestamp);
return timestamp;
}
}
}














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









