







目录
背景
搜索使用es,在数据同步es时,最开始使用自带的logstash方式,简单方便。但是实时性存在问题。logstash最小时间间隔1分钟,基本上大部分非实时场景都可以满足。对于一些实时性的数据要求,可以有以下常用几种方式满足:
- 搜索接口外部包装处理:在最终对外的api外层进行封装处理下,对于部分实时性要求高的单独sql/redis方式查询,然后给到使用方。
- 涉及属性变动的业务操作中添加触发通知处理:比如商品下架或禁用的操作方法中添加mq消息通知,然es中的对应属性变更。
- 把mysql的binlog同步mq中,监听消费处理。
以上方法或入侵业务代码、或者过度封装、或者转换处理麻烦。canal可以比较好的避免上面的问题。
canal实现原理
首先看下mysql的主从复制的机制:

- mysql的master服务记录变动信息到binlog日志中。
- slave服务请求获取binlog日志到自己的relay log中。
- slave服务执行relaylog对旧有数据进行更新。
canal主要是通过把自己伪装成一个slave,向master发出dump协议请求,获取到binary log日志进行数据解析处理。
准备
需要提前安装好以下服务:
1)JDK安装。 传送门
2)mysql的安装. 传送门
3)zookeeper集群搭建 传送门
4)rocketMq的安装
5)canal.admin和canal.deployer的下载。
我的本地运行环境如下:
window10环境
jdk 1.8.0_91
mysql-8.0.26-winx64
apache-zookeeper-3.7.0
canal.admin和canal.deployer下载的是1.1.5版本
mysql相关配置
开启binlog配置
# windows下mysql的配置文件是my.ini。一般放到安装的根目录
# Linux下MySQL的配置文件是my.cnf,一般会放在/etc/my.cnf,/etc/mysql/my.cnf
[mysqld]
# *** Replication related settings ***
#在复制方面的改进就是引进了新的复制技术:基于行的复制。
binlog-format=ROW
#开启二进制日志功能,binlog数据位置
log-bin="D:\\work\\dataBase\\mysqldata\\binlog\\mysql-binlog"
#服务端ID,用来高可用时做区分
server_id=100
#二进制日志自动删除的天数。默认值为0,表示“没有自动删除”。启动时和二进制日志循环时可能删除。
#expire-logs-days=2 mysql8.x中准备作废
binlog_expire_logs_seconds=86400
# 配置 MySQL replaction 需要定义,不要和 canal 的 slaveId 重复
server_id=100
注意:如果使用的是阿里云的 RDS for MySQL。已经是默认打开binlog了,并且账号默认具有 binlog dump 权限 , 不需要任何权限或者 binlog 设置,可以直接跳过这一步
同步账户准备
创建账户
#创建canal账号
mysql > create user 'canal'@'%' identified by 'canal';
#结果可以查看
mysql > select host, user, authentication_string, plugin from mysql.user;
##只针对 mysql 8.*的。
# mysql8中默认的身份插件是caching_sha2_password,替代了之前mysql_native_password。所以如果是使用的是mysql8的,需要做下调整操作
mysql > alter user 'canal'@'%' identified with mysql_native_password by 'canal123';
授权
# 授予canal用户复制binlog的权限
# 注意:REPLICATION 相关的权限必须针对全库全表的。
mysql > GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
# 进行刷新
mysql > FLUSH PRIVILEGES;
# 查看授权
mysql > show grants for 'canal'@'%';
canalAdmin配置
配置
canal.admin-1.1.5解压之后。可以看到有以下4个文件夹
- bin:存放执行文件。 startup.sh / startup.bat等
- conf:存放的配置文件。我们会用到 application.yml
- lib:canalAdmin项目依赖的jar包
- logs:默认日志地址。可以通过 conf中的logback.xml的配置调整
application.yml配置
# 端口号配置
server:
port: 8089
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+8
# 数据源配置
spring.datasource:
address: 127.0.0.1:3306
database: canal_manager
