







一、使用shell脚本自动安装配置准备
安装前提:安装搭建Hadoop,不能使用超级用户,需要新建一个用户
1. 已经安装好一台centos
(1) centos已经安装wget、net-tools、vim
(2) centos已经安装jdk,并已经设置好环境变量
(3) centos的防火墙已关闭,或者已经开放hadoop的端口9870、9868、8088
2. 创建用户
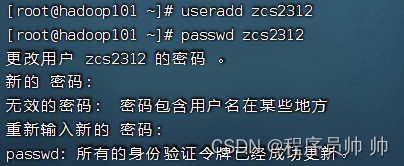
(1) 创建一个为zcs2312的用户
useradd zcs2312
(2) 设置用户zcs2312密码
passwd zcs2312
根据提示设置密码
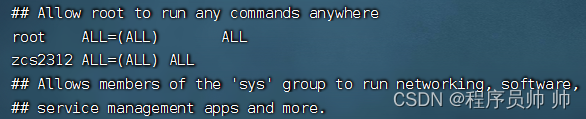
(3) 设置用户zcs2312能够使用sudo命令以root权限执行任务
visudo
在打开的文件中,找到以下行:
##Allow root to run any commands anywhere
root ALL=(ALL) ALL
在该行下方添加以下内容,以允许新用户使用sudo:
zcs2312 ALL=(ALL) ALL
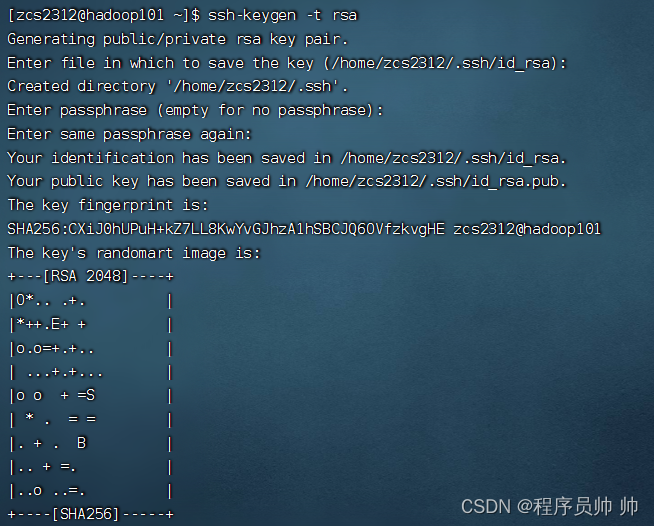
3. 使用用户zcs2312登录centos
(1) 登录之后,执行以下命令,然后连续点三下回车生成SSH密匙对
ssh-keygen -t rsa
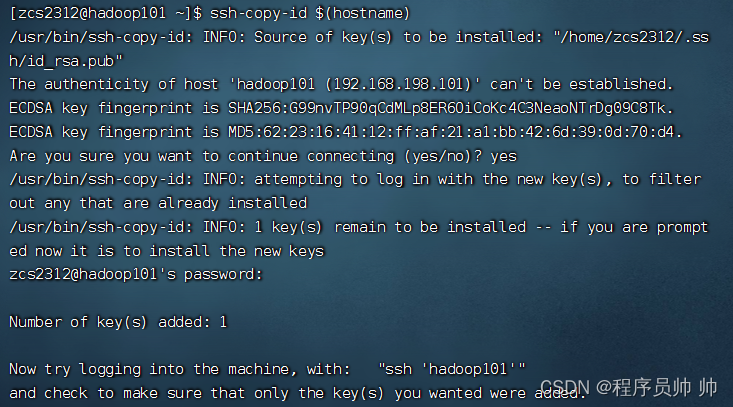
(2) 把密匙对分发给本机,让本机可以免密登录
ssh-copy-id $(hostname)
(3) 给/opt目录增加写入权限
sudo chmod a+w /opt
二、使用shell脚本自动下载安装配置hadoop(单机版)
1. 自动下载安装配置的shell脚本
(1) 把这个shell脚本保存为install_hadoop.sh文件,然后上传至/tmp目录下
#!/bin/bash
# 安装版本
zk_version="3.1.3"
# 安装目录
zk_installDir="/opt/module"
# 主机名或ip地址
ip_addr=$(ip addr | grep 'inet ' | awk '{print $2}'| tail -n 1 | grep -oP '\d+\.\d+\.\d+\.\d+')
hostname=$(hostname)
install_hadoop() {
local version=$1
local installDir=$2
local host=$3
# 下载地址
local downloadUrl="https://archive.apache.org/dist/hadoop/common/hadoop-$version/hadoop-$version.tar.gz"
# 检查安装目录是否存在,不存在则创建
if [ ! -d "${installDir}" ]; then
echo "创建安装目录..."
