







 该博客详细介绍了如何通过Python调用百度AI的语音合成API,生成并保存MP3文件,以及如何使用playsound库播放生成的语音。代码示例包括获取API Token、设置语音参数和播放合成的语音。
该博客详细介绍了如何通过Python调用百度AI的语音合成API,生成并保存MP3文件,以及如何使用playsound库播放生成的语音。代码示例包括获取API Token、设置语音参数和播放合成的语音。
进入百度AI官网,依次点击:开放能力-> 语音技术 -> 语音合成-> 短文本在线合成-> 立即使用-> 登录
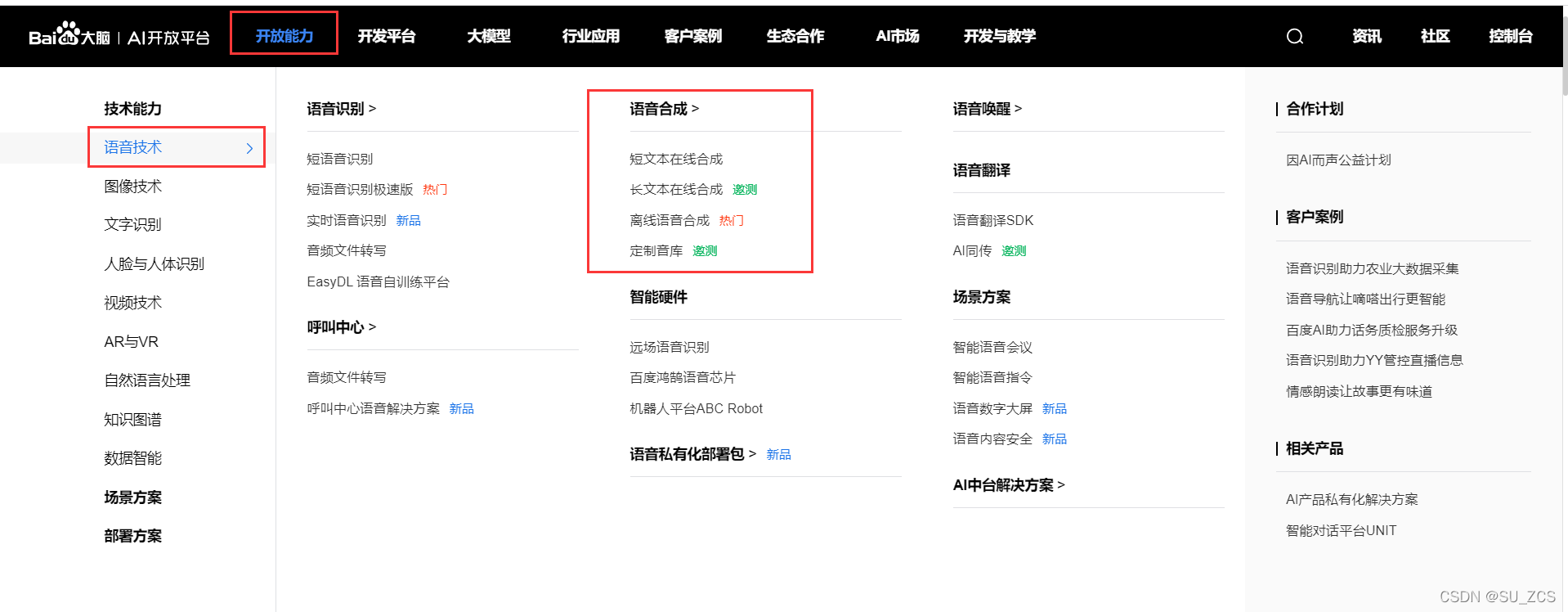