username: canalAdmin
password: canalAdmin123
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://${spring.datasource.address}/${spring.datasource.database}?useUnicode=true&characterEncoding=UTF-8&useSSL=false&allowPublicKeyRetrieval=true
hikari:
maximum-pool-size: 30
minimum-idle: 1
# 这里的 canal admin的用户名和密码并不是canal admin web ui的用户,
# 而是后门canal server和canal admin进行通信时的用户。canal server中会在canal.properites中的配置的
canal:
adminUser: admin
adminPasswd: admin
配置完成之后,启动。在logs/admin.log中查看日志。
2021-08-13 16:32:15.902 [main] INFO o.s.b.a.web.servlet.WelcomePageHandlerMapping - Adding welcome page: class path resource [public/index.html]
2021-08-13 16:32:16.049 [main] INFO o.s.jmx.export.annotation.AnnotationMBeanExporter - Registering beans for JMX exposure on startup
2021-08-13 16:32:16.051 [main] INFO o.s.jmx.export.annotation.AnnotationMBeanExporter - Bean with name 'dataSource' has been autodetected for JMX exposure
2021-08-13 16:32:16.056 [main] INFO o.s.jmx.export.annotation.AnnotationMBeanExporter - Located MBean 'dataSource': registering with JMX server as MBean [com.zaxxer.hikari:name=dataSource,type=HikariDataSource]
2021-08-13 16:32:16.065 [main] INFO org.apache.coyote.http11.Http11NioProtocol - Starting ProtocolHandler ["http-nio-8089"]
2021-08-13 16:32:16.076 [main] INFO org.apache.tomcat.util.net.NioSelectorPool - Using a shared selector for servlet write/read
2021-08-13 16:32:16.089 [main] INFO o.s.boot.web.embedded.tomcat.TomcatWebServer - Tomcat started on port(s): 8089 (http) with context path ''
2021-08-13 16:32:16.092 [main] INFO com.alibaba.otter.canal.admin.CanalAdminApplication - Started CanalAdminApplication in 3.477 seconds (JVM running for 3.926)
conf其他
- application.yml,springboot默认依赖的配置,比如链接数据库的账号密码,链接canal-server admin管理的账号密码
- logback.xml,日志配置
- canal-template.properties,canal配置的默认模板,针对canal-server开启自动注册时,会选择这个默认模板
- instance-template.properties,instance配置的默认模板
界面操作
登录
浏览器输入 http://love.com:8089 。默认密码:admin/123456


说明
直接引用canal的说明:
canal-admin的核心模型主要有:
- instance,对应canal-server里的instance,一个最小的订阅mysql的队列
- server,对应canal-server,一个server里可以包含多个instance
- 集群,对应一组canal-server,组合在一起面向高可用HA的运维
简单解释:
- instance因为是最原始的业务订阅诉求,它会和 server/集群 这两个面向资源服务属性的进行关联,比如instance A绑定到server A上或者集群 A上,
- 有了任务和资源的绑定关系后,对应的资源服务就会接收到这个任务配置,在对应的资源上动态加载instance,并提供服务
