







点击查看:
Nginx+Grafana+Prometheus+Jmeter搭建可视化测试监控平台 (包括InfluxDB)
1、官方测试数据导入
继上一篇分享的内容:
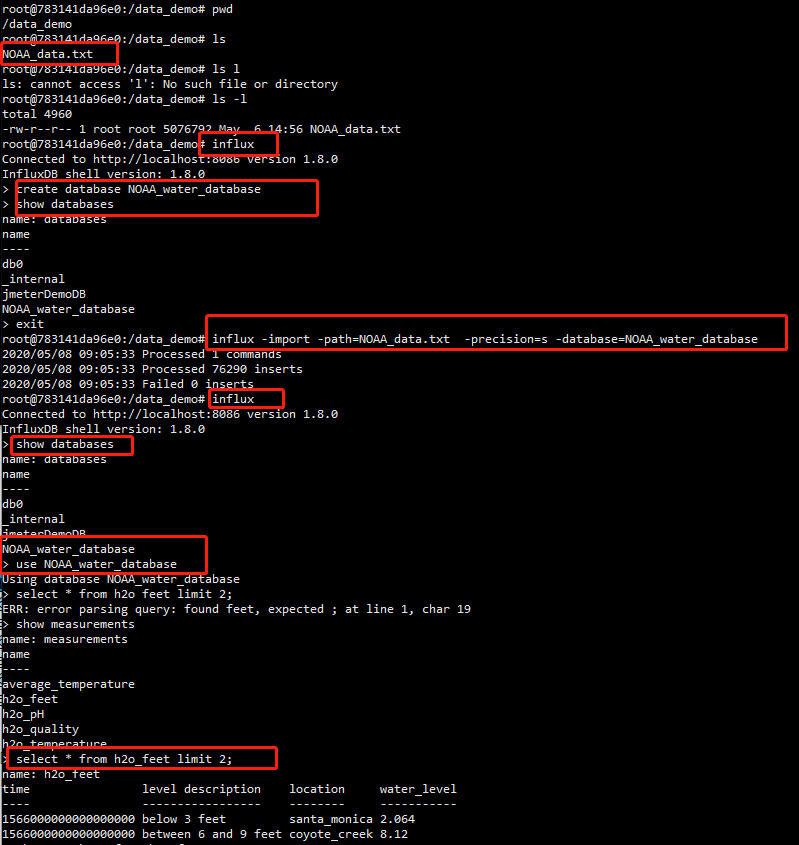
官方文档地址:
https://docs.influxdata.com/influxdb/v1.7/query_language/data_exploration/
2、数据说明
下面是本次演示的示例数据
表名:h2o_feet
数据示例:
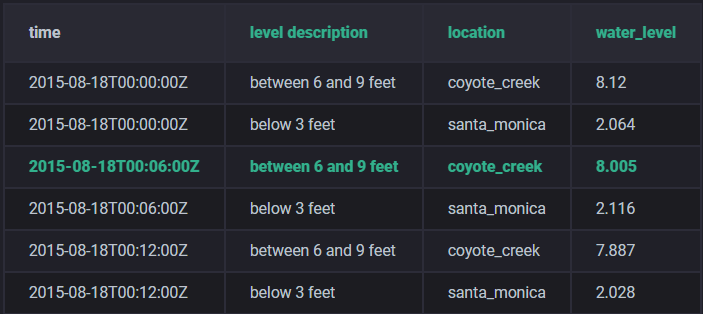
数据描述 :
表h2o_feet中所存储的是6分钟时间区间内的数据。
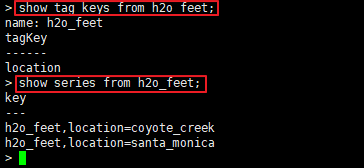
该表有一个tag,即location,该tag有两个值,分别为coyote_creek 和santa_monica,使用如下方式可以查询:
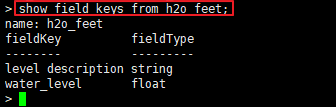
该表有两个fields,分别为level description和water_level,其中level description存储的是string类型的值,而water_level存储的是float类型的值。查询方式如下:
3、基本select语句
语法如下:
SELECT <field_key>[,<field_key>,<tag_key>] FROM <measurement_name>[,<measurement_name>]
select语句是由SELECT子句和FROM子句组成的。
3.1 SELECT子句
在SELECT字句中,有如下几种形式,分别用于查询各种指定的数据:
| 语法 | 意思 |
|---|---|
| SELECT * | 查询measurement中所有的fields和 tags。示例sql:select * from h2o_feet; |
| SELECT "<field_key>" | 查询指定的一个field。示例sql:select water_level from h2o_feet; |
| SELECT "<field_key>","<field_key>" | 查询多个field。示例sql:select "level description", "water_level" from h2o_feet; |
| SELECT "<field_key>","<tag_key>" | 查询指定的field和tag。示例sql:select water_level,location from h2o_feet; 注:在SELECT子句中,如果包含了tag,那么此时就必须指定至少一个field。比如如下的sql就是错误的,因为它只select了一个tag,而没有field:select location from h2o_feet; |
| SELECT "<field_key>"::field,"<tag_key>"::tag | 跟上面一样,也是查询指定的field和tag。::[field | tag]语法用来指定标识符的类型,因为有时候tag和field有可能同名,因此用 ::[field | tag]语法来加以区分。 |
在SELECT子句中,还包含数学运算、聚合函数、基本的类型转换、正则表达式等。
3.2 FROM子句
FROM子句用于指定要查询的measurement,支持的语法如下:
| 语法 | 意思 |
|---|---|
| FROM <measurement_name> | 从指定measurement中查询数据。这种方式会从当前DB、默认retention policy的measurement中查询数据。 |
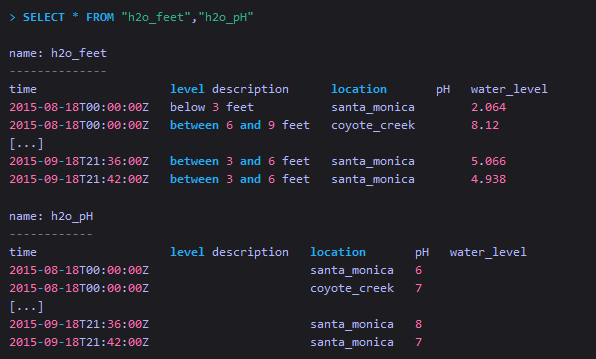
| FROM <measurement_name>,<measurement_name> | 从多个measurement中查询数据 |
