








目录
🍺0.前言
言C之言,聊C之识,以C会友,共向远方。各位博友的各位你们好啊,这里是持续分享数据结构知识的小赵同学,今天要分享的数据结构知识是链表,在这一章,小赵将会向大家展开聊聊链表。✊

1.链表的概念
概念:链表是一种 物理存储结构上非连续 、非顺序的存储结构,数据元素的 逻辑顺序 是通过链表中的 指针链接次序 实现的 。
当然了光靠这个字面上的的理解就想理解链表我感觉还是蛮难的,所以呢,小赵在这里为大家找了一幅图片,方便大家理解
有人说这不是一个火车吗?怎么会和链表扯上关系,但实际上链表和火车是极其相似的,我在这里为大家画了个链表的图。

链表的结构就是一环接着一环的,哪这每一个环是什么呢?其实就是我们的结构体了。我们将结构体的指针放在前一个结构体的里面,来实现彼此之间的互通,从而形成一个链表。
2.链表的分类
可能看到这个标题有人会疑惑为什么链表还有分类呢?不就是一根链子吗?实际上则不然,相比较我们前面所说的火车,链表的可能性更多,它可以没有火车头,它可以彼此之间相互拉着,你拉着我,我拉着你,它们可以从头到尾,也可以围成一个圈,成一个环。
那么究竟到底有哪几种呢?小赵按照三个特征为他们划分,同时它们可以自由组合。
2.1带头不带头
带头和不带头长啥样呢就是下面这个样子
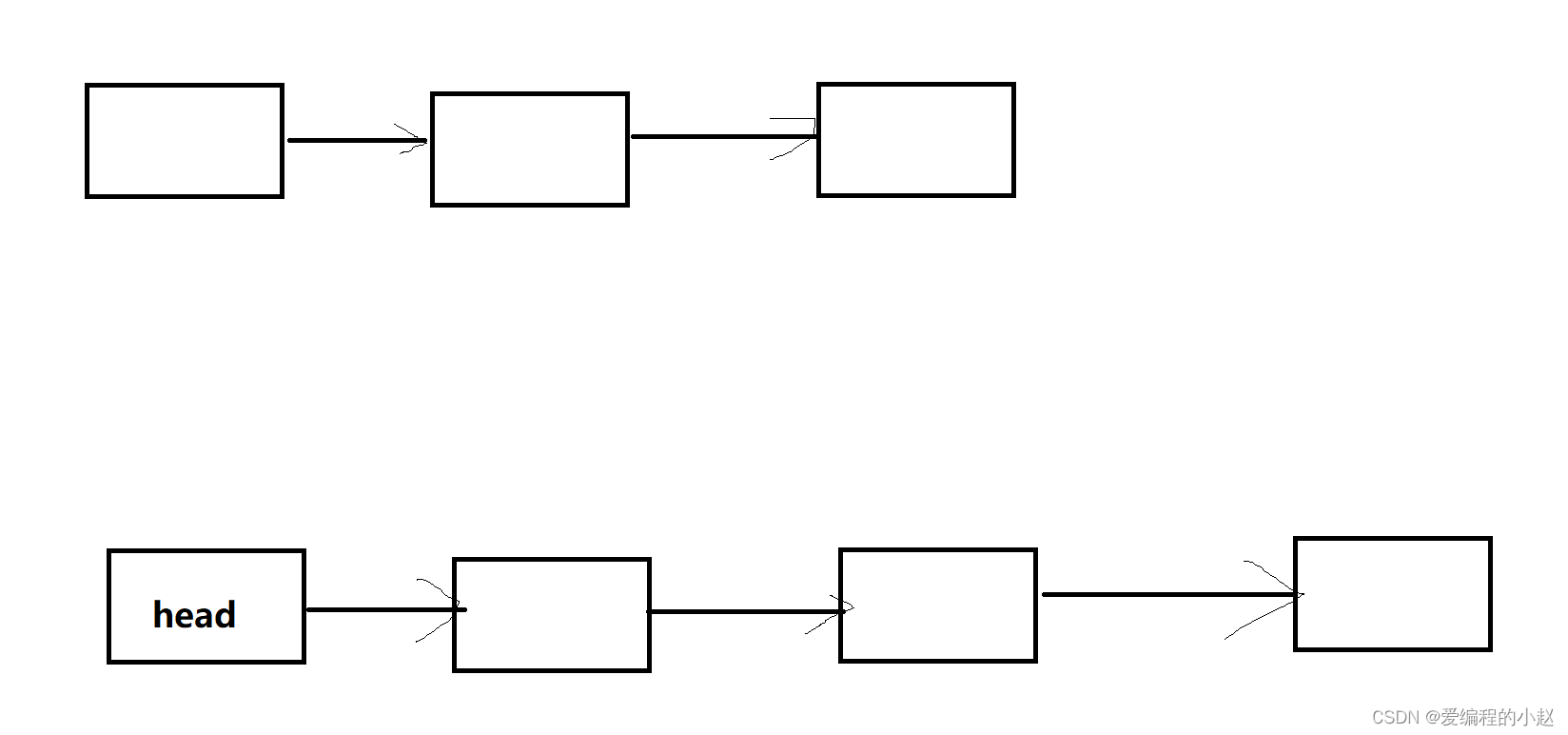
那带头和不带头有啥区别呢?其区别其实和火车很像,我们知道火车头往往是不载客的,而其实我们的这个头也是不载数据的,当然最主要的区别还是在我们后面使用的方便度上。
2.2单向和双向
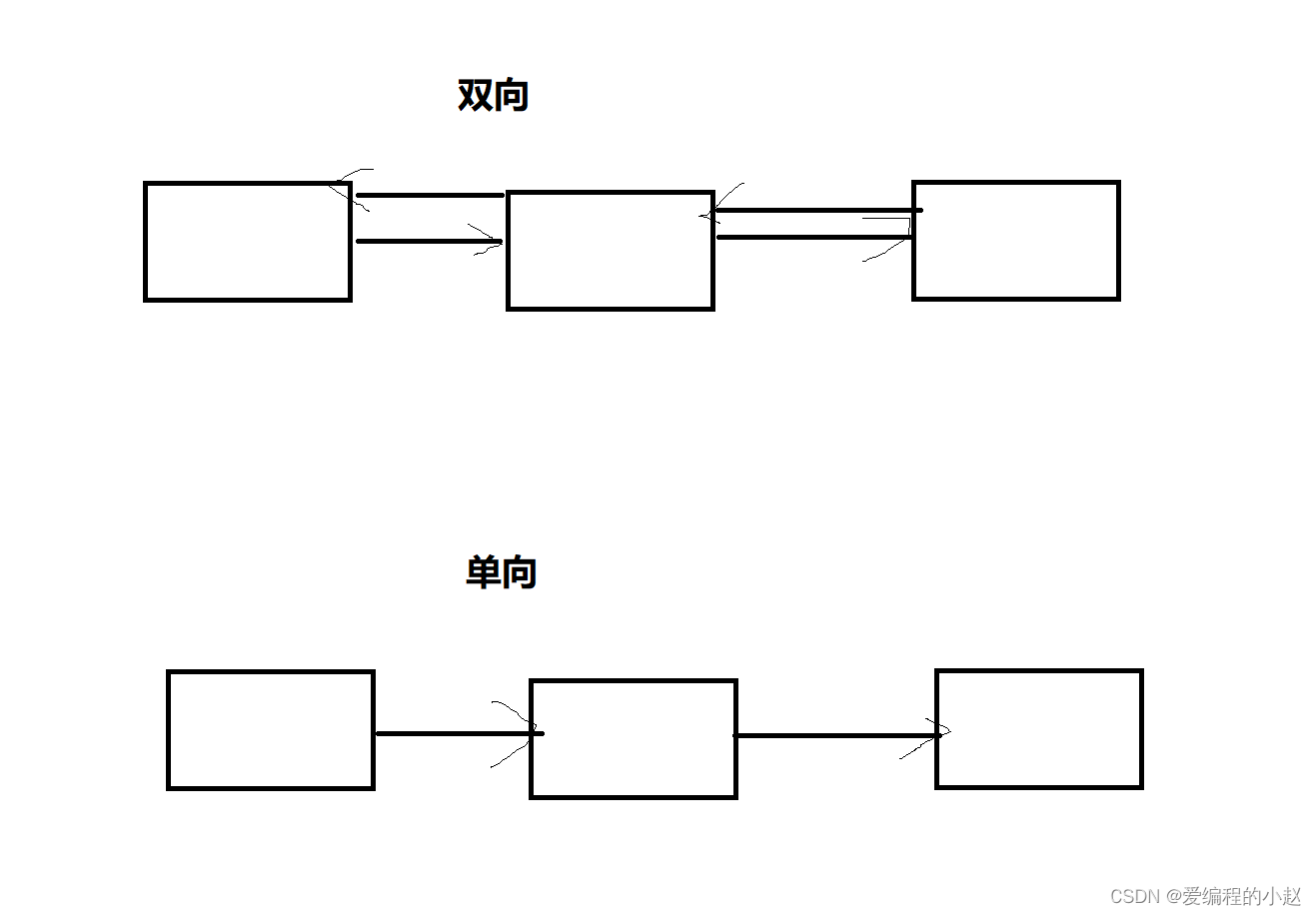
其实我觉得单向和双向的例子还蛮好理解的,就像我们谈恋爱一样,你单喜欢她,她不喜欢你,就叫单向。互相喜欢就是双向。