** 动态加载的过程,有点类似于之前的autoScan机制,只不过基于canal-admin之后可就以变为远程的web操作,而不需要在机器上运维配置文件- 将server抽象成资源之后,原本canal-server运行所需要的canal.properties/instance.properties配置文件就需要在web ui上进行统一运维,每个server只需要以最基本的启动配置 (比如知道一下canal-admin的manager地址,以及访问配置的账号、密码即可)
这里补充下:配置的instance启动时,是只会绑定到某一个canal Server主机上的,并不是全面的server都运行的。当这个 Server挂掉了,会自动切换到其他的Server上继续运行。
集群管理
- 配置集群名称

- 集群的 主配置调整

- 模板配置调整

canal.properties配置
修改以下配置即可,其余的保持默认。
# canal admin config
# 这里的密码就是前面在application.yml最后的参数提到的admin/admin,不过这里需要使用mysql加密后的密码,可以在mysql内通过命令 select password('canal') 获取加密串(去掉星号)
canal.admin.manager = 127.0.0.1:8089
canal.admin.port = 11110
canal.admin.user = admin
canal.admin.passwd = 4ACFE3202A5FF5CF467898FC58AAB1D615029441
canal.zkServers = 127.0.0.1:2181,127.0.0.1:2182,127.0.0.1:2183
#canal.instance.global.spring.xml = classpath:spring/file-instance.xml
canal.instance.global.spring.xml = classpath:spring/default-instance.xml
#监控到的binlog输出到rocketmq
canal.serverMode = rocketMQ
# 如果使用的是阿里云的rds/mq这里需要配置
canal.aliyun.accessKey = xxxaaaa
canal.aliyun.secretKey = xxxrrrrrr
# rocketMQ的group配置
rocketmq.producer.group = GID_xxxxxxx
rocketmq.enable.message.trace = false
rocketmq.customized.trace.topic =
# rocketMQ的实例ID
rocketmq.namespace = MQ_INST_xxxxxxxxx
# rocketMQ的链接地址
rocketmq.namesrv.addr = http://xxxxxxxxxxx.mq-internet-access.mq-internet.aliyuncs.com:80
rocketmq.retry.times.when.send.failed = 0
rocketmq.vip.channel.enabled = false
# 消息的tag。如果有的配置
rocketmq.tag =
一个集群的所有server会共享一份全局canal.properties配置 (如果有个性化的配置需求,可以创建多个集群)
server配置
虽然界面上可以新增。但是更建议通过配置canal.deployer来自动注册,然后界面刷新就可以看到最新的。
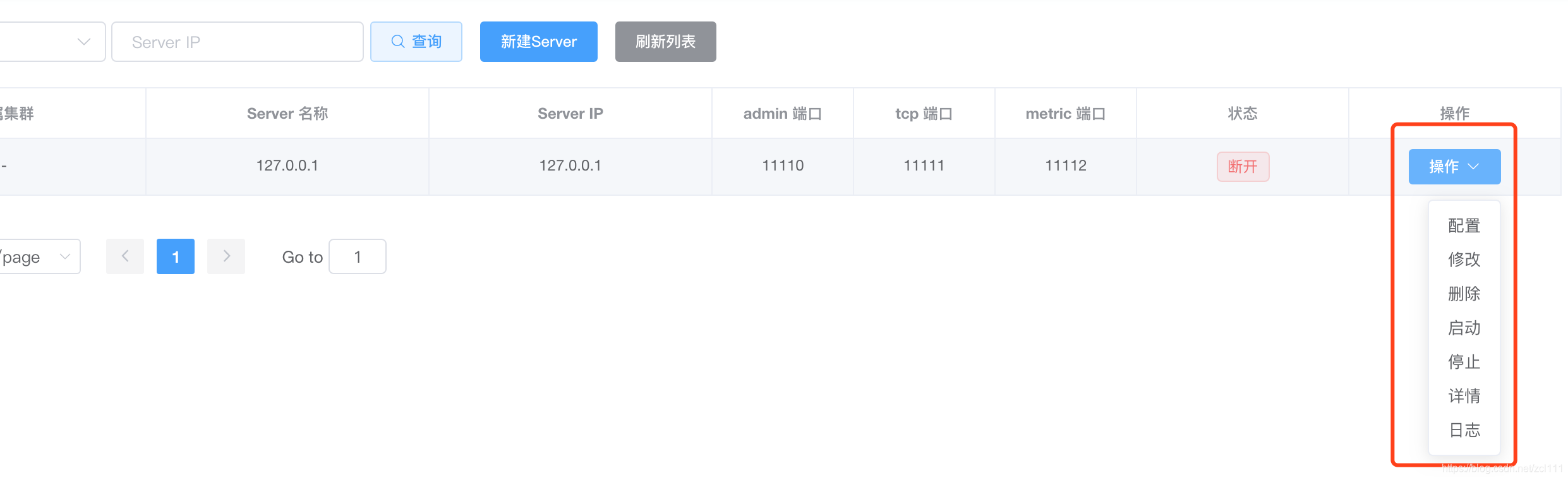
- 配置,主要是维护单机模式的canal.properties配置,注意:挂载到集群模式的server,不允许单独编辑server的canal.properties配置,需要保持集群配置统一
- 修改/删除,主要是维护server的基本属性,比如名字和ip、port
启动/停止,主要是提供动态启停server的能力,比如集群内这个机器打算下线了,可以先通过停止释放instance的运行,集群中的其他机器通过HA就会开始接管任务 - 日志,查看server的根日志,主要是canal/canal.log的最后100行日志
- 详情,主要提供查询在当前这个server上运行的instance列表,以server维度方便快速做instance的启动、停止操作. 比如针对集群模式,如果server之间任务运行负载不均衡,可以通过对高负载Server执行部分Instance的停止操作来达到均衡的目的
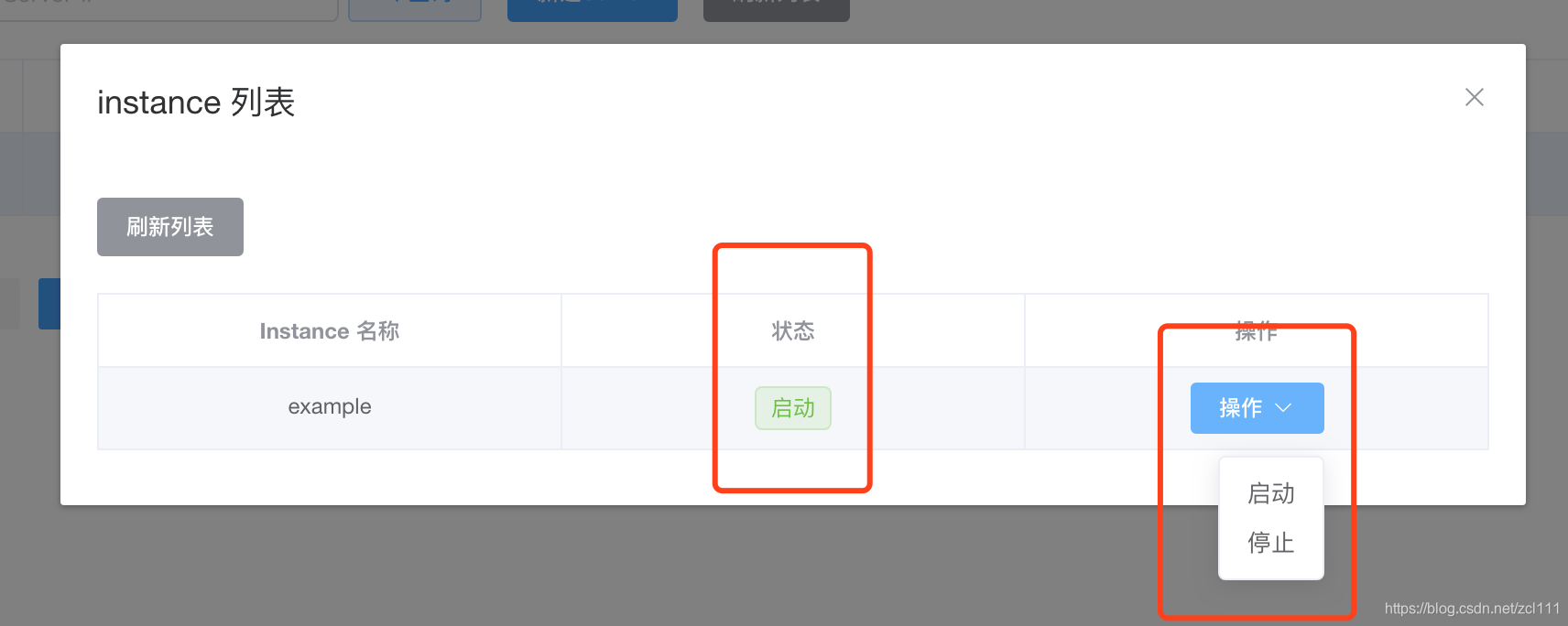
instance配置
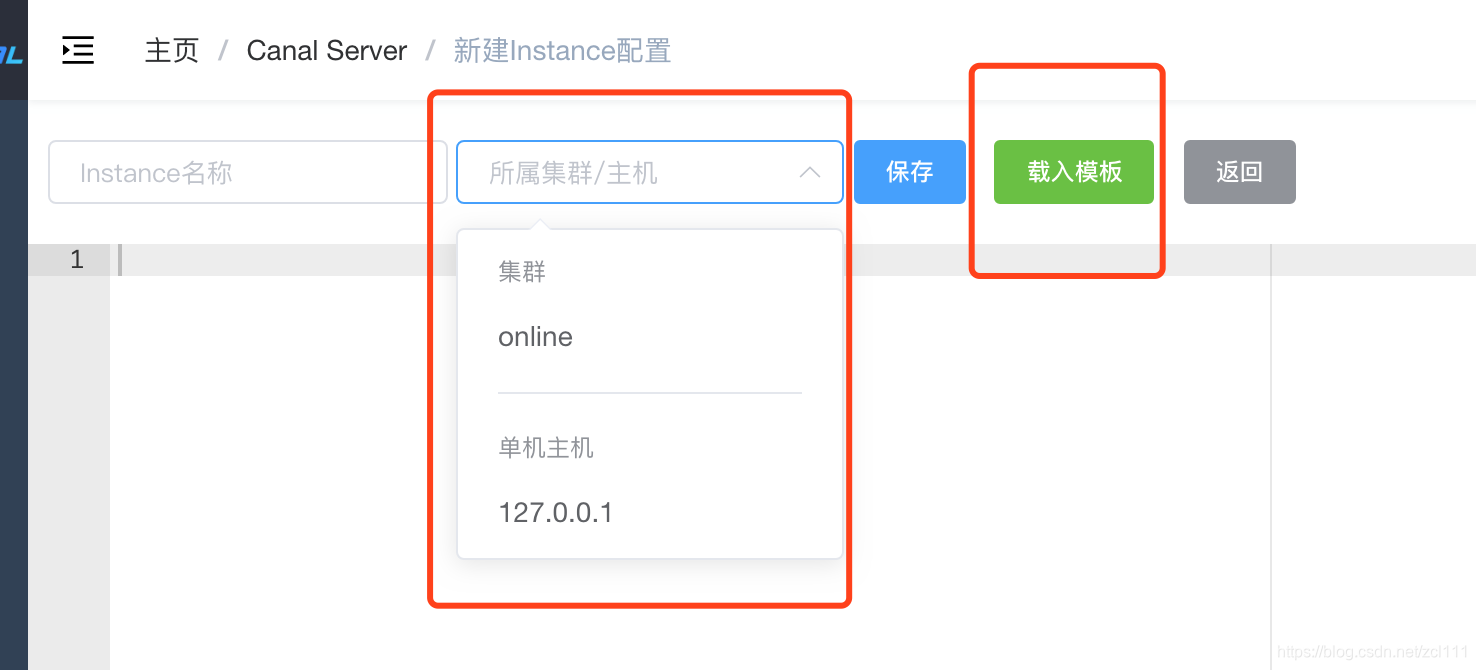 主要是把instance挂到哪个资源下,集群/单机。
主要是把instance挂到哪个资源下,集群/单机。
载入模板用于配置调整 instance.properites。

- 修改,主要就是维护instance.properties配置,做了修改之后会触发对应单机或集群server上的instance做动态reload。
- 删除,相当于直接执行instance stop,并执行配置删除。
