






一、递归的基本概念
递归
递归是一种强大的编程技术,它允许函数在其定义中直接或间接调用自身。在 Python 中,递归函数通过将复杂问题分解为更小的相同问题,并不断调用自身来解决这些子问题,直到达到一个特定的基本情况,从而得到最终的结果。
例如,计算阶乘的递归函数可以定义为:
def factorial(n): if n == 0: return 1 else: return n * factorial(n - 1)在这个例子中,factorial函数在n不为 0 时,会调用自身并将问题规模缩小,直到n为 0 时,满足基本情况,返回 1,从而逐步计算出阶乘的值。
递归的核心原理在于将一个复杂的问题逐步分解为更简单的子问题,通过不断重复这个过程,最终解决原始问题。但需要注意的是,在使用递归时,必须要确保有合适的基本情况来终止递归调用,否则可能会导致无限递归的错误。
二、递归的关键要素
(一)明确的结束条件
结束条件在递归中起着至关重要的作用,它是防止无限递归的关键。如果没有明确且合理的结束条件,递归函数将无休止地自我调用,最终导致程序崩溃。例如,在计算阶乘的递归函数factorial中,当n == 0时返回 1 就是明确的结束条件。如果没有这个条件,函数会一直调用自身,造成无限递归。因此,在设计递归函数时,必须仔细考虑并清晰定义结束条件,以确保递归能够在适当的时候停止。
(二)问题规模的缩小
在递归过程中,将复杂问题逐步简化为更小的同类问题是实现递归求解的核心步骤。以计算斐波那契数列为例,fibonacci函数通过将计算第n项的问题转化为计算第n - 1项和第n - 2项的问题,实现了问题规模的缩小。每次递归调用都使得问题规模变小,逐步向基本情况靠近。这种逐步缩小问题规模的方式,使得原本复杂的问题能够通过不断重复简单的步骤得以解决。例如,在计算fibonacci(5)时,会先将其转化为fibonacci(4)和fibonacci(3)的计算,然后进一步缩小规模,直到达到基本情况fibonacci(0)和fibonacci(1),从而得出最终结果。
三、递归的经典案例
(一)递归求阶乘
def factorial(n): if n == 0 or n == 1: return 1 else: return n * factorial(n - 1)递归求阶乘的原理是:对于一个正整数n,它的阶乘n!等于n乘以(n - 1)!。当n为 0 或 1 时,阶乘定义为 1 ,这就是递归的结束条件。在递归过程中,不断将问题规模缩小,即计算(n - 1)的阶乘,直到达到结束条件,从而逐步计算出n的阶乘。
(二)递归推斐波那契数列
def fibonacci(n): if n <= 1: return n else: return fibonacci(n - 1) + fibonacci(n - 2)斐波那契数列的特点是每个数都是前两个数的和。在递归函数中,当n小于等于 1 时,直接返回n,这是结束条件。对于大于 1 的n,通过递归调用计算前两个数的和,不断缩小问题规模,最终得到第n个数的值。
(三)二分法找有序列表指定值
def binary_search(arr, target, low, high): if low > high: return -1 mid = (low + high) // 2 if arr[mid] == target: return mid elif arr[mid] < target: return binary_search(arr, target, mid + 1, high) else: return binary_search(arr, target, low, mid - 1)二分法查找的原理是每次将搜索范围缩小一半。如果中间元素等于目标值,直接返回其索引。如果中间元素小于目标值,在右半部分继续查找;如果中间元素大于目标值,在左半部分继续查找。当搜索范围的下限大于上限时,表示未找到目标值,返回 -1 。通过不断递归调用,逐步缩小搜索范围,直到找到目标值或确定不存在。