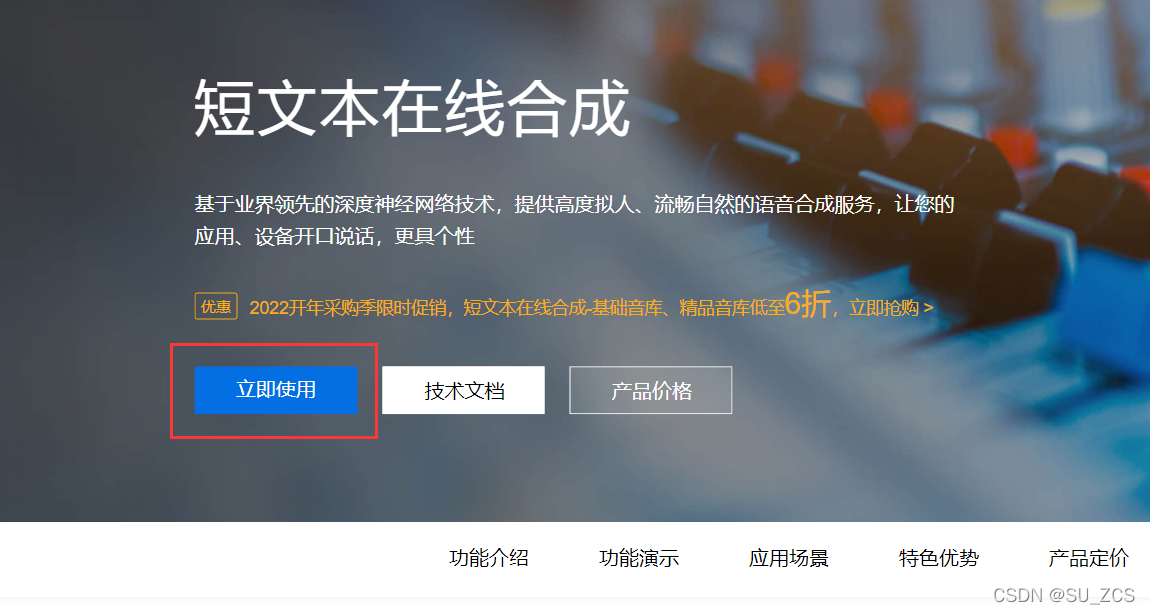
创建应用
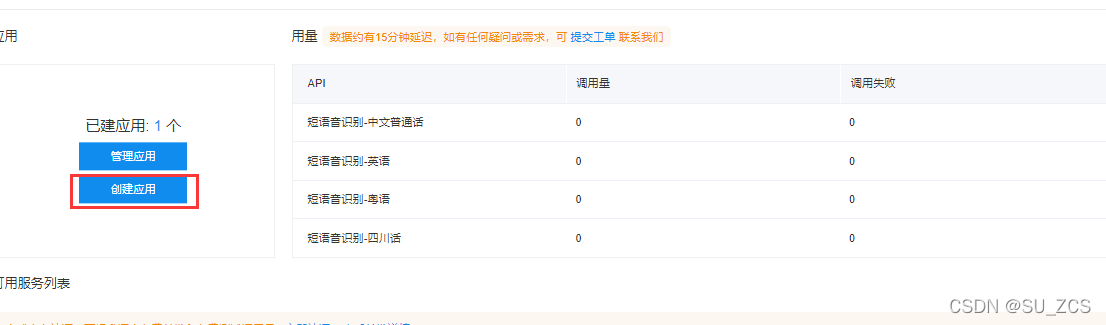
先去领取免费的接口,选择语音合成,然后将需要的接口打对勾,左下角0元领取。
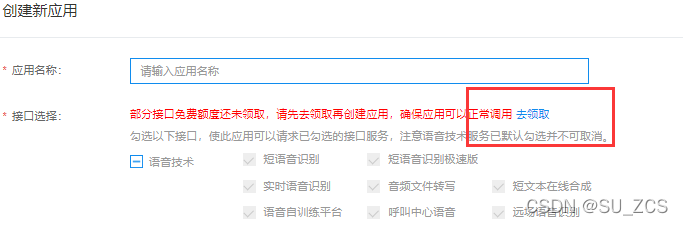
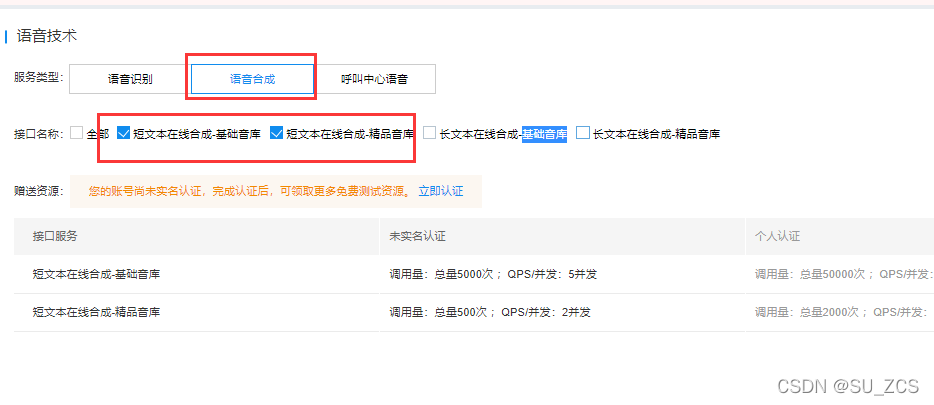
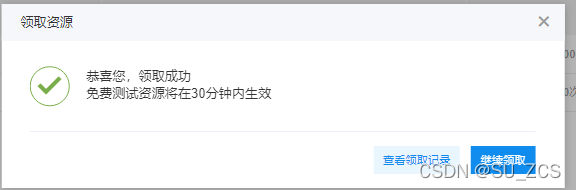
然后在这里填写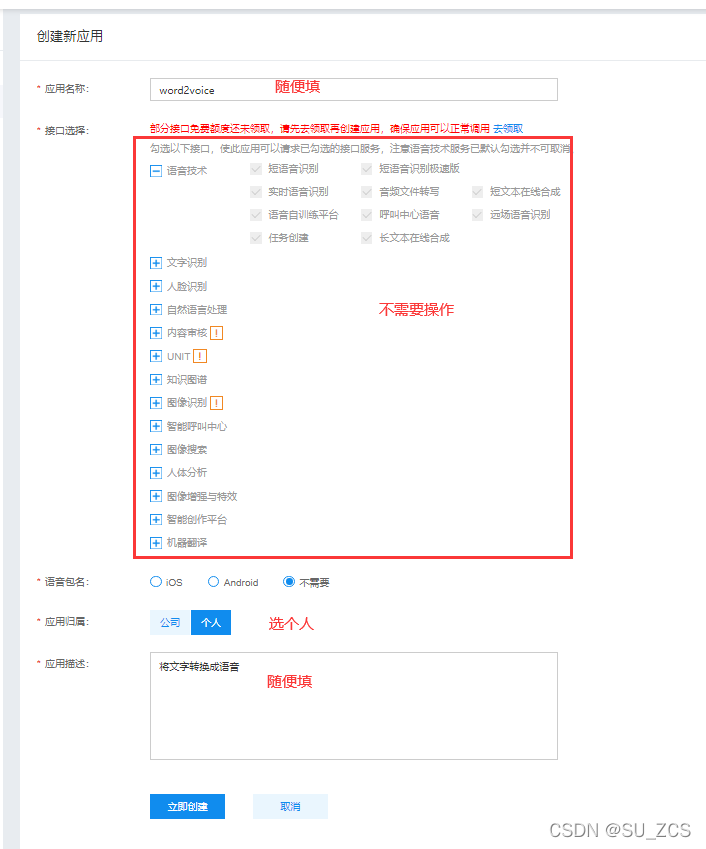
