







1. HashMap和哈希表
HashMap本质上就是哈希表,其底层实现就是围绕哈希表展开的,哈希表的核心思想就是让key和存储位置建立一一对应关系,这样我们就可以通过
key直接获得对应的value。好比我们可以通过索引可以直接获得数组中对应某个值一样,这种一一对应关系我们是通过哈希函数构造出来的。
哈希函数实现方式:除留余数法 result = key MOD p;
但是通过哈希函数寻址的过程可能出现冲突(碰撞),即若干个不同的key经过哈希函数计算出的地址相同,此时会将所有哈希地址冲突的记录存储在同
一个线性链表中(链地址法)。
2.HashMap具体实现
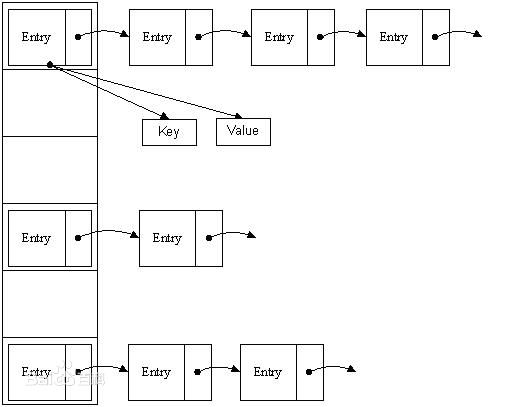
HashMap的实现采用了哈希函数(除留余数法)确定数组中存储位置和链地址法解决哈希地址冲突的方案,这样就涉及到两种基本的数据结构:数组和链
表。数组的索引就是对应的哈希地址,存放的是一个Entry节点,Entry的next存放的是哈希地址冲突的不同记录。
数组:
/**
* The table, resized as necessary. Length MUST Always be a power of two.
*/
transient Entry[] table;static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
final int hash;
}除留余数法形式的哈希函数:
/**
* Returns index for hash code h.
*/
static int indexFor(int h, int length) {
return h & (length-1); //和除留余数等价
}具体流程:
1. 当我们往HashMap中put元素的时候,先根据key的hashCode调用哈希函数计算hash值,根据hash值得到这个元素在数组中的位置。
2. 如果数组在该位置上没有元素,就直接将Entry结点放到此数据的该位置上。
3. 如果数组在该位置上已经存放有其他Entry结点,那么这个位置上的结点将以链表的形式存放。(用next引用记住它)
4. 数组中存储的是最后插入的Entry结点,即新加入的放在链头,最先加入的在链尾
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
if (key == null)
return putForNullKey(value);
int hash = hash(key);
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
http://www.cnblogs.com/ITtangtang/p/3948798.html















 2210
2210











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