四、递归的特点
(一)代码简洁性
递归能够以一种直观且简洁的方式表达某些问题的解决方案。以树的遍历为例,通过递归可以清晰地实现前序、中序和后序遍历,代码逻辑清晰,易于理解。相比使用循环和复杂的条件判断来实现相同的功能,递归代码通常更简洁,减少了代码的复杂性和冗余度。
例如,计算一个数的阶乘,使用递归函数factorial:
def factorial(n): if n == 0 or n == 1: return 1 else: return n * factorial(n - 1)这种简洁性使得代码更易于阅读和维护。
(二)效率与内存问题
递归在某些情况下可能会导致效率低下和内存消耗过大的问题。每次递归调用都会在内存中创建一个新的栈帧来存储函数的局部变量和状态信息。当递归深度较大时,会消耗大量的内存空间,甚至可能导致栈溢出错误。
例如,计算斐波那契数列,如果使用递归方式:
def fibonacci(n):if n <= 1:return nelse:return fibonacci(n - 1) + fibonacci(n - 2)
对于较大的n值,递归计算会进行大量的重复计算,导致效率低下。而且,随着递归深度的增加,内存消耗也会急剧上升。
因此,在实际应用中,需要谨慎使用递归,对于可能存在效率和内存问题的情况,考虑使用迭代等更高效的方式。
五、递归的应用场景
(一)文件目录遍历
在 Python 中,通过递归可以方便地遍历文件目录结构。例如,以下是一个简单的递归函数用于遍历目录:
import osdef traverse_directory(directory):for item in os.listdir(directory):item_path = os.path.join(directory, item)if os.path.isdir(item_path):traverse_directory(item_path)else:print(item_path)
在这个函数中,对于每个目录项,如果是子目录则继续递归调用自身进行遍历;如果是文件则直接打印其路径。
(二)快速排序等算法
快速排序是一种常用的排序算法,其核心思想就是利用递归。以下是一个 Python 实现的快速排序示例:
def quick_sort(arr, low, high):if low < high:pivot_index = partition(arr, low, high)quick_sort(arr, low, pivot_index - 1)quick_sort(arr, pivot_index + 1, high)def partition(arr, low, high):pivot = arr[high]i = low - 1for j in range(low, high):if arr[j] <= pivot:i += 1arr[i], arr[j] = arr[j], arr[i]arr[i + 1], arr[high] = arr[high], arr[i + 1]return i + 1
在快速排序中,通过选择一个基准元素,将数组分为两部分,然后对这两部分分别进行递归排序,最终实现整个数组的有序排列。递归在快速排序中起到了关键作用,使得算法能够高效地处理大规模数据。
六、递归的深度剖析
(一)递归的执行过程
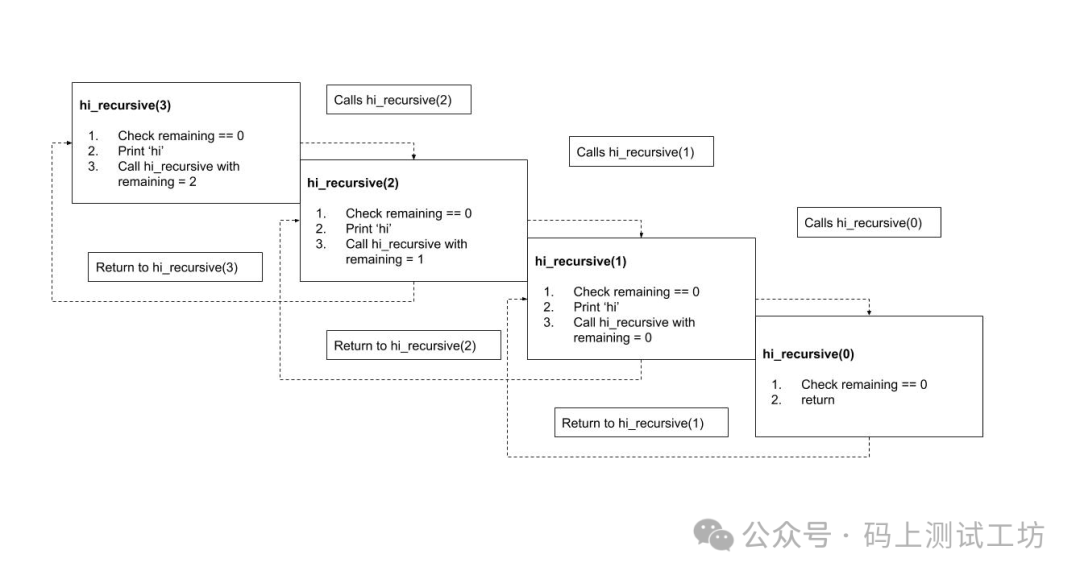
