







在客户端发起请求,从服务器拿到html文档后,要做的就是对该文档的解析。因为拿到的html文档是字符流,所以首先要对其进行标签解析,对于html的解析,通过状态机,将字符流转换成几种种类的节点,大概有标签开始,属性,标签结束,注释,CDATA节点几种。
标签解析
对文档流的解析,我们先使用简单的只有四个状态的标签来分析,标签开始状态,标签名称状态,标签闭合状态,文本状态。
取下面这段html代码来分析
<p>text</p>
首先,默认开始的状态为文本状态
- 遇到<,进入标签开始状态
- 遇到p,进入标签名称状态
- 遇到>,将当前的标签发给构造器,转而进入文本状态
- 遇到t,维持文本状态
- 遇到e,维持文本状态
- 遇到x,…
- 遇到t,…
- 遇到<,将文本发送到构造器,进入标签开始状态
- 遇到/,进入标签闭合状态
- 遇到p,进入标签名称状态
- 遇到>,将当前的闭合标签发到构造器
这里可以看到,解析字符流时,是一个一个字符解析的,通过这种标记化算法,来将字符流解析成标签发给构造器。当然,实际上的状态不只四个,要考虑的情况还有很多。比如注释,标签中的属性,CDATA节点等…
上面的标签,解析后就会变成<p>,text,</p>三个“词”,在构造DOM树时就使用这些词来构造。
实际上,我们每读入一个字符,就要进行一次决策,而且这个决策的结果与当前的状态有关。
DOM树的构造
DOM树的构造是通过使用栈这种结构来实现的,尝试构造下面这段简单的结构
(以下为我自己的理解,如有什么错误请各位在评论中指出)
<html>
<body>
<h1></h1>
<div>
<p></p>
<p></p>
</div>
</body>
</html>

将每列看成一次栈的操作,红色的即为出栈,对应下面的树图
黑色背景的为当前指针指向的位置,如果有新的开始标签,则在当前指针下插入该节点,如果为闭合标签,则将指针指到父标签,最后构造成一颗完整的树
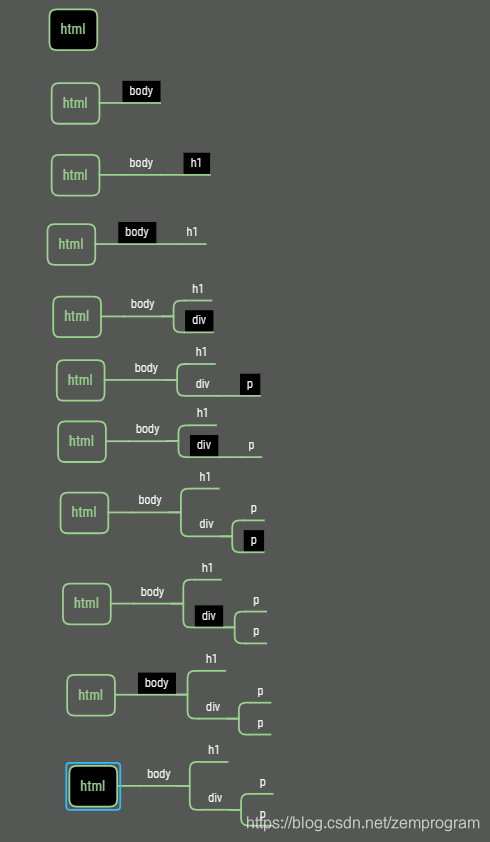
这里因为做图太麻烦。。。,我没有把文本内容添加进去,但实际上处理方式也是一样的。
非单纯的HTML文档树
上面说的是单纯的HTML文档树,如果在解析html时遇到了JavaScript或者css,就会去解析相应的代码,虽然Chrome浏览器做了预解析操作,在渲染引擎收到字节流之后,会开启一个预解析线程,用来分析HTML文件中包含的JavaScript、CSS等相关文件,解析到相关文件之后,预解析线程会提前下载这些文件。但这也只是在外部文件下载的优化,节省了一些下载的时间,因为最终布局树的构建还是需要css和JavaScript,所以还是会造成整个流程的阻塞
遇到JavaScript代码
在解析DOM树时,如果遇到JavaScript代码,就会停下来解析相应的JavaScript代码,此时HTML文档树会被阻塞,这是因为JavaScript可能会对HTML造成一定的影响。
像下面这段代码
<h1 id="before">我是script标签前的标签</h1>
<script>
console.log(document.getElementById('before').innerHTML)
console.log(document.getElementById('after').innerHTML)
</script>
<h1 id="after">我是script标签后的标签</h1>
因为在执行到JavaScript代码时被阻塞,后面的h1标签还没被解析,所以获取不到这个DOM节点,document.getElementById('after')也就变成null了,所以控制台会报下面的错

