







一、Redis的跳表数据结构介绍
1. 什么是跳表
跳表(Skip List)是一种 基于有序链表 的随机化数据结构,通过 多层索引 实现快速查找、插入和删除操作,平均时间复杂度为 O(log N),最坏情况下为 O(N)。它由 William Pugh 在 1990 年提出,初衷是替代平衡树(如红黑树),但实现更简单。
跳表的通俗理解:
想象在一栋 10 层的图书馆 找一本书:
电梯(顶层索引):直接到 5 楼,发现目标在更高层。
扶梯(中层索引):从 5 楼坐到 8 楼,确认目标在 8~10 楼。
步行(底层):从 8 楼走到 9 楼,找到书。
跳表的作用就是帮你快速跳过不需要的楼层
2. 跳表的特点
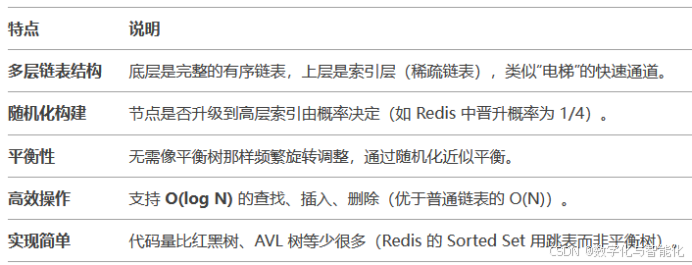
3、跳表 和平衡树的对比
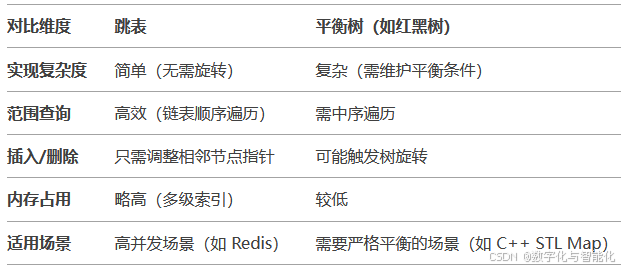
4、跳表的优缺点
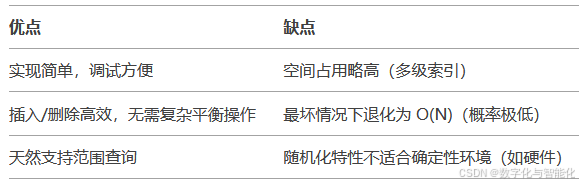
5. 应用场景
【1】Redis 的 Sorted Set
核心实现:跳表 + 哈希表(哈希表存储成员到分数的映射,跳表按分数排序)。
为什么用跳表?
-- 支持 O(log N) 的范围查询(如 ZRANGE)。
-- 比平衡树更适合高并发(无锁优化更简单)。
【2】LevelDB / RocksDB
跳表用作内存中的有序数据结构(MemTable),加速写入和查询。
【3】其他场景
-- 需要有序且频繁插入/删除的场景(如实时排行榜)。
-- 替代平衡树的简化方案(当代码可读性优先时)
二、分布式锁
1. SETNX + EXPIRE 方案及其原子性问题
基本实现方式:
SETNX lock_key uni
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