递归函数的执行过程可以分为 “递去” 和 “归回” 两个阶段。以一个简单的递归函数为例,如计算阶乘的函数:
def factorial(n):if n == 0:return 1else:return n * factorial(n - 1)
当我们调用 factorial(5) 时,首先进入 “递去” 阶段。函数会不断地调用自身,将问题规模逐渐缩小,即 factorial(5) 调用 factorial(4),factorial(4) 调用 factorial(3),以此类推,直到 n 等于 0 ,此时满足结束条件,开始进入 “归回” 阶段。
在 “归回” 阶段,从最内层的 factorial(0) 开始,逐步返回计算结果。由于每个递归调用都保存了当时的上下文环境,所以能够正确地将计算结果传递回来,最终得到 factorial(5) 的结果。
整个过程中,每一次递归调用都会创建一个新的函数栈帧来存储当前的参数和局部变量,直到递归结束,这些栈帧才会依次被释放。
(二)数据共享与独立性
在递归中,各层之间的数据通常是独立的。这意味着每一层的变量和数据在其自身的执行环境中是独立存在的,不会与其他层直接共享。
然而,通过参数传递或者使用全局变量等方式,可以在不同的递归层之间实现数据的共享。例如,如果将一个列表作为参数传递给递归函数,在函数内部对该列表进行修改,那么这种修改在所有递归层中都是可见的。
但需要注意的是,如果没有特殊的处理,各层的局部变量和普通数据是相互独立的,每一层的计算都基于其自身的参数和局部数据,不会受到其他层的影响。这种独立性保证了递归函数在处理复杂问题时的准确性和可靠性。
七、递归的优化策略
(一)避免重复计算
在递归过程中,很容易出现重复计算相同子问题的情况,这会极大地降低程序的效率。为了避免这种情况,可以采用缓存(记忆化)的方式。
例如,在计算斐波那契数列时,对于已经计算过的斐波那契数,将其存储在一个字典或数组中。当再次需要计算相同的数时,直接从缓存中获取,而不是重新进行递归计算。
以下是使用缓存优化斐波那契数列计算的 Python 代码示例:
def fibonacci(n, cache={}):if n in cache:return cache[n]if n <= 1:cache[n] = nreturn nelse:result = fibonacci(n - 1, cache) + fibonacci(n - 2, cache)cache[n] = resultreturn result
通过这种方式,可以显著减少重复计算,提高递归函数的执行效率。
(二)转换为非递归实现
在某些情况下,将递归函数转换为非递归形式(如使用循环)可以提高性能和避免栈溢出等问题。
以阶乘的计算为例,原本的递归函数如下:
def factorial_recursive(n):if n == 0 or n == 1:return 1else:return n * factorial_recursive(n - 1)
可以将其转换为非递归的循环形式:
def factorial_iterative(n): result = 1 for i in range(1, n + 1): result *= i return result对于一些复杂的递归问题,可以通过模拟系统栈来实现非递归。例如,对于汉诺塔问题,可以使用一个栈来保存子问题的参数和状态,通过循环来模拟递归的执行过程。
在将递归转换为非递归时,需要仔细分析递归的逻辑和状态变化,合理设计循环和数据结构来实现相同的功能。















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