- 启动/停止,对instance进行状态变更,做了修改会触发对应单机或集群server上的instance做启动/停止操作。
- 日志,主要针对instance运行状态时,获取对应instance的最后100行日志,比如example/example.log
instance.properites配置
只需要对以下配置进行调整即可,其他默认
# 连接数据源地址
canal.instance.master.address=127.0.0.1:3306
#aliyun账号的ak/sk信息 。如果不需要在本地binlog超过18小时被清理后自动下载oss上的binlog,可以忽略该值
canal.instance.rds.accesskey=
canal.instance.rds.secretkey=
# 数据库的账号密码。次账号是开通了replication相关权限的
canal.instance.dbUsername=canal
canal.instance.dbPassword=canal123
# 表过滤的白名单配置
canal.instance.filter.regex=bz_goods.item_info,bz_goods.supplier
# 表过滤的黑名单配置
canal.instance.filter.black.regex=
# 表属性过滤的白名单。如果用不到可以注释掉不用管
#canal.instance.filter.field=test1.t_product:id/subject/keywords,test2.t_company:id/name/contact/ch
# # 表属性过滤的黑名单。如果用不到可以注释掉不用管
#canal.instance.filter.black.field=test1.t_product:subject/product_image,test2.t_company:id/name/contact/ch
# 如果使用到MQ配置
canal.mq.topic=search-xxxx_topic_canal
# 根据库或表配置mq里的动态topic规则
#canal.mq.dynamicTopic=mytest1.user,mytest2\\..*,.*\\..*
#单队列模式的分区下标,
canal.mq.partition=0
# 散列模式的分区数
#canal.mq.partitionsNum=3
# 散列规则定义 库名.表名 : 唯一主键
#canal.mq.partitionHash=test.table:id^name,.*\\..*
canal.mq.partitionHash=.*\\..*:id
#################################################
mq相关配置
| 参数名 | 参数说明 | 默认值 |
|---|---|---|
| canal.mq.servers | kafka为bootstrap.servers / rocketMQ中为nameserver列表 | 127.0.0.1:6667 |
| canal.mq.retries | 发送失败重试次数 | 0 |
| canal.mq.batchSize | kafka为ProducerConfig.BATCH_SIZE_CONFIG / rocketMQ无意义 | 16384 |
| canal.mq.maxRequestSize | kafka为ProducerConfig.MAX_REQUEST_SIZE_CONFIG / rocketMQ无意义 | 1048576 |
| canal.mq.lingerMs | kafka为ProducerConfig.LINGER_MS_CONFIG , 如果是flatMessage格式建议将该值调大, 如: 200 / rocketMQ无意义 | 1 |
| canal.mq.bufferMemory | kafka为ProducerConfig.BUFFER_MEMORY_CONFIG / rocketMQ无意义 | 33554432 |
| canal.mq.acks | kafka为ProducerConfig.ACKS_CONFIG / rocketMQ无意义 | all |
| canal.mq.kafka.kerberos.enable | kafka为ProducerConfig.ACKS_CONFIG / rocketMQ无意义 | false |
| canal.mq.kafka.kerberos.krb5FilePath | kafka kerberos认证 / rocketMQ无意义 | …/conf/kerberos/krb5.conf |
| canal.mq.kafka.kerberos.jaasFilePath | kafka kerberos认证 / rocketMQ无意义 | …/conf/kerberos/jaas.conf |
| canal.mq.producerGroup | kafka无意义 / rocketMQ为ProducerGroup名 | Canal-Producer |
| canal.mq.accessChannel | kafka无意义 / rocketMQ为channel模式,如果为aliyun则配置为cloud | local |