2.3循环和不循环
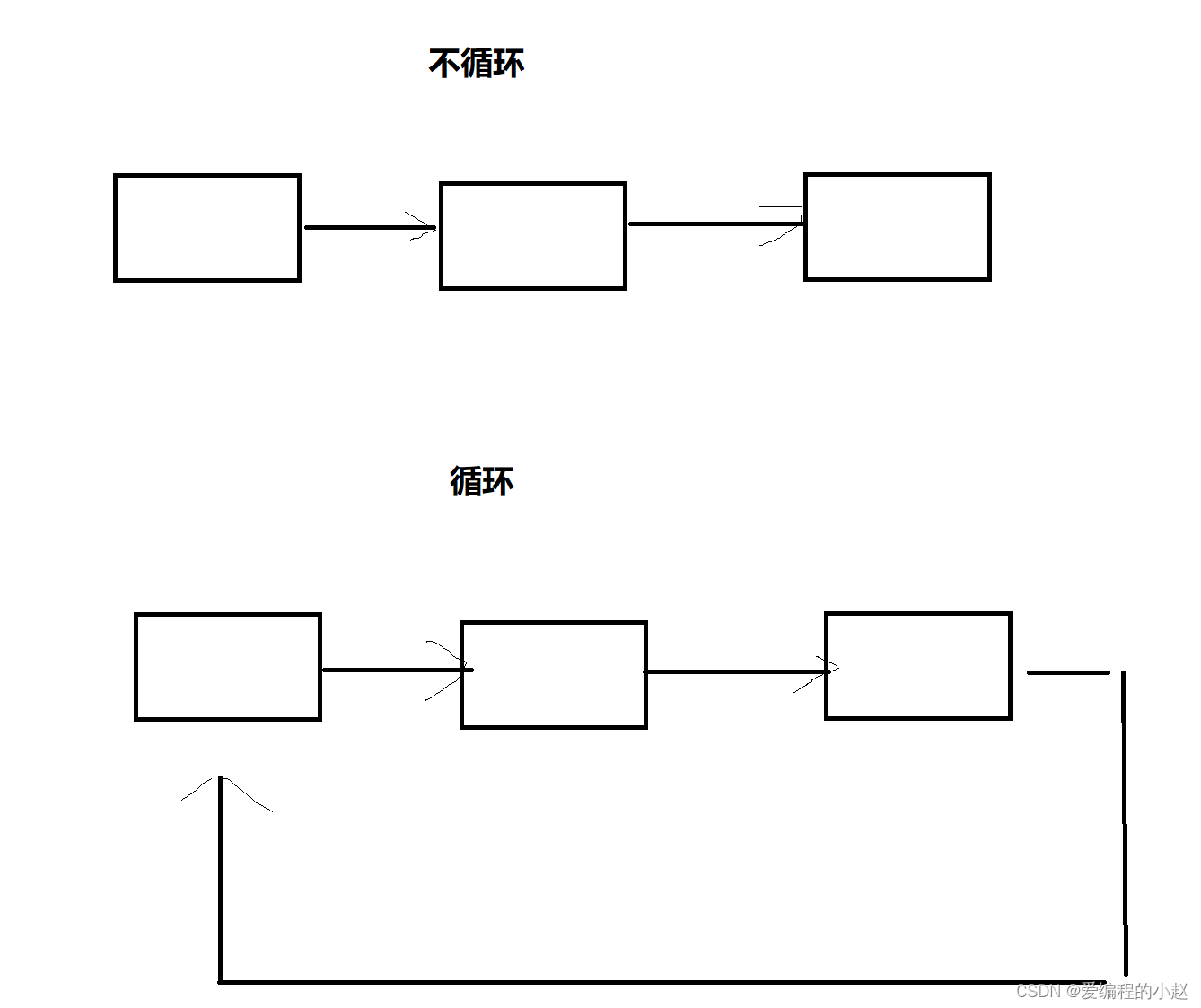
循环和不循环其实也相对比较好理解一点,在这里就不多说了。
这三个特征各位可以随意组合都能构成链表,同时各位用这三个基本特征去判断链表,也能让各位准确地判断出这是什么链表。
2.4主要使用的链表
虽然链表的种类如此之多之杂,但实际上我们正常使用的链表只有下面两个。
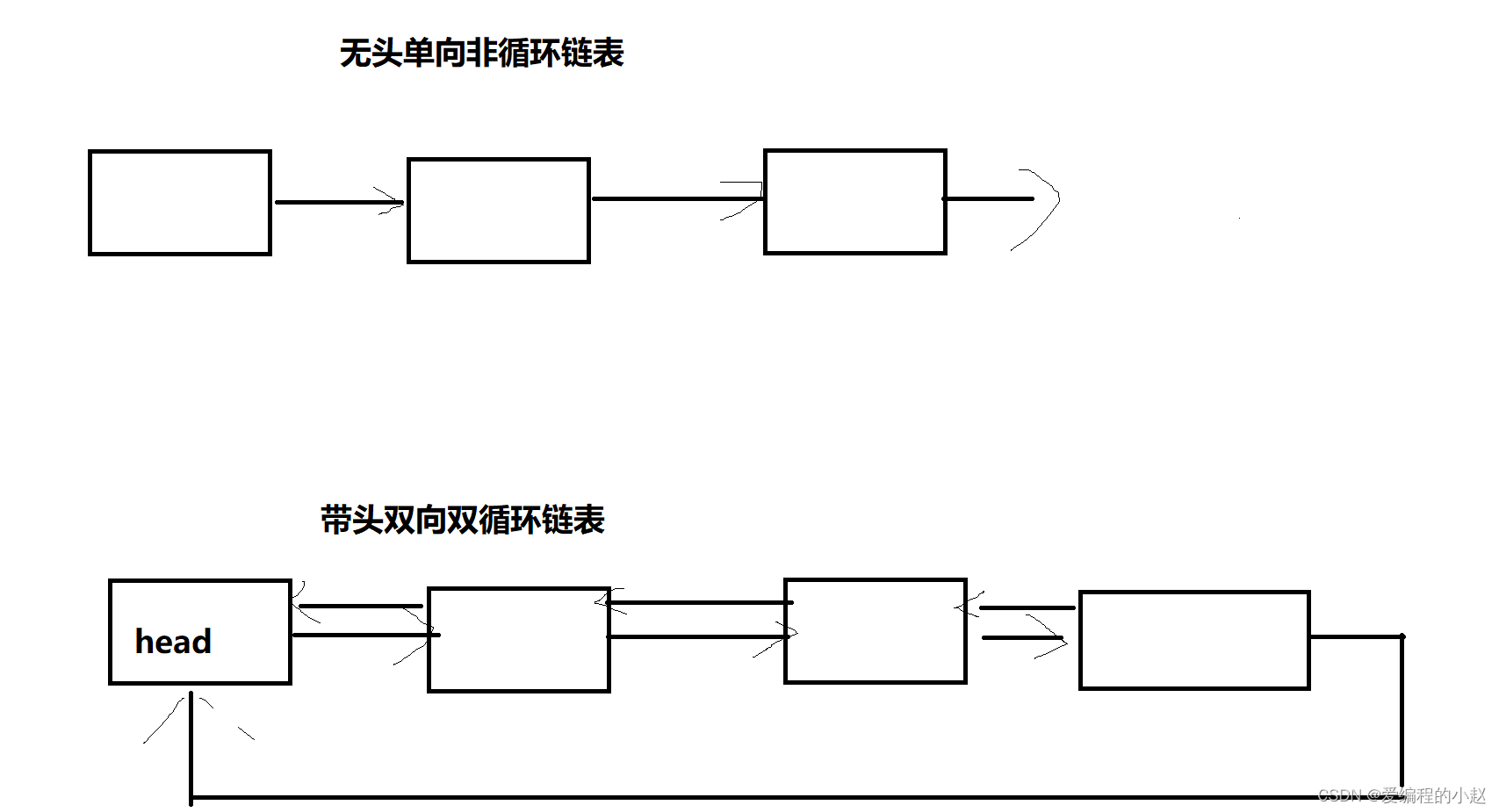
说白了,就是一个是白手起家,一个是啥都有的大土豪。白手起家的可能在我们的刷题中是很常见的,因为毕竟是白手起家,难度可能会更大一些。而什么都有这个各位后面会知道真的很爽,但题大多数题目是不会给你这么爽的。所以今天我们聊链表的时候会用我们的穷小子,来做,这样以后做大土豪也更容易一些。
3.链表的实现
那么链表该如何实现呢?跟上面的顺序表一样,我们也是从链表的功能增删查改来玩。
当然开始之前我们肯定是要先定义一个节点:
typedef int SLTDateType;
typedef struct SListNode
{
SLTDateType data;
struct SListNode* next;
}SListNode;3.1申请一个链表
这里我们换一种和之前的顺序表不一样的方式,我们直接用指针去玩,因为链表里面的指针非常多,我们可以直接申请一个指针的链表。
SListNode* BuySListNode(SLTDateType x)
{
SListNode* a = (SListNode*)malloc(sizeof(SListNode));//创建一小节链表
if(a==NULL)
{
perror("malloc failed");