这也是我们平时说要将JavaScript代码写在</body>之前的原因之一。即使我们将js代码放到另一个js文件中,js文件的下载依然会阻塞DOM解析。
此外,借助这个例子我们也知道了,html解析并非是将整个下载完之后才解析的,而是以字节流的形式传输进来解析的
当然,如果在引入文件时要做异步处理,使其不造成阻塞的话,可以加上async或defer。
这里要注意的是,虽然async和defer都可以做到异步,但还有一些差异,使用async标志的脚本文件一旦加载完成,会立即执行;而使用了defer标记的脚本文件,需要等到DOMContentLoaded事件之后执行。
现在我们知道了JavaScript是如何阻塞DOM树的构建的,那么接下来,我们看看另外一种情况:假如我们在js里面对DOM树上的元素样式进行了操作,那实际上,我们是需要CSSOM对象才能做到
但是在JavaScript解析之前,我们无法得知这段JavaScript代码是否对样式进行了操作,所以渲染引擎在遇到JavaScript的时候,不管脚本是否操纵了CSSOM,都会执行css文件下载,解析操作生成CSSOM,再去解析JavaScript
所以JavaScript是依赖样式的,所以我们还要分析一下css的阻塞
遇到css代码
我们在上面已经提到了,JavaScript依赖样式,但我们还是先从最简单的只有css阻塞的情况说起
只有外部css文件
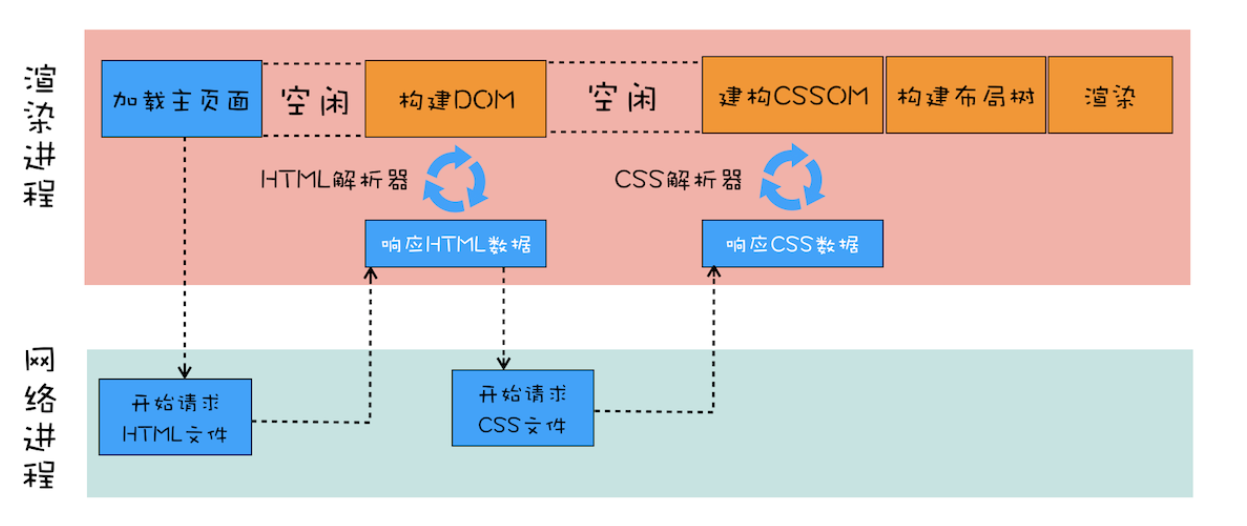
看看上面这张图,这是在引入外部css文件的情况,流程如下
- 首先会先发起主页面的一个请求,这个发起方可能是渲染进程,也可能是浏览器进程,发起的进程被放到网络进程中执行
- 网络进程得到html文件后,开始对这个文件进行解析,构建DOM树,在解析过程中,发现外部css文件,开启预解析操作,在网络进程请求后面要用到的css文件
- 当DOM树和css文件都下载好了之后,开始构建CSSOM树
- 根据DOM树和CSSOM树构建布局树,最后根据布局树进行渲染
从这个流程中,我们可以清晰地看到,css对整个流程的阻塞,还是在于下载的过程,可以看到上面的构建DOM后面有空闲的时间,如果css足够小,这部分可能就不存在。而这部分为什么是空闲的,上面的流程也说了,布局树是根据DOM树和CSSOM树构成的,外部css文件还没下载好,CSSOM树是无法构建的,所以在外部css文件下载好之前的这段时间,渲染进程无事可做,只能空闲
知道了css文件对构建过程的阻塞,我们再聊聊css文件对JavaScript解析的阻塞
首先我们要知道,CSSOM除了是为了构建布局树,还有一个作用,它可以给JavaScript提供操作样式的接口,而上面也提到了,我们无法在解析JavaScript过程判断它是否有去操作样式,所以只能直接阻塞所有的JavaScript代码,直至CSSOM树构建完成
我们在上面提到了,css加载会阻塞DOM树构建,但上面说到的,也只是阻塞了布局树的构建,如何阻塞到DOM树的构建呢,这需要结合JavaScript阻塞DOM和css阻塞JavaScript来解释
引入css外部文件同时写入内联JavaScript
当我们在引用css文件的代码中,增加了一个script标签,不引入外部js文件,直接在标签里写相应的js代码,就会出现下图的情况
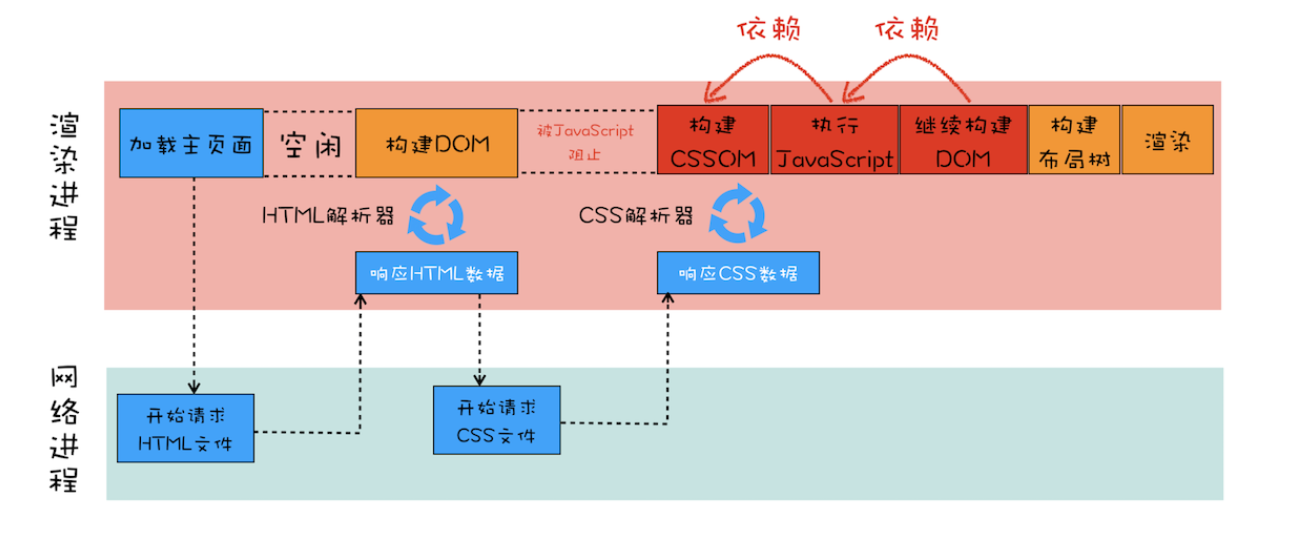
这里我们可以看到,与上面那张图不一样的地方有亮点,第一点,在构建DOM树之后,css文件下载完成之前,那部分透明的,没有操作的地方,变成了被JavaScript阻止,而在构建CSSOM后面,多了执行JavaScript和继续构建DOM
后面多了执行JavaScript我们能理解,毕竟我们写入了JavaScript代码了,但是另外两个怎么解释呢
我们要结合上面说的,首先,我们在解析DOM树的时候,遇到JavaScript代码,那么就会停下来,解析这段JavaScript代码,但是,此时出现了一个问题,这个页面有引入外部的css文件,而JavaScript代码的执行,受CSSOM树构建的阻塞,所以就导致了,在遇到JavaScript的时候,DOM解析停下了,而要解析JavaScript的时候,又因有外部css文件的下载,CSSOM树没构建好,而导致JavaScript解析被阻止了,所以导致了DOM树构建被阻塞了,这也就是,CSS阻塞DOM的情况了
同时引用css文件和js文件
最后我们来看看同时引用css文件和js文件的流程,流程图如下