| — | — | — |
| canal.mq.vhost= | rabbitMQ配置 | 无 |
| canal.mq.exchange= | rabbitMQ配置 | 无 |
| canal.mq.username= | rabbitMQ配置 | 无 |
| canal.mq.password= | rabbitMQ配置 | 无 |
| canal.mq.aliyunuid= | rabbitMQ配置 | 无 |
| — | — | — |
| canal.mq.canalBatchSize | 获取canal数据的批次大小 | 50 |
| canal.mq.canalGetTimeout | 获取canal数据的超时时间 | 100 |
| canal.mq.parallelThreadSize | mq数据转换并行处理的并发度 | 8 |
| canal.mq.flatMessage | 是否为json格式.如果设置为false,对应MQ收到的消息为protobuf格式.需要通过CanalMessageDeserializer进行解码 | false |
| — | — | — |
| canal.mq.topic | mq里的topic名 | 无 |
| canal.mq.dynamicTopic | mq里的动态topic规则, 1.1.3版本支持 | 无 |
| canal.mq.partition | 单队列模式的分区下标, | 1 |
| canal.mq.partitionsNum | 散列模式的分区数 | 无 |
| canal.mq.partitionHash | 散列规则定义 | 无 |
canal.mq.dynamicTopic 表达式说明:
canal 1.1.3版本之后, 支持配置格式:schema 或 schema.table,多个配置之间使用逗号或分号分隔
- 例子1:test\.test 指定匹配的单表,发送到以test_test为名字的topic上
- 例子2:.\… 匹配所有表,则每个表都会发送到各自表名的topic上
- 例子3:test 指定匹配对应的库,一个库的所有表都会发送到库名的topic上
- 例子4:test\…* 指定匹配的表达式,针对匹配的表会发送到各自表名的topic上
- 例子5:test,test1\.test1,指定多个表达式,会将test库的表都发送到test的topic上,test1\.test1的表发送到对应的test1_test1 topic上,其余的表发送到默认的canal.mq.topic值
为满足更大的灵活性,允许对匹配条件的规则指定发送的topic名字,配置格式:topicName:schema 或 topicName:schema.table
- 例子1: test:test\.test 指定匹配的单表,发送到以test为名字的topic上
- 例子2: test:.\… 匹配所有表,因为有指定topic,则每个表都会发送到test的topic下
- 例子3: test:test 指定匹配对应的库,一个库的所有表都会发送到test的topic下
- 例子4:testA:test\…* 指定匹配的表达式,针对匹配的表会发送到testA的topic下
- 例子5:test0:test,test1:test1\.test1,指定多个表达式,会将test库的表都发送到test0的topic下,test1\.test1的表发送到对应的test1的topic下,其余的表发送到默认的canal.mq.topic值
canal.mq.partitionHash 表达式说明
canal 1.1.3版本之后, 支持配置格式:schema.table:pk1^pk2,多个配置之间使用逗号分隔
- 例子1:test\.test:pk1^pk2 指定匹配的单表,对应的hash字段为pk1 + pk2
- 例子2:.\…:id 正则匹配,指定所有正则匹配的表对应的hash字段为id
- 例子3:.\…: p k pk pk 正则匹配,指定所有正则匹配的表对应的hash字段为表主键(自动查找)
- 例子4: 匹配规则啥都不写,则默认发到0这个partition上
- 例子5:.\… ,不指定pk信息的正则匹配,将所有正则匹配的表,对应的hash字段为表名。按表hash: 一张表的所有数据可以发到同一个分区,不同表之间会做散列 (会有热点表分区过大问题)
- 例子6: test\.test:id,.\…* , 针对test的表按照id散列,其余的表按照table散列
注意:多条匹配规则之间是按照顺序进行匹配(命中一条规则就返回)
mq顺序
binlog本身执行时是由顺序的。数据放到mq中,可以通过对于分区的相关配置来确保顺序。
canal支持MQ数据的几种路由方式:单topic单分区,单topic多分区、多topic单分区、多topic多分。
- canal.mq.dynamicTopic,主要控制是否是单topic还是多topic,针对命中条件的表可以发到表名对应的topic、库名对应的topic、默认topic name
- canal.mq.partitionsNum、canal.mq.partitionHash,主要控制是否多分区以及分区的partition的路由计算,针对命中条件的可以做到按表级做分区、pk级做分区等