return;
}
a->data = x;
a->next = NULL;
return a;
}3.2头插和尾插
单链表的头插
void SListPushFront(SListNode** pplist, SLTDateType x)
{
assert(*(pplist));
SListNode* newnode = BuySListNode(x);//创建一个新节点
newnode->next = *(pplist);//让新节点接上原链表的头节点
*(pplist) = newnode;//改变原链表的头节点
}
// 单链表尾插
void SListPushBack(SListNode** pplist, SLTDateType x)
{
assert(*(pplist));
SListNode* newnode = BuySListNode(x);
SListNode* node = *(pplist);//记录原链表的头节点
while (node->next)//找到原链表的尾节点
{
node = node->next;
}
node->next = newnode;//插入新的尾巴节点
}
好了,在这个代码中,我们也有一些常见的问题。比如小赵当时学的时候就挺奇怪为啥这里不能直接用我们的指针,而要找双指针呢?其实这个时候就是我们在函数那边的一个知识,或者说是指针那边的知识。
3.2.1函数的形参问题
为了方便大家更深入理解这个问题,小赵会带着大家重新回顾之前的知识,同时加深我们对这一块知识的理解。
首先拿我们最熟悉最经典的Swap函数聊起。
void Swap(int x, int y)
{
int tmp = x;
x = y;
y = tmp;
}
int main()
{