| FROM <database_name>.<retention_policy_name>.<measurement_name> | 从指定DB、指定retention policy的measurement中查询数据 |
| FROM <database_name>..<measurement_name> | 从指定DB、默认retention policy的measurement 中查询数据 |
FROM子句中还支持正则表达式。
https://docs.influxdata.com/influxdb/v1.7/query_language/data_exploration/#regular-expressions
3.3 关于引号
如果measurement、tag、field等的标识符除了[A-z,0-9,_]之外,还有其他字符,或者标识符是keyword关键字,那么在引用的时候必须加上双引号。比如在表 h2o_feet 中,"level description"就是一个带有空格的field,如此一来在查询到的时候,就必须加上双引号了。如下图,在查询level description时若不加双引号,则会报错。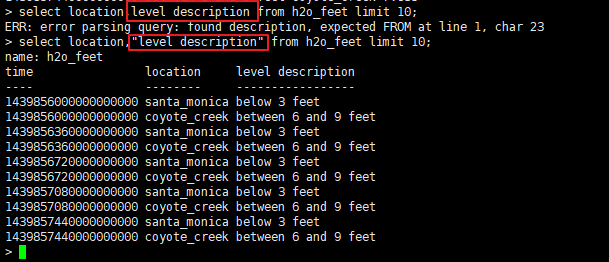
官方推荐,虽然有些标识符不是必须使用双引号,但是推荐对所有标识符使用双引号!
3.4 示例sql
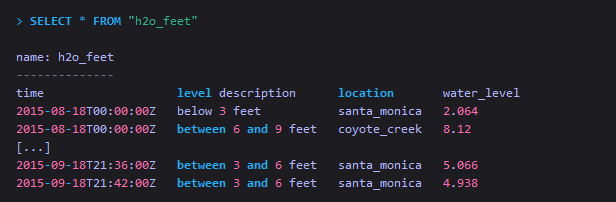
从单个measurement中查询该measurement所有的tag和field
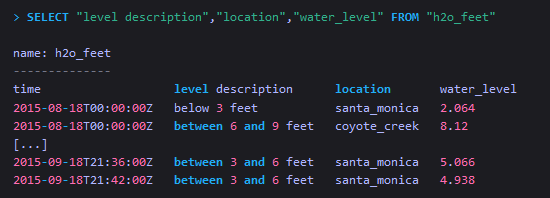
从单个measurement中查询指定的tag和field
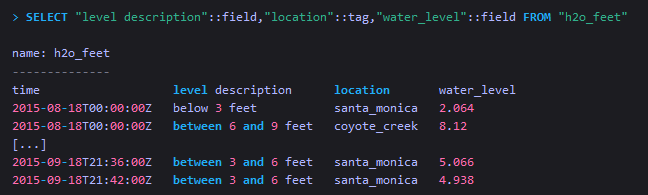
从单个measurement中查询指定的tag和field,并指定它们的标识类型
这种方式一般使用较少。从measurement中查询所有的field
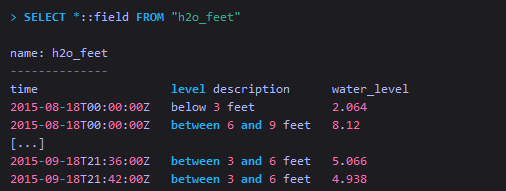
The SELECT clause supports combining the * syntax with the :: syntax.在查询时进行基本的数学运算
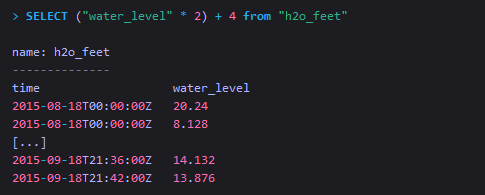
InfluxDB遵循标准的四则运算规则。更多操作详见Mathematical Operators。同时从多个measurement中查询它们的所有数据
从一个全路径的measurement中查询数据
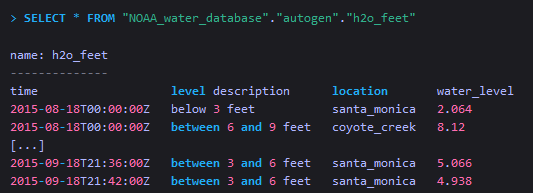
可见,所谓的全路径,其实就是指在FROM子句中,指定了measurement所在的DB,以及要查询数据所在的retention policy。查询指定数据库中的measurement的数据
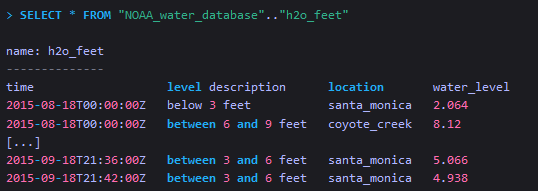
查询选择NOAA_water_database中的数据,DEFAULT的保留策略,和h2o_feet表,... 是指定数据库的
DEFAULT保留策略。
The query selects data in the NOAA_water_database, the DEFAULT retention policy, and the h2o_feet measurement. The .. indicates the DEFAULT retention policy for the specified database.
3.5 关于SELECT语句的常见疑问
在SELECT 子句中,必须要有至少一个field key!如果在SELECT子句中只有一个或多个tag key,那么该查询会返回空。这是由InfluxDB底层存储数据的方式所导致的结果。
示例:

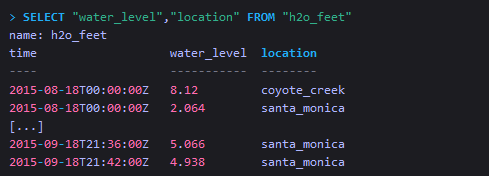
上面的查询结果返回为空,是因为在它的SELECT子句中,只查询了location这个tag key。
如果想要查询跟location这个tag key有关的任何数据,则在SELECT字句中必须至少要包含一个field key,如下:
送书活动:
留言+分享赠书
免费赠送技术类图书,无套路,纯免费!
《TensorFlow深度学习实战大全》
(活动码003)
点击下方小程序查看图书内容详情

第001期送书活动:
《Python自动化测试实战》
第002期送书活动:
《Python网络爬虫开发从入门到精通》

点击查看
文章合集
Selenium | Appium | Jenkins | Jmeter
软件测试方法汇总 | Postman接口参数化 | 测试用例设计
视频教程
Selenium | Appium | Jenkins | Jmeter
AWS与Docker
如何使用AWS EC2+Docker+JMeter构建分布式负载测试基础架构
Docker容器数据持久化和容器网桥连接
Docker删除image和container
Docker与VM虚拟机的区别以及Docker的特点

END
觉得不错,可以点“在看”,或者转发、留言
精彩的内容要和朋友分享哦


















 2943
2943

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