sudo mkdir -p "${installDir}"
fi
if test -f /tmp/hadoop-"$version".tar.gz; then
echo "/tmp/hadoop-$version.tar.gz文件已存在"
else
# 下载hadoop
echo "开始下载hadoop..."
wget "$downloadUrl" -P /tmp
fi
if test -d "${installDir}"/hadoop-"$version"; then
sudo rm -rf "${installDir}"/hadoop-"$version"
fi
echo "开始解压hadoop..."
tar -zxvf /tmp/hadoop-"$version".tar.gz -C "${installDir}"
if test -n "$(grep '#HADOOP_HOME' ~/.bashrc)"; then
echo "HADOOP_HOME已存在"
else
# 设置hadoop用户环境变量
echo >> ~/.bashrc
echo '#HADOOP_HOME' >> ~/.bashrc
echo "export HADOOP_HOME=${installDir}/hadoop-${version}" >> ~/.bashrc
echo 'export PATH=$PATH:$HADOOP_HOME/bin' >> ~/.bashrc
echo 'export PATH=$PATH:$AHDOOP_HOME/sbin' >> ~/.bashrc
fi
# 配置hadoop
echo "配置hadoop..."
coresite="\
<configuration>\n\
<!--指定NameNode的地址-->\n\
<property>\n\
<name>fs.defaultFS</name>\n\
<value>hdfs://$host:8020</value>\n\
</property>\n\
<!--指定hadoop数据的存储目录-->\n\
<property>\n\
<name>hadoop.tmp.dir</name>\n\
<value>/opt/module/hadoop-3.1.3/data</value>\n\
</property>\n\
<!-- 配置访问hadoop的权限,能够让hive访问到 -->\n\
<property>\n\
<name>hadoop.proxyuser.root.hosts</name>\n\
<value>*</value>\n\
</property>\n\
<property>\n\
<name>hadoop.proxyuser.root.users</name>\n\
<value>*</value>\n\
</property>\n\
</configuration>\
"
hdfssite="\
<configuration>\n\
<!-- namenode web端访问地址-->\n\
<property>\n\
<name>dfs.namenode.http-address</name>\n\
<value>$host:9870</value>\n\
</property>\n\
<!-- secondarynamenode web端访问地址-->\n\
<property>\n\