int a = 5;
int b = 6;
Swap(a, b);
printf("a=%d b=%d" ,a,b);
}
按照大多数人的理解方式可能这里就很奇怪了,为啥呢?为啥没有交换呢?
实际上这是我们对函数的形参理解不够透彻导致的。其实你向函数传送一个实参的,那边的形参就会将你的函数里面的值给接受了,如果说的形象一点就是接力跑。如果我们把a的值想象成一个棒子的话,那么a向函数里面传参的过程实际上就是a在把棒子给形参的过程。后面跑的实际是形参,跟你这个实参一点关系都没有,你a就留在了原地。拿这里究竟该如何去改呢?就是用我们的指针的知识。因为指针所携带的是你的地址,他可以通过地址找到你从而改变你。
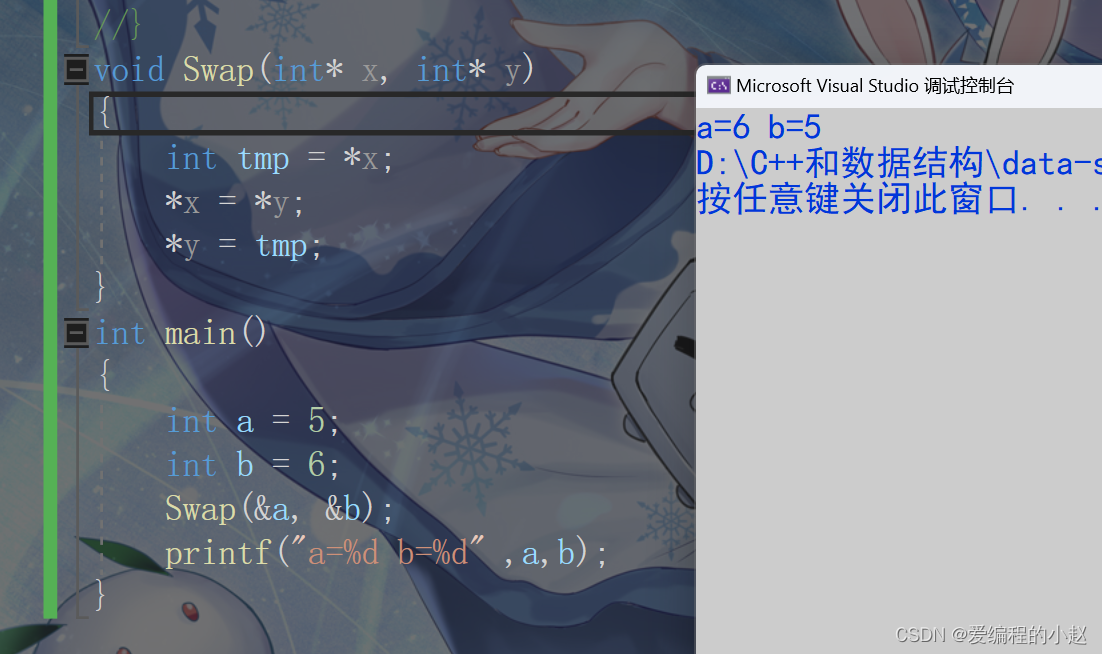 我们发现这个过程中我们传输东西的本质其实没有变,我们还是将接力棒给了形参,但是这次的形参里面有我们的地址,那么他进行解地址的时候,就可以访问到我们的实参了,从而实现交换的效果。
我们发现这个过程中我们传输东西的本质其实没有变,我们还是将接力棒给了形参,但是这次的形参里面有我们的地址,那么他进行解地址的时候,就可以访问到我们的实参了,从而实现交换的效果。
3.2.2二级指针问题解决
而我们这里为何会使用起二级指针呢?其实原因跟上面一样,我们发现只有把我们实参的地址传过去才能真正改变我们的实参.那要改变我们的指针,就要把我们指针的地址传过去,可我们发现一个问题,那就是普通的地址,指针是能够接受的。那指针的地址呢?用我们前面的知识我们知道,只有二级指针才能接收一级指针的地址,所以这里我们用了二级指针。如果你还是不太清楚整个的逻辑的关系,没关系,小赵还给各位画了一个图。
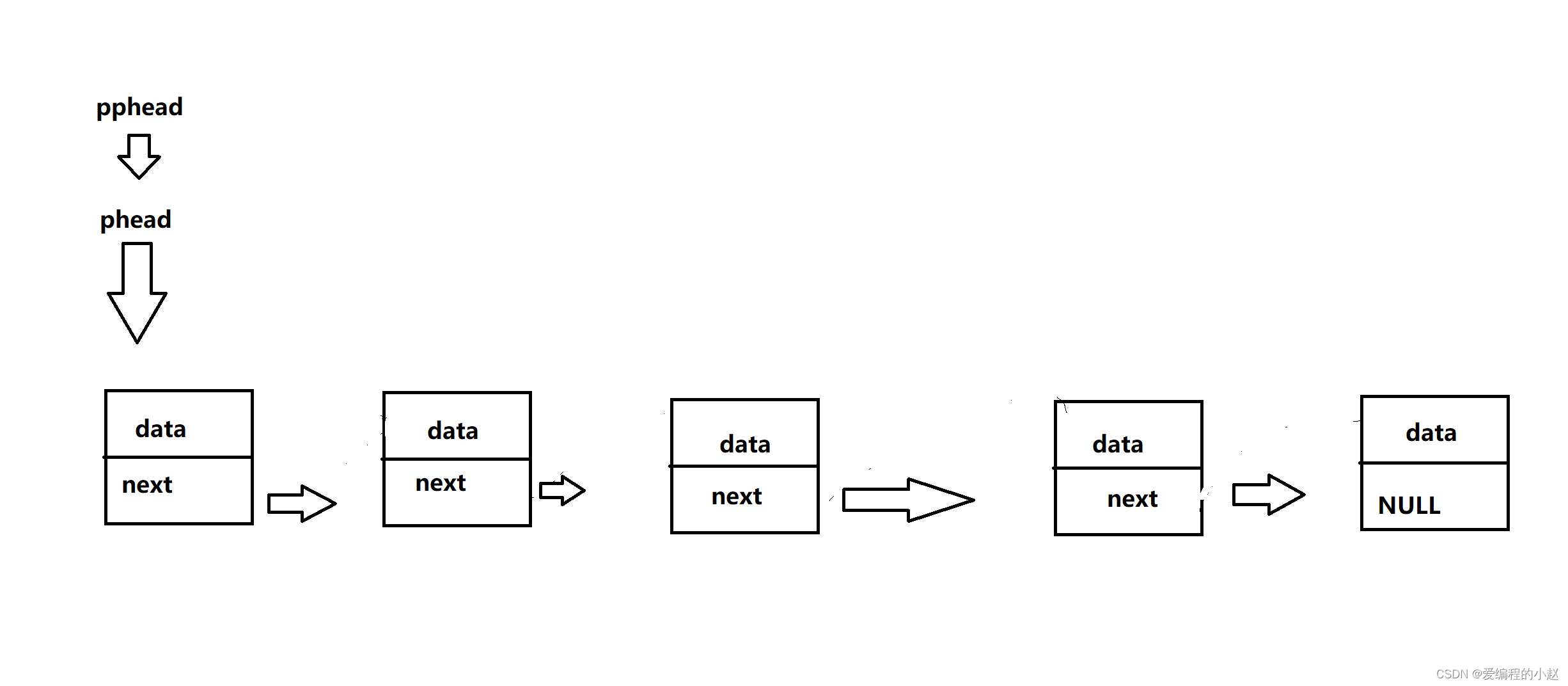