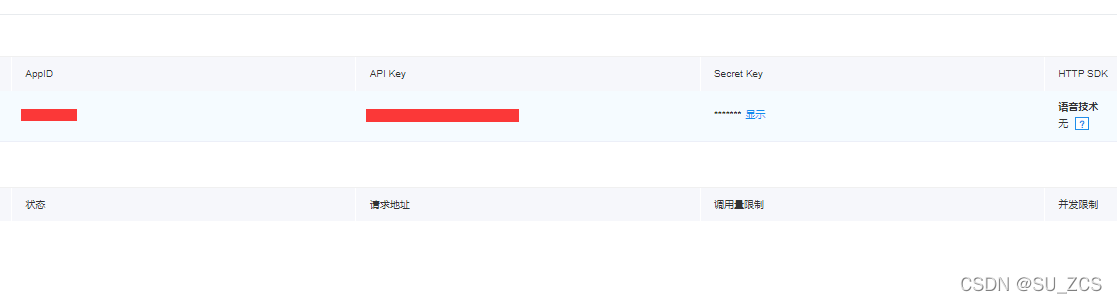
创建完毕,查看应用详情,得到APIKey,SecretKey

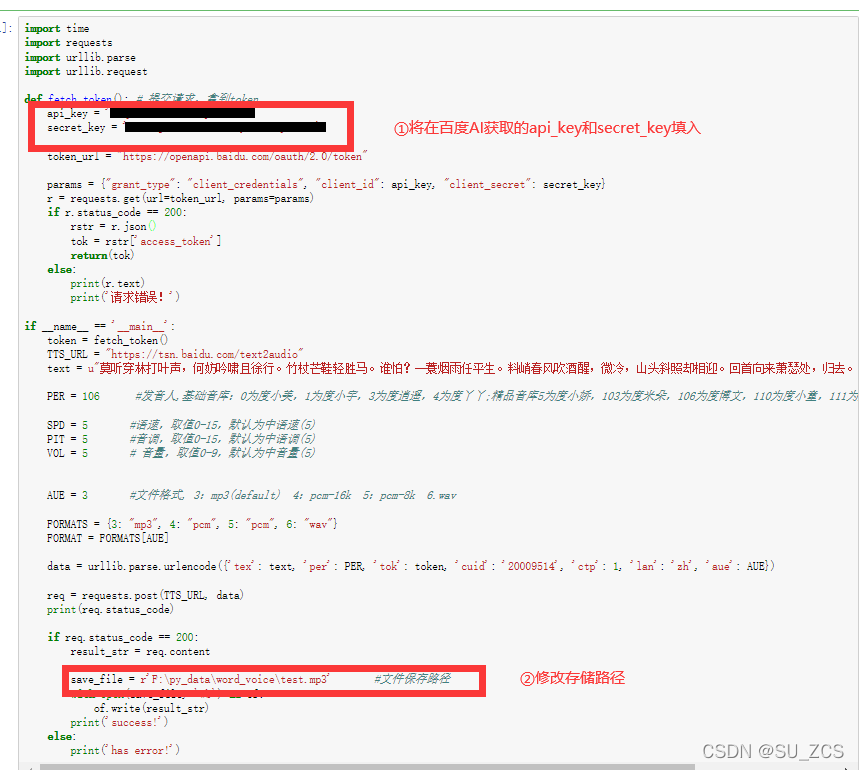
python代码如下:
python代码:
import time
import requests
import urllib.parse
import urllib.request
def fetch_token(): # 提交请求,拿到token
api_key = '?'
secret_key = '?'
token_url = "https://openapi.baidu.com/oauth/2.0/token"
params = {"grant_type": "client_credentials",
"client_id": api_key, "client_secret": secret_key}
r = requests.get(url=token_url, params=params)
if r.status_code == 200:
rstr = r.json()
tok = rstr['access_token']
return(tok)
else:
print(r.text)
print('请求错误!')
