






1.JDK和JRE 有什么区别?
jdk 是提供给开发人员的编译工具,里面包含:
jvm(java virtual machine java虚拟机//就是可识别java命令代码,把他转成操作系统可识别的操作命令,然后在转成机器码,最后由CPU控制硬件完成指令)
jre(java runtime enviornment java运行时环境 //就是编译好的可执行的class文件)。
jdk就是定义了基本编译语法和丰富的类库,然后我们可以通过定义好的语法书写自定义的命令,也可引用他人编写好的命令来协同完成自身所需要的业务,因为现今的编码方式多种多样,有时候我们可以看到书写一个业务可能会到到成千上万行,然而每个人的编码方式和习惯都不一样,可能隔个一两星期可能自己都不知道自己写的什么鬼玩意,从而导致代码的可用性和可维护性差,大大增加维护成本,然后了架构大佬就引进了框架这个概念,‘我们不重复的造轮子,统一使用重复的轮子’,就是别写好的一些底层的代码,我们在写的时候就不需要再写一些机械化的操作,只需要注重自己的业务逻辑代码的编写就可了,这极大的加快了我们的开发效率,要知道以前咱们程序员写一个小业务也需要花大部分时间在做那些机械似的重复操作,久而久之,那是一件很痛苦的事情。
2.== 和 equals的区别是什么?
==:如果是值类型,比较的是内存中两个值是否相等,相等返回true,不相等返回false。
如果是应用类型,比较hashCode是否相等
equals:用于对象之间的比较,判断他们是不是同一个对象,他会首先比较他们的储存地址是否相同,也就是他们的hashCode是否相等,如果不相等那么会直接判定这两个对象或者属性不是同一个对象或者属性,从而返回false,如果相同,在比较他们的他们各自内存中的值是否也相等如果相等,返回true。
3.两个对象的hashCode()相同,则 equals()也一定为true,对吗?
:不对
首先会比较他们的hashCode()是否相等,不相等就不比较了,如果相同在比较equals()是否相等,如相等,就相等。
所以hashCode()相同,equals()不一定也相同。
4.final 在java中有什么作用?
:final是java中的关键字,可以用来修饰类,方法,属性。
修饰类代表这个类是不可以继承的。
修饰方法代表这个方法是不可重写的。
修饰属性代表这个属性是不可改变的常亮。
(补充:final不能用到接口和抽象类上的,因为接口和抽象类本来就是用来继承或实现的,如果不能继承实现,那将毫无意义)
5.java中的Math.round(-1.5)等于多少?
:首先在java中Math类正是java提供的类库中一个类,里面提供很多的静态方法,提供给开发人员编码工具类,而round单词意思为圆形的,round()方法即为四舍五入,如Math.round(1.5)等于2,然而Math.round(-1.5)却等于-1。为什么了?首先我们这么想大家都知道四舍五入经常把0.5看做是1,都知道是个平等值,不打不小,然而数学上咱们把他判定为大的哪一方,所以1.5等于2,然而如果取反,加上负号,等同大的哪一方变成小的,小的哪一方变成大的,所以-0.5应该属于小的一方,所以-0.5四舍五入之后理应等于0。
6.String 属于基础数据类型吗?
:不属于
在java中,基本数据类型有:
基本数据类型
整数类型:byte、short、int、long
浮点类型:float、double
字符类型:char
布尔类型:boolen
引用类型
类:class
接口:interface
数组
String属于类(class),属于引用类型
基本数据类型的包装类:Byte、Short、Integer、Long
Float、Double
Character
Boolen
7.java中操作字符串都有哪些类?他们之间有什么区别?