相信有了上面的知识各位再看这个代码就会轻松多了,如果各位还有什么问题,也可以私信小赵哦。
单链表的头插
void SListPushFront(SListNode** pplist, SLTDateType x)
{
SListNode* newnode = BuySListNode(x);//创建一个新节点
newnode->next = *(pplist);//让新节点接上原链表的头节点
*(pplist) = newnode;//改变原链表的头节点
}
// 单链表尾插
void SListPushBack(SListNode** pplist, SLTDateType x)
{
SListNode* newnode = BuySListNode(x);
SListNode* node = *(pplist);//记录原链表的头节点
while (node->next)//找到原链表的尾节点
{
node = node->next;
}
node->next = newnode;//插入新的尾巴节点
}
3.3头删和尾删
单链表头删
void SListPopFront(SListNode** pplist)
{
assert(*(pplist));//防止没有节点
SListNode* node = *(pplist);//记录原链表的头节点
*(pplist) = node->next;
free(node);//释放掉原头节点
node = NULL;
}
//单链表的尾删
void SListPopBack(SListNode** pplist)
{
assert(*pplist);
SListNode* node = *(pplist);//记录原链表的头节点
while (node->next && node->next->next)//找到原链表的尾节点的前一个节点
{
node = node->next;
}
SListNode* end = node->next;//保存尾节点
node->next = NULL;
free(end);//释放尾节点
end = NULL;
}3.4打印链表
void SListPrint(SListNode* plist)
{
assert(plist);
while (plist)
{
printf("%d->", plist->data);
plist = plist->next;
}
}3.5查找
SListNode* SListFind(SListNode* plist, SLTDateType x)
{
assert(plist);
while (plist)
{
if (plist->data == x)
{
return plist;
}
plist = plist->next;
}
return NULL;
}3.5销毁链表
void SLTDestroy(SListNode** pphead)
{
SListNode* node = *pphead;
while (node)//直到为空指针为止
{
SListNode* node2 = node;//保留当前指针
node = node->next;//到下一个节点
free(node2);//释放之前的那个
node2 = NULL;
}
node = NULL;
}3.6某个位置插入和删除
3.6.1前插
void SLTInsert(SListNode** pphead, SListNode* pos, SLTDateType x)
{
assert(pos);