<name>dfs.namenode.secondary.http-address</name>\n\
<value>$host:9868</value>\n\
</property>\n\
<property>\n\
<name>dfs.permissions.enabled</name>\n\
<value>false</value>\n\
</property>\n\
</configuration>\
"
mapredsite="\
<configuration>\n\
<!--指定MapReduce程序运行在Yarn上-->\n\
<property>\n\
<name>mapreduce.framework.name</name>\n\
<value>yarn</value>\n\
</property>\n\
<!--历史服务器端地址-->\n\
<property>\n\
<name>mapreduce.jobhistory.address</name>\n\
<value>$host:10020</value>\n\
</property>\n\
<!--历史服务器web端地址-->\n\
<property>\n\
<name>mapreduce.jobhistory.webapp.address</name>\n\
<value>$host:19888</value>\n\
</property>\n\
</configuration>\
"
yarnsite="\
<configuration>\n\
<!--指定MR走shuffle -->\n\
<property>\n\
<name>yarn.nodemanager.aux-services</name>\n\
<value>mapreduce_shuffle</value>\n\
</property>\n\
<!--指定ResourceManager的地址-->\n\
<property>\n\
<name>yarn.resourcemanager.hostname</name>\n\
<value>$host</value>\n\
</property>\n\
<!--环境变量的继承-->\n\
<property>\n\
<name>yarn.nodemanager.env-whitelist</name>\n\
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>\n\
</property>\n\
<!--开启日志聚集功能-->\n\
<property>\n\
<name>yarn.log-aggregation-enable</name>\n\
<value>true</value>\n\
</property>\n\
<!--设置日志聚集服务器地址-->\n\
<property>\n\
<name>yarn.log.server.url</name>\n\
<value>http://$host:19888/jobhistory/logs</value>\n\
</property>\n\
<!--设置日志保留时间为7天-->\n\
<property>\n\
<name>yarn.log-aggregation.retain-seconds</name>\n\
<value>604800</value>\n\
</property>\n\
</configuration>\
"
