






 本文分享了作者在求职过程中如何使用Python库Pandas对Excel简历投递数据进行分析,包括数据加载、数据探索、筛选、排序、去重和空值处理等技巧,旨在帮助求职者更好地理解和应用数据科学工具。
本文分享了作者在求职过程中如何使用Python库Pandas对Excel简历投递数据进行分析,包括数据加载、数据探索、筛选、排序、去重和空值处理等技巧,旨在帮助求职者更好地理解和应用数据科学工具。
最近在找工作,面试寥寥无几,就学习了下pandas,学以致用,我每天都会在excel记录一下我的投递简历情况(如图),并用学到的pandas来分析自己的简历投递数据。
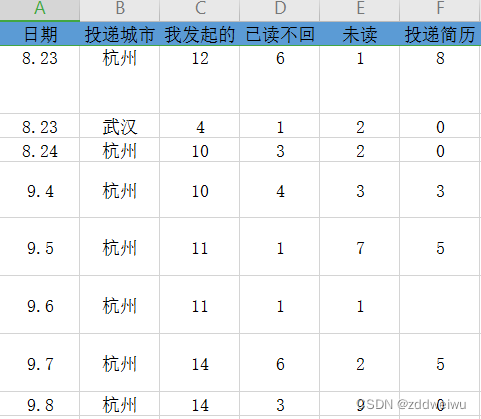
行情实在惨淡,岗位都很少,感觉能投的不多。
我还是把我上周学的总结的pandas知识点发出来,以供大家参考吧。有正在找工作的,也可以借鉴这个方法,把知识用在自己的现实问题上,也会更进一步学以致用,融会贯通。
我个人觉得学习pandas最简单的入手方式就是分析自己的excel数据。这里会结合sql语句来说,对应掌握sql知识的人来说,这样会更容易学习新的知识吧。
df=pd.read_excel('路径')
先整体看一下,比如看一下每个列的数据类型df.dtypes。而在pandas包里有int64和object类型(字符串类型),看一下各统计值用df.describe()
看有多少行和列呢?df.shape
如果要给字段建立索引呢?df=df.set_index('投递城市'),然后如果我要只看杭州的数据怎么办?df.loc['杭州']。如果我要取消索引就是用df.reset_index()。
那么如果想看8月23的,并且投递简历数大于5的数据。
df[(df['日期']==8.23)&(df['投递简历']>5)],这就是sql中的where条件,&就是and,
或者还可以写成df[df['日期']==8.23][df['投递简历']>5],如果觉得[]多了,看晕了,那说明看的方式不对,我写的时候是先写这个df[][],先框架后细节,就不会出错,做任何事都是如此,一下子陷入细节里,只会浪费更多时间。
只不过原来在sql中表名.投递简历>5,在这里变成了表名['投递简历']>5,其实有区别吗?在我看来没什么区别的。
如果我要排序呢?就可以用df.sort_values('列名',ascending=False),按该列名排序,默认是升序,这里false就是倒序。
如果我要对列分组呢就可以用groupby('列名'),对两列进行分组呢groupby([df['列名'],df['列名']])或者是groupby(['列名','列名']),其实可以看出df['列名'],df['列名']等价于'列名','列名'。那如果我对两列进行聚合之后,要展示特定的列的数据呢?df.groupby(['列名','列名'])[['列名']],注意这后面是两个括号,只给一个括号的话df.groupby(['列名','列名'])['列名']就变成seris
我要聚合呢?df.groupby('投递城市').sum(),对我投递城市聚合,只展示了投递简历这一列,df.groupby('投递城市')[['投递简历']].sum()
如果我要对某些列做特定的聚合计算呢?这就是比如像是sql的:select count(日期),sum(我发起的) from 表 group by 投递城市
而在pandas里怎么做的呢?很简单:df.groupby('投递城市').agg({'日期':'count','我发起的':'sum'});
对其中两列分组groupby,然后对所有列应用相同的三种函数,这时候可以先定义一个functions=['count','sum','mean'].然后df.groupby['列名','列名'].agg(functions)
在sql中我可以只展示某些列,select 列名,列名 from 表名
那么在pandas怎么做呢?df[['列名','列名','列名']]
在sql中我既可以展示哪些列又可以展示哪些行,select 列名,列名 from 表名 where rownum<=5
在pandas里怎么做呢?利用切片,df[0:6][['列名','列名','列名']],要展示第二行到第10行呢
df[1:11][['列名','列名','列名']],还有没有其他的方法,当然有,loc()函数,loc是location位置的缩写,一下子你就知道要传入两个参数,才能确定位置对吧,第一个参数是关于行的,第二个位置是关于列的,df.loc[0:3,['列名','列名','列名']]
在sql中我们会用order by 来排序,那么在pandas呢?需要用sort-values方法了,最简单的方式就是df.sort_values(by ='日期'),按日期进行排序,默认为升序,而如果要对两列进行排序呢,都是降序呢?df.sort_values(['日期','我发起的'],ascending=[True,True])
如何看是否存在重复数据呢?df.duplicated(),返回每行的布尔值,true就代表这行和前面重复了。df.duplicated('投递城市')只看投递城市这一列有哪些重复的。
如何删除重复数据呢?df.drop_duplicates()
如何查看一列有多少空值呢?df.isnull().sum()
空值转化为0?df.fillna(0),df.fillna({'经验总结':0})这是特定列转为空值。
去掉有空值的行?df.dropna(),df.dropna({'经验总结’)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