- 单topic单分区,可以严格保证和binlog一样的顺序性,缺点就是性能比较慢,单分区的性能写入大概在2~3k的TPS
- 多topic单分区,可以保证表级别的顺序性,一张表或者一个库的所有数据都写入到一个topic的单分区中,可以保证有序性,针对热点表也存在写入分区的性能问题
- 单topic、多topic的多分区,如果用户选择的是指定table的方式。保障的是表级别的顺序性,存在热点表写入分区的性能问题;如果指定pk hash的方式,那只能保障的是一个pk的多次binlog顺序性,性能会最好。但如果业务上有pk变更或者对多pk数据有顺序性依赖,就会产生业务处理错乱的情况。但是一定要注意:如果有pk变更,pk变更前和变更后的值会落在不同的分区里,业务消费就会有先后顺序的问题
mq性能
1.1.5版本可以在5k~50k左右。具体参考
CanalDeployer配置
属性配置
canal.properites配置
canal.deployer在1.1.4之后,通过canalAdmin进行管理配置之后,只需要配置与canalAdmin相关的属性即可,其余的属性在集群的主配置中统一配置即可。如果是单机不用canalAdmin的,直接配置canal.properites的。
如果是通过canalAdmin配置的。使用canal_local.properties文件。
# register ip 如果没有配置,服务会自动获取运行时所在的服务器ip放入。这里也可以不用配置
canal.register.ip =
## canalServer与canalAdmin进行通信的配置
canal.admin.manager = 127.0.0.1:8089
canal.admin.port = 11110
canal.admin.user = admin
canal.admin.passwd = 4ACFE3202A5FF5CF467898FC58AAB1D615029441
# 是否开启自动注册模式
canal.admin.register.auto = true
# 可以指定默认注册的集群名,如果不指定,默认注册为单机模式
canal.admin.register.cluster = canal_cluster
# 注册的名称
canal.admin.register.name = node_01
关于admin.user和admin.passwd
canal.admin.passwd存放的是密文。是canalAdmin中application.yml中对应的密码密文处理。
生产方式如下,去掉首*。
select password('admin')
+-------------------------------------------+
| password('admin') |
+-------------------------------------------+
| *4ACFE3202A5FF5CF467898FC58AAB1D615029441 |
+-------------------------------------------+
注意: canal-server会以这个密文和canal-admin做请求,同时canal-admin也会以密码原文生成加密串后和canal-server进行admin端口链接,所以这里一定要确保这两个密码内容的一致性
日志配置
conf下经常需要用到的另外配置就是关于日志的。可以通过 logback.xml进行相关的配置。
一般仅仅配置log的存放位置。默认是${canal.deployer}下
启动
conf下会包含canal.properties/canal_local.properties两个文件,默认配置会以canal.properties为主,如果要启动为对接canal-admin模式,可以有两种方式:
- 指定为local配置文件
sh bin/startup.sh local
- 变更默认配置,比如删除canal.properties,重命名canal_local.properties为canal.properties
启动之后,相关的日志可以查看log/canal/canal.log。
正常启动之后,在canalAdmin中Server管理菜单中看到:
 考虑到集群。我们再额外启动2个的。各个配置文件中
考虑到集群。我们再额外启动2个的。各个配置文件中canal.admin.register.name进行修改下即可

踩坑注意: 如果是单机上,启动多个canalServer时,一些端口信息要错开。比如我本地配置的时候
###### canal.properites文件
# node_03 中配置的如下:
canal.port = 11131
canal.metrics.pull.port = 11132
canal.admin.port = 11130
# node_02 中配置的如下:
canal.port = 11121
canal.metrics.pull.port = 11122
canal.admin.port = 11120
# node_01 中配置的如下:
canal.port = 11111
canal.metrics.pull.port = 11112
canal.admin.port = 11110