在接收到HTML数据之后的预解析过程中,HTML预解析器识别出来了有CSS文件和JavaScript文件需要下载,然后就同时发起这两个文件的下载请求,需要注意的是,这两个文件的下载过程是重叠的,所以下载时间按照最久的那个文件来算。
但实际上,不管css文件和js文件哪个先下载好,只有css文件下载好了,构建CSSOM树完成了,才能开始解析JavaScript
对渲染过程的优化
这整个过程的优化,涉及到了三个阶段
- 在我们输入了url之后,网络层面的优化,可以看看我的另一篇文章输入url到获取响应过程详解
- 关于白屏时间的缩短,我们平时在网速比较慢的时候,可能会长时间出现白屏,这是浏览器在解析相关的文件,我们可以对其做一些相应的优化
- 渲染完成之后,会进入完整页面的生成绘制,我们也可以对这方面做一些优化
这篇文章讲的,大部分都是第二阶段,在这个阶段,影响渲染时长的,其实也就是css文件,js文件的下载时间以及执行JavaScript消耗的时间
所以我们可以进行下面这些简答的优化
- 将一些css代码,js代码写在html文件内联标签里,减少下载时间
- 尽量减小文件大小,缩减代码量有时不太实际,业务就需要那么多代码,但可以通过webpack,将代码压缩成一行,实现文件大小的缩减
- 可以将一些不需要在HTML解析阶段用到的JavaScript外部文件引入的script标签加上async或者defer,使得能异步加载,不阻塞页面构建


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