SListNode* node = *pphead;
SListNode* newnode = BuySListNode(x);
if (pos == *pphead)//如果是头节点特殊处理
{
newnode->next = node;
*pphead = newnode;
return;
}
while ( node->next != pos)//找到pos前一个节点
{
node = node->next;
}
SListNode* begin = node;//要插入的节点的前一个节点
SListNode* end =pos;//要插入的节点的后一个节点
begin->next = newnode;
newnode->next = end;
}前插的难度是要比后插大的,其原因就在于前插要考虑可能是头插的情况发生,同时 前插还要通过while去找到前一个节点,这一点导致了其的难度大。
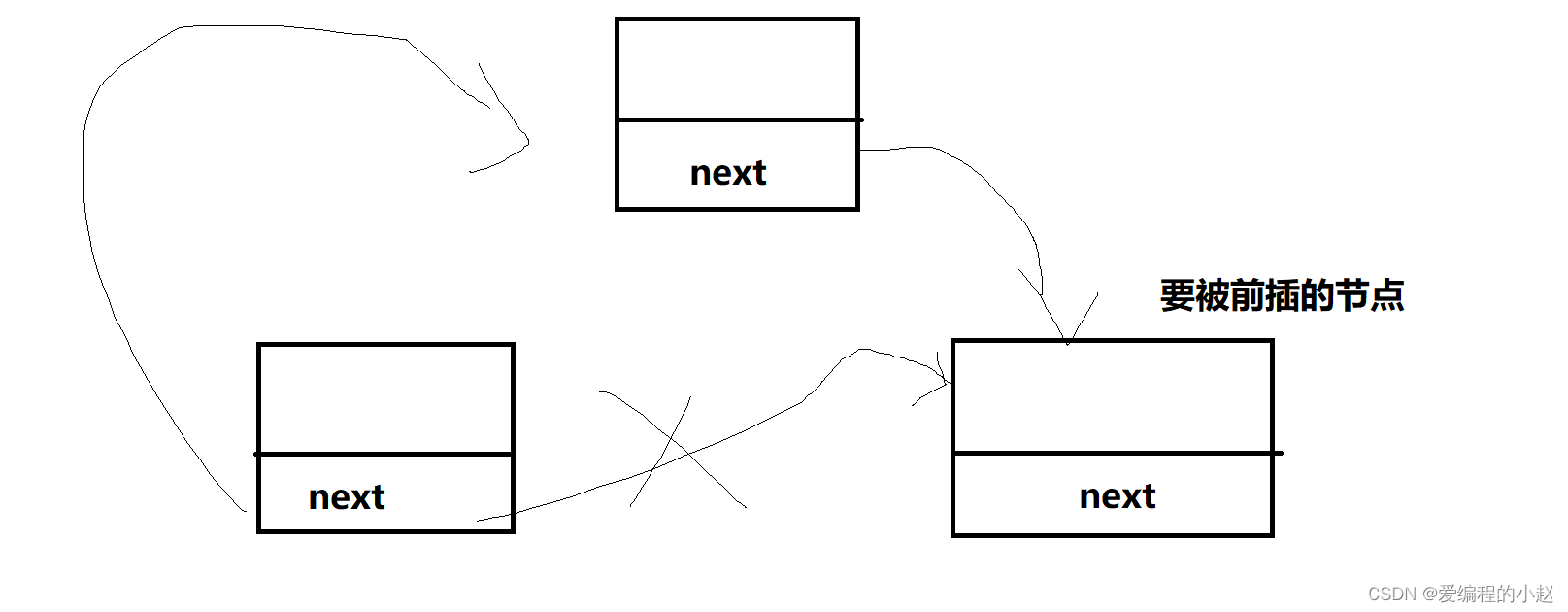
3.6.1后插
void SListInsertAfter(SListNode* pos, SLTDateType x)
{
assert(pos);
SListNode* end = pos->next;//保留下一个节点
SListNode* node = BuySListNode(x);//创建新节点
pos->next = node;//重新连接
node->next = end;
}这个是在我们某一个节点后插入,其的感觉像是什么呢?就像是小赵下面这个画一样。

断开原连线,连上新的线。
3.6.3前删
void SLTErase(SListNode** pphead, SListNode* pos)
{
assert(pos);
if (pos == *pphead) return;
SListNode* node = *pphead;
if (pos == (*pphead)->next )//如果是头删,特殊处理
{
free(node);
node = NULL;
*pphead = pos;
return;
}
while (node->next->next != pos)
{
node = node->next;
}
SListNode* node2 = node->next ;//找到被删节点的前一个节点
node->next = pos;
free(node2);
node2 = NULL;
}
3.6.4后删
void SListEraseAfter(SListNode* pos)
{
assert(pos);
if (pos->next == NULL) return;//处理特殊情况
SListNode* end = pos->next->next;//保存后面的后面的节点
SListNode* node = pos->next;
pos->next = end;
free(node);
node = NULL;
}4.结束语
好了小赵今天的分享就到这里了,如果大家有什么不明白的地方可以在小赵的下方留言哦,同时如果小赵的博客中有什么地方不对也希望得到大家的指点,谢谢各位家人们的支持。你们的支持是小赵创作的动力,加油。

如果觉得文章对你有帮助的话,还请点赞,关注,收藏支持小赵,如有不足还请指点,小赵及时改正,感谢大家支持!!!
















 917
917











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