###### start.bat中关于
set JAVA_DEBUG_OPT= xxxxxxx ,address=9099,xxxxx
# node_01设置:
set JAVA_DEBUG_OPT= xxxxxxx ,address=9099,xxxxx
# node_02设置:
set JAVA_DEBUG_OPT= xxxxxxx ,address=9098,xxxxx
# node_03设置:
set JAVA_DEBUG_OPT= xxxxxxx ,address=9097,xxxxx
rocketMQ安装
这里就不细说,详情参考官网
客户端消费
rocketMQ方式消费的
import lombok.AllArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.apache.rocketmq.common.message.MessageExt;
import org.apache.rocketmq.spring.annotation.RocketMQMessageListener;
import org.apache.rocketmq.spring.core.RocketMQListener;
import org.springframework.stereotype.Service;
@Service
@RocketMQMessageListener(topic = "search-client-synchronizer_topic_canal",
consumerGroup = "GID_search-client-synchronizer_topic_canal")
@Slf4j
@AllArgsConstructor
public class CanalConsumerListener implements RocketMQListener<MessageExt> {
@Override
public void onMessage(MessageExt messageExt) {
log.info("下架活动入参,messageExt:{}",messageExt);
String tags = messageExt.getTags();
log.info("tags为: {}", tags);
log.info("body为:{}", new String(messageExt.getBody()));
}
}
结果数据 以 delete的执行为例:
 其余的自行尝试即可。
其余的自行尝试即可。
直接client方式消费的
引入响应的SDK
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.client</artifactId>
<version>1.1.0</version>
</dependency>
消费代码
具体可以参考
- Simple客户端例子:SimpleCanalClientTest
- Cluster客户端例子:ClusterCanalClientTest
核心的逻辑都是建立连接,进行订阅
// 1:基于zookeeper动态获取canal server的地址,建立链接,其中一台server发生crash,可以支持failover
CanalConnector connector = CanalConnectors.newClusterConnector("127.0.0.1:2181", destination, "canal", "canal");
// 2: 单台 根据ip,直接创建链接,无HA的功能
String destination = "example";
String ip = AddressUtils.getHostIp();
CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress(ip, 11111),
destination,
"canal",
"canal");
#核心处理逻辑一致
while (running) {
try {
MDC.put("destination", destination);
#建立连接
connector.connect();
# 开始订阅。注意注意:如果这里调整了,会影响canalServer中的过滤配置的
# 比如instance.properites中配置的canal.instance.filter.regex=bz_goods.item_sku。
# 但是我们的的subsribe(".*\\..*")。那就会监听到所有库表的,filter的过滤被替换了。
connector.subscribe();
while (running) {
#// 获取指定数量的数据
Message message = connector.getWithoutAck(batchSize);
long batchId = message.getId();
int size = message.getEntries().size();
if (batchId == -1 || size == 0) {
// try {
// Thread.sleep(1000);
// } catch (InterruptedException e) {
// }
} else {