sed -i '/<configuration>/,/<\/configuration>/c '"$coresite"'' "$installDir"/hadoop-"$version"/etc/hadoop/core-site.xml
sed -i '/<configuration>/,/<\/configuration>/c '"$hdfssite"'' "$installDir"/hadoop-"$version"/etc/hadoop/hdfs-site.xml
sed -i '/<configuration>/,/<\/configuration>/c '"$mapredsite"'' "$installDir"/hadoop-"$version"/etc/hadoop/mapred-site.xml
sed -i '/<configuration>/,/<\/configuration>/c '"$yarnsite"'' "$installDir"/hadoop-"$version"/etc/hadoop/yarn-site.xml
echo $(hostname) > "$installDir"/hadoop-"$version"/etc/hadoop/workers
echo "hadoop的配置文件:core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml都已配置完成"
"$installDir"/hadoop-"$version"/bin/hdfs namenode -format
if [ $? -eq 0 ]; then
echo "格式化namenode成功"
else
echo "格式化namenode失败"
exit 1
fi
rm -rf /tmp/hadoop-"$version".tar.gz
echo "hadoop下载、安装、配置完成"
}
install_hadoop "$zk_version" "$zk_installDir" "$hostname"
(2) 给/tmp/install_hadoop.sh增加执行权限
sudo chmod a+x /tmp/install_hadoop.sh
(3) 执行脚本,等待下载安装配置完成
/tmp/install_hadoop.sh
成功如下图所示:
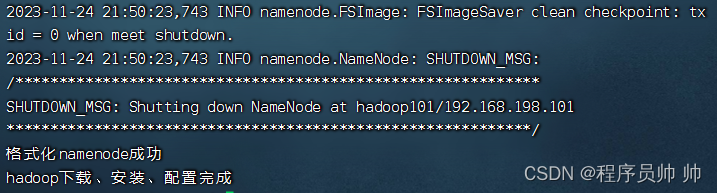
(4) 加载用户环境变量
source ~/.bashrc
2. 启动hadoop
(1) 启动hdfs
/opt/module/hadoop-3.1.3/sbin/start-dfs.sh
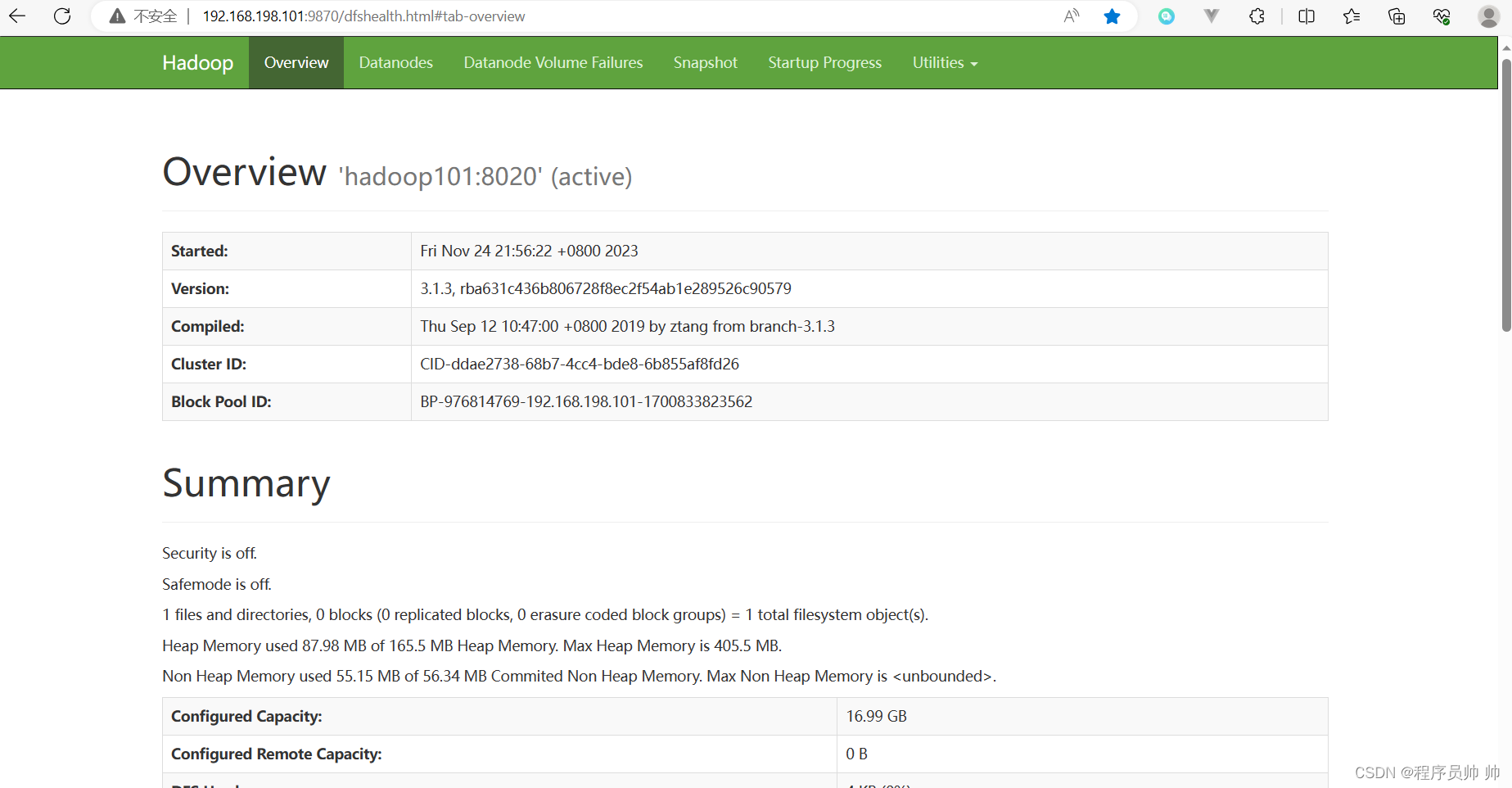
启动成功如下图所示:

浏览器访问http://192.168.198.101:9870,如下图所示:
(2) 启动yarn
/opt/module/hadoop-3.1.3/sbin/start-yarn.sh
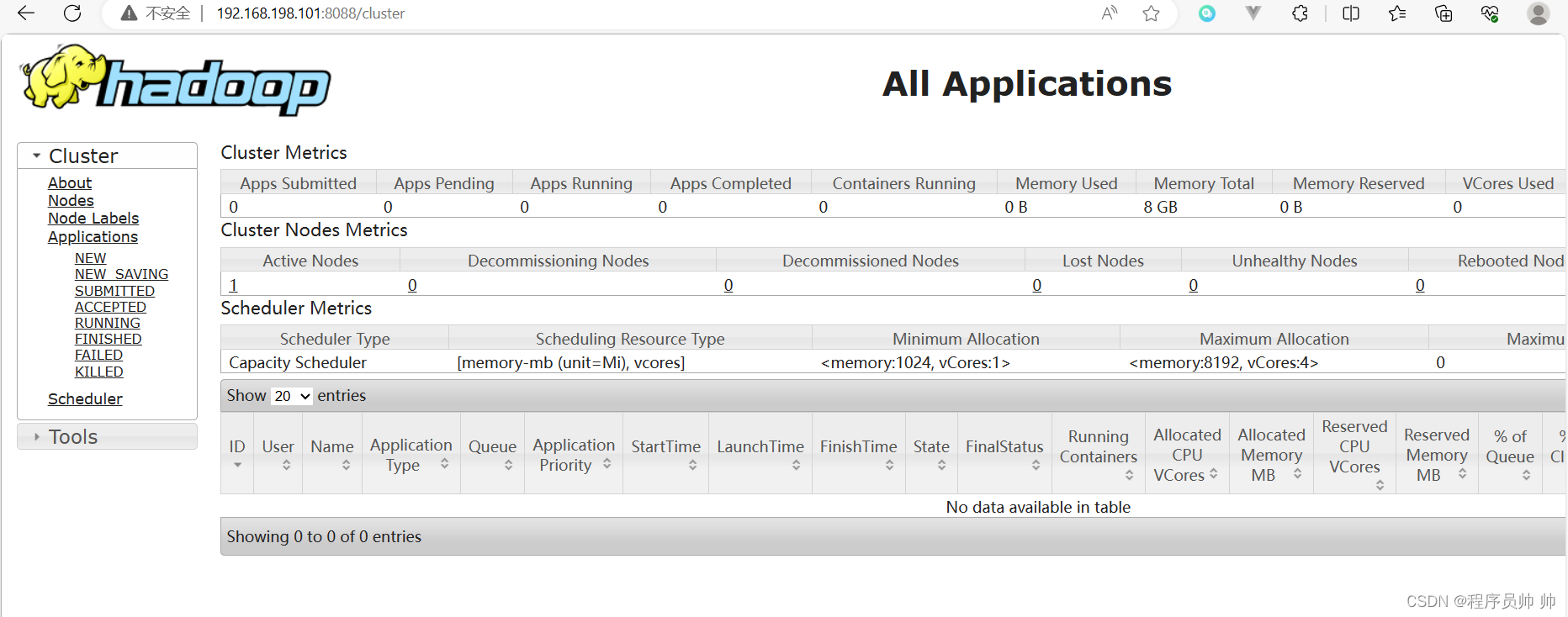
启动成功如下图所示:

浏览器访问http://192.168.198.101:8088,如下图所示:
至此,hadoop单机版下载、安装、配置结束,此配置把hdfs和yarn都部署到同一个主机上。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