if __name__ == '__main__':
token = fetch_token()
TTS_URL = "https://tsn.baidu.com/text2audio"
text = u"莫听穿林打叶声,何妨吟啸且徐行。竹杖芒鞋轻胜马。".encode('utf8')
#发音人,基础音库:0为度小美,1为度小宇,3为度逍遥,4为度丫丫;
#精品音库5为度小娇,103为度米朵,106为度博文,110为度小童,111为度小萌,默认为度小美
PER = 106
SPD = 5 #语速,取值0-15,默认为中语速(5)
PIT = 5 #音调,取值0-15,默认为中语调(5)
VOL = 5 # 音量,取值0-9,默认为中音量(5)
AUE = 3 #文件格式, 3:mp3(default) 4:pcm-16k 5:pcm-8k 6.wav
FORMATS = {3: "mp3", 4: "pcm", 5: "pcm", 6: "wav"}
FORMAT = FORMATS[AUE]
data = urllib.parse.urlencode({'tex': text, 'per': PER,
'tok': token, 'cuid': '20009514',
'ctp': 1, 'lan': 'zh', 'aue': AUE})
req = requests.post(TTS_URL, data)
print(req.status_code)
if req.status_code == 200:
result_str = req.content
save_file = r'F:\py_data\word_voice\test.mp3' #文件保存路径
with open(save_file, 'wb') as of:
of.write(result_str)
print('success!')
else:
print('has error!')效果如图
python读取MP3文件,需要先pip install playsound安装playsound,然后执行代码:
from playsound import playsound
playsound(r'F:\py_data\word_voice\test.mp3') #MP3文件路径将两者合在一起
import time
import requests
import urllib.parse
import urllib.request
from playsound import playsound
def fetch_token(): # 提交请求,拿到token
api_key = '?'
secret_key = '?'
token_url = "https://openapi.baidu.com/oauth/2.0/token"
params = {"grant_type": "client_credentials", "client_id": api_key, "client_secret": secret_key}
r = requests.get(url=token_url, params=params)
if r.status_code == 200:
rstr = r.json()
tok = rstr['access_token']
return(tok)
else:
print(r.text)
print('请求错误!')
if __name__ == '__main__':
token = fetch_token()
TTS_URL = "https://tsn.baidu.com/text2audio"
text = u"莫听穿林打叶声,何妨吟啸且徐行。竹杖芒鞋轻胜马。谁怕?一蓑烟雨任平生。料峭春风吹酒醒,微冷,山头斜照却相迎。回首向来萧瑟处,归去。也无风雨也无晴。".encode('utf8')
PER = 106 #发音人,基础音库:0为度小美,1为度小宇,3为度逍遥,4为度丫丫;精品音库5为度小娇,103为度米朵,106为度博文,110为度小童,111为度小萌,默认为度小美
SPD = 5 #语速,取值0-15,默认为中语速(5)
PIT = 5 #音调,取值0-15,默认为中语调(5)
VOL = 5 # 音量,取值0-9,默认为中音量(5)
AUE = 3 #文件格式, 3:mp3(default) 4:pcm-16k 5:pcm-8k 6.wav
FORMATS = {3: "mp3", 4: "pcm", 5: "pcm", 6: "wav"}
FORMAT = FORMATS[AUE]
data = urllib.parse.urlencode({'tex': text, 'per': PER, 'tok': token, 'cuid': '20009514', 'ctp': 1, 'lan': 'zh', 'aue': AUE})
req = requests.post(TTS_URL, data)
print(req.status_code)
if req.status_code == 200:
result_str = req.content
save_file = r'F:\py_data\word_voice\test.mp3' #文件保存路径
with open(save_file, 'wb') as of:
of.write(result_str)
print('success!')
playsound(save_file)
else:
print('has error!')


















 4606
4606

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