printSummary(message, batchId, size);
printEntry(message.getEntries());
}
if (batchId != -1) {
connector.ack(batchId); // 提交确认
}
}
} catch (Throwable e) {
logger.error("process error!", e);
try {
Thread.sleep(1000L);
} catch (InterruptedException e1) {
// ignore
}
connector.rollback(); // 处理失败, 回滚数据
} finally {
connector.disconnect();
MDC.remove("destination");
}
}
再次提醒: filter需要和instance.properties的canal.instance.filter.regex一致,否则subscribe的filter会覆盖instance的配置,如果subscribe的filter是.…,那么相当于你消费了所有的更新数据。
在开发调试过程中,一段时间再运行canalServer时,碰到这样的问题:
2021-08-19 17:02:11.504 [destination = synToES , address = /127.0.0.1:3306 , EventParser] WARN c.a.o.c.p.inbound.mysql.rds.RdsBinlogEventParserProxy - prepare to find start position just last position
{"identity":{"slaveId":-1,"sourceAddress":{"address":"love.com","port":3306}},"postion":{"gtid":"","included":false,"journalName":"mysql-binlog.000007","position":79130,"serverId":100,"timestamp":1628768658000}}
2021-08-19 17:02:11.504 [destination = synToES , address = /127.0.0.1:3306 , EventParser] WARN c.a.o.c.p.inbound.mysql.rds.RdsBinlogEventParserProxy - ---> find start position successfully, EntryPosition[included=false,journalName=mysql-binlog.000007,position=79130,serverId=100,gtid=,timestamp=1628768658000] cost : 2ms , the next step is binlog dump
2021-08-19 17:02:11.508 [destination = synToES , address = /127.0.0.1:3306 , EventParser] ERROR c.a.o.canal.parse.inbound.mysql.dbsync.DirectLogFetcher - I/O error while reading from client socket
java.io.IOException: Received error packet: errno = 1236, sqlstate = HY000 errmsg = Could not find first log file name in binary log index file
这是应为这个instance启动的时候,会再次读取上次的节点位置。但是我们的binlog配置了过期删除配置,找不到 mysql-binlog.000007 了。所以报错的。这个时候主要有几种处理
1.如果使用集群了,同时canal.properites配置 canal.instance.global.spring.xml = classpath:spring/default-instance.xml ,这个关于节点位置的信息会存放到zk的对应节点中。可以删除对接节点的数据重新运行。
2.如果是用于开发调试的。可以 使用canal.properites配置 canal.instance.global.spring.xml = classpath:spring/memory-instance.xml 。这个节点位置都是存放内存中,每次重启都是从头开始执行。
3.还可以通过设置instance.properites的canal.instance.master.journal.name=和canal.instance.master.position=来配置每次启动时,读取的节点位置。
4.如果不是zk集群,可以直接删除canal.deploye下conf中对应的 ${instance}。














 4020
4020











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









