







TSDB
基础概念
时序数据库:提供高效存取时序数据和统计分析功能的数据管理系统,广泛应用于物联网(IoT)设备监控系统、企业能源管理系统(EMS)、生产安全监控系统和电力检测系统等行业场景。
TSDB特点
-
高吞吐量写入
-
数据分级存储
-
高压缩率减少存储空间
-
多维度查询能力
-
高效聚合能力
OpenTSDB
-
Opentime series database
-
是基于Hbase的分布式的,可扩展的时间数据库
-
它是建立在Hbase上的一层数据读写服务
How does OpenTSDB work?
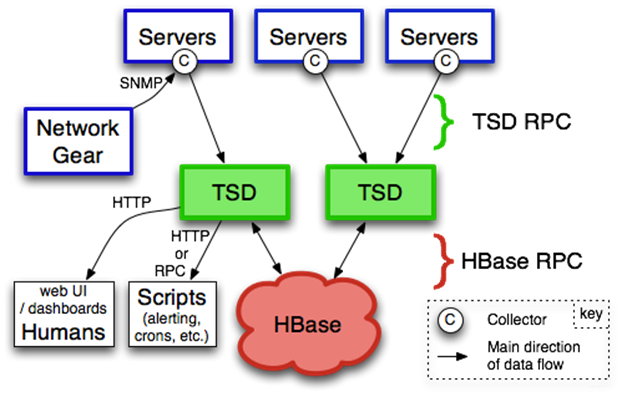
OpenTSDB框架
-
Servers:就是服务器了,C就是指Collector,通过Collector收集数据,推送数据;
-
TSD:TSD是对外通信的无状态的服务,Collector可以通过TSD简单的RPC协议推送监控数据;
-
TSD还提供了一个webUI页面供数据查询;另外也可以通过脚本查询监控数据,对监控数据做报警;
-
HBase:TSD收到监控数据后,是通过AsyncHbase这个库来将数据写入到HBase;AsyncHbase是完全异步、非阻塞、线程安全的Hbase客户端,使用更少的线程、锁以及内存,可以提供更高的吞吐量,特别对于大量的写操作。
名词解释
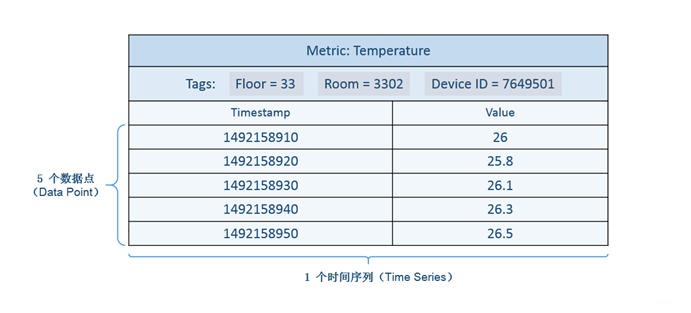
In OpenTSDB, a time series data pointconsists of:
-
A metric name.
-
A UNIX timestamp (seconds or millisecondssince Epoch).
-
A value (64 bit integer orsingle-precision floating point value), a JSON formatted event or ahistogram/digest.
-
A set of tags (key-value pairs) thatdescribe the time series the point belongs to.
{
"metric":"temperature",
"timestamp":1567675709879,
"value":20.5,
"tags":{
"host":"device-1"
}
}
数据查询
监控场景中,我们可以这样定义一个监控指标:

OpenTSDB支持的查询场景为:
指定指标名称和时间范围,给定一个或多个标签名称和标签的值作为条件,查询出所有的数据。
以上面那个例子举例,我们可以查询:
- sys.cpu.user (host=,cpu=)(1465920000<= timestamp < 1465923600)
查询凌晨0点到1点之间,所有机器的所有CPU核上的用户态CPU消耗。
- sys.cpu.user (host=10.101.168.111,cpu=*)(1465920000<= timestamp < 1465923600)
查询凌晨0点到1点之间,某台机器的所有CPU核上的用户态CPU消耗。
- sys.cpu.user (host=10.101.168.111,cpu=0)(1465920000<= timestamp < 1465923600)
查询凌晨0点到1点之间,某台机器的第0个CPU核上的用户态CPU消耗。
存储优化
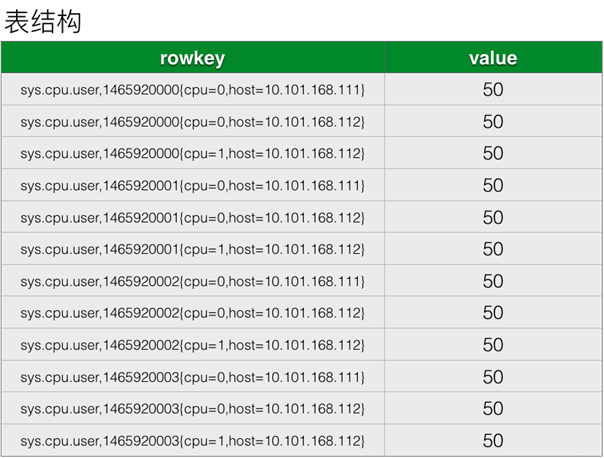
rowkey采用metricname + timestamp + tags的组合,唯一确定一个指标值。
核心优化:缩短rowkey
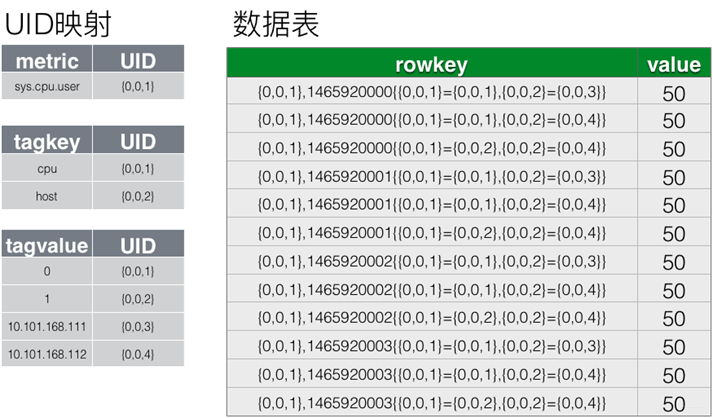
OpenTSDB采用的策略是:为每个metric、tag key和tagvalue都分配一个UID,UID为固定长度三个字节。
Rowley的长度大大的缩短了,好处:
-
节省存储空间
-
提高查询效率:减少key匹配查找的时间
-
提高传输效率:不光节省了从文件系统读取的带宽,也节省了数据返回占用的带宽,提高了数据写入和读取的速度。
-
缓解内存压力:String存储的metric name、tagkey或tag value,现在均可以用3个字节的byte array替换,大大节省了内存占用
其它存储优化:减少Key-Value数

