







一、为啥数据库要用 B + 树当索引?
想象你有一本超级厚的书,里面记着所有学生的成绩。如果没有目录(索引),找 “张三考了多少分” 就得一页一页翻,慢死了!
索引就像目录,但普通的 “二叉树目录”(比如字典的拼音目录)有个问题:数据越多,目录层数越高,比如找一个词可能要翻 10 次目录页,每次翻页就像数据库读一次磁盘,很慢!
而 B + 树目录 是 “多叉目录”,每层目录能放超多关键词,比如一层目录能列 1000 个关键词,这样目录层数就很少(比如 3 层就能管上亿条数据),找东西时翻目录页的次数(磁盘读取次数)就大大减少,速度就快啦!
二、B + 树长啥样?分两拨 “人” 干活!
下图为从123递增插入所形成的B+树:
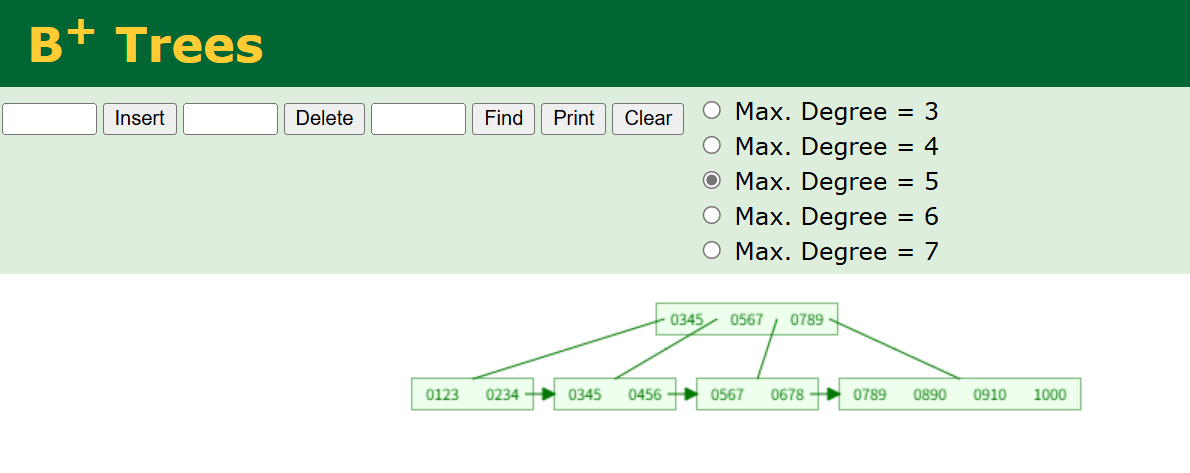
B + 树分两种节点:
- “目录节点”(非叶子节点):只记关键词和指向下面目录的指针,不存具体数据。比如记 “100-200 分”“200-300 分” 这种范围,帮你快速定位方向。
- “数据节点”(叶子节点):存真正的数据(比如学生姓名 + 分数),而且所有数据节点像手链一样用链表串起来,排好序。比如找 “80-90 分” 的学生,找到 80 分的节点后,顺着链表往后捋就行,不用再翻目录了!
这样设计的好处:
- 目录节点只做 “导航”,所以每个目录页能塞更多关键词,目录层数少,找方向快;
- 数据节点排好序还串起来,查范围数据(比如 “大于 60 分”)时,顺着链表一路扫过去,效率超高!
三、MySQL 里的两种 “目录”:聚簇索引和非聚簇索引
-
聚簇索引(InnoDB 默认):
相当于 “数据和目录绑在一起”。比如主键是学生学号,目录里每个关键词(学号)对应的叶子节点,直接存了这个学生的所有信息(姓名、分数、班级)。查学号时,找到目录后直接拿到数据,一步到位! -
非聚簇索引(比如普通索引):
相当于 “目录里只记学号,不存具体数据”。比如给 “姓名” 建索引,目录里存 “张三→学号 1001”“李四→学号 1002”,当你查 “张三多少分” 时:- 先通过姓名索引找到学号 1001(这一步快);
- 再通过学号(主键)去聚簇索引里查具体数据(这一步叫 “回表”,相当于根据学号再翻一次目录找数据)。
优化技巧:如果查询只需要姓名和分数,就给这两个字段建联合索引,让目录里直接存这俩数据,不用回表,叫 “覆盖索引”。
四、B + 树怎么查数据?举俩栗子
-
精准查询(比如查学号 1001):
从根目录开始,像玩猜数字游戏一样,比如根目录分 “1-1000”“1001-2000”,判断 1001 在右边,就去右边的目录页,直到找到叶子节点里的 1001,直接拿数据(聚簇索引)或学号(非聚簇索引再回表)。 -
范围查询(比如查 60-80 分):
先找到 60 分的节点,然后顺着链表往后走,把 60、61、62……80 分的节点全扫一遍,因为链表是排好序的,一路顺溜扫过去,不用再翻目录页,速度很快!
五、用 B + 树索引的小技巧,别踩坑!
-
主键尽量用 “自增数字”:
比如学号从 1 开始往上加,新数据会乖乖排在目录末尾,不会打乱现有结构。如果主键是乱的(比如随机字符串),插入时可能要频繁拆分目录页,影响速度。 -
索引别太长:
比如给一个超长的文本字段建索引,目录页能存的关键词就少,目录层数变高,查得就慢。尽量选短字段(比如用整数代替长字符串)。 -
避免让索引 “失业”:
- 比如索引是 “姓名”,但你查的时候用
LIKE '%张三'(前面加了通配符),相当于让目录从中间开始找,目录就没法高效定位了,只能全表扫描。 - 字段类型不匹配也会让索引失效,比如索引是数字,你查的时候传了字符串 “1001”,MySQL 可能得转类型,导致索引用不上。
- 比如索引是 “姓名”,但你查的时候用
六、总结:B + 树为啥牛?
- 查得快:目录层数少,翻页(磁盘 I/O)次数少,精准查询和范围查询都在行;
- 数据排好队:叶子节点用链表串起来,范围查询像翻书一样顺着往后翻,不用来回跳目录;
- 分工明确:目录节点只导航,数据节点存数据,各干各的活,效率拉满!
下次写 SQL 时,想想你的索引有没有让 B + 树 “舒服” 工作:比如有没有回表太多?有没有让索引失效的写法?把这些理顺,数据库就能跑更快啦!
(如果还是有点懵,就记住:B + 树是专门为 “在硬盘里快速找数据” 设计的超级目录,比普通目录更省翻页次数,尤其是查范围数据时超好用!)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