合并行和列,进一步缩短存储量。
其它存储优化:并发写优化
进行预分桶,避免写热点

常用HTTP API
插入数据:/api/put

查询数据:/api/query

其它HTTP API

具体参考官网:
http://opentsdb.net/docs/build/html/api_http/index.html
OpenTSDB安装
参考官网:
http://opentsdb.net/docs/build/html/installation.html
其它TSDB对比
TSDB Ranking
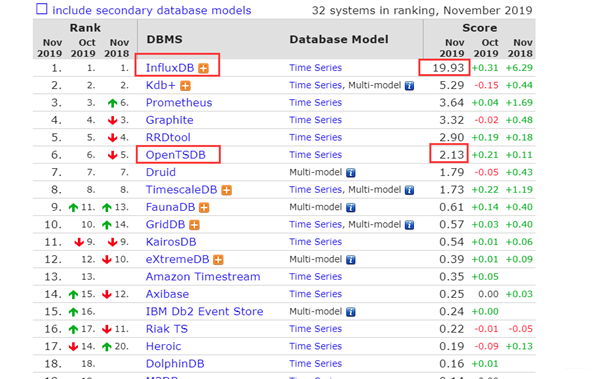
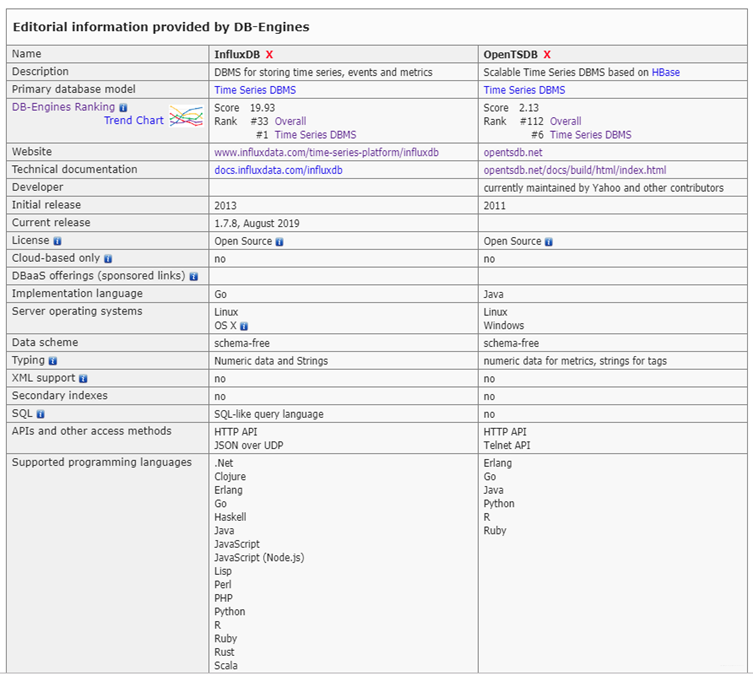
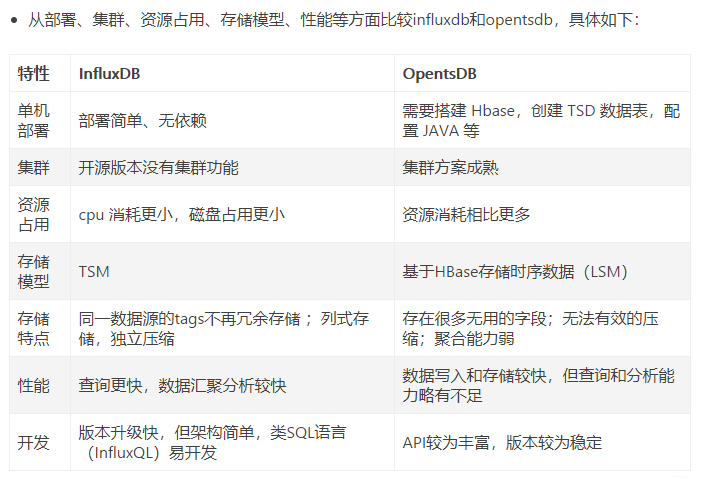
OpenTSDB VS InfluxTSDB

















 119
119

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