String:字符串常量,即申明就不可改变,底层封装的是char[]数组,
当String=“str”他会直接赋值放在常量池里面,
当String str=new String(“str”)他会把这个对象储存在堆或栈里面。
字符串常量存在一个常量池,用来储存常用的字符串,当我们直接赋值的时候他会检索常量池里面存不存在该字符串,而通过new的方式的化,会直接跳过常量池的检测,在
堆或栈里面申明存储空间。
StringBuffer:字符串变量,就是可变长度的字符串,线程安全的,适用于多线程,底层是可变长度的char[]数组,每次达到容量上线的时候,会自动创建一个容量加倍的新数组去储存他,称之为扩容。字符串变量,就是可变长度的字符串
StringBuilder:字符串变量,就是可变长度的字符串,线程不安全的,使用多线程,底层是可变长度的char[]数组,每次达到容量上线的时候,会自动创建一个容量加倍的新数组去储存他,称之为扩容。字符串变量,就是可变长度的字符串
总结:StringBuffer和StringBuilder都是继承抽象类AbstractStringBuilder,区别在于StringBuffer里面读取里面加有synchronize关键字,所以他是线程安全的,但是性能相比较而言性能差。
8.String str="i"与String str=new Str
ing(“i”)一样吗?
:不一样
前者是存储在字符串常量池里面,可减少常量的创建消耗的内存,减少GC处理。
后者是跳开常量池的检索,在堆或栈内存中申明一个储存。
9.如何将字符串反转?
获得字符串长度,然后通过循环截取单个字符,反向拼接。
10.String类的常用方法都有哪些?
indexof():查看索引
charAt():获取指定的字节或字符
split():切割字符串
replace():替换
compareto():比较
equals():判断值是否相等
length():字符串长度
subString:截取字符串
11.抽象类必须要有抽象方法吗?
:不必要
但是有抽象方法的类一定是抽象类。
12.普通类和抽象类有什么区别?
1)抽象类不能被实例化。
2)抽象类的访问权限仅限于Public和Protected,因为抽象类的方法是需要子类去实现的,如果是private,则无法被子类继承,子类无法实现该方法。
3)如果一个类继承于抽象类,则该类比需实现抽象类的方法,除非自身也是抽象类。
13.抽象类能使用final修饰吗?
:不能
抽象类语义值抽象的类,只能被继承,不能被实现,如果加上final关键字,将不能被继承,则该抽象类毫无意义。
14.接口和抽象类有什么区别?
抽象类:抽象类要被子类继承,抽象类里面的变量是普通的变量,方法可作为方法声明,也可做方法实现,抽象类是重构的结果。
接口:接口要被类实现,接口里面变量只能是静态常量,方法只能作为声明,接口是实现的结果。
区别:抽象类和接口都是用来抽象具体对象的,但是接口的抽象级别最高,抽象类可以有具体的方法和属性,接口只能有抽象方法和不可变变量,抽象类主要用来抽象类别,接口主要用来抽象功能。
15.java中IO流分为几种?
io按照流向分:
输入流(input)
输出流(output)
io按照类别分:
字节流(inputStream/outputSteam)
任何文件都可以通过字符流进行传输。
字符流(Reader/Writer)
非纯文本文件,不能用字符流,会导致文件格式破坏,不能正常执行。
节点流(低级流:直接跟输入输出源对接)
FileInputStream/FileOutputStream/FileReader/FileWriter/PrintStream/PrintWriter
处理流(高级流:建立在低级流的基础上)
转换流:
inputStreamReader/OutputStreamWriter,字节流转字符流/字符流转字节流
缓冲流:
BufferedInputStream/BufferedOutputStream
字节输入/输出缓冲流
BufferedReader/BufferedWriter
字符输入/输出缓冲流
16.BIO、NIO、AIO有什么区别?
服务器会创建多个线程等待客户端的请求,
BIO:指的是一条线程只为一条请求执行IO服务,只有执行完该请求才可以给其他请求服务,同步阻塞。
NIO:指的是多条请求由一条线程提供服务,当一个请求阻塞会执行其他请求,同步非阻塞。
AIO:IO服务的方式是通过类似挂号的方式,采用异步服务,假如很多的请求同时发送到服务器,然而并没有那么多的线程可以同时为他们服务,只有等其他请求执行完或者阻塞超时,线程空闲,会通知程序,这时候才能允许为其他请求服务,同时,客户端会一遍遍请求服务,当线程空下来,正好有请求发送到服务器,这时就可以提供服务了。异步非阻塞
17.Files常用的方法有哪些?
copy:复制文件或目录
createFile:穿件文件
createDirector:创建目录
delete:删除
move:移动或重命名
exits:是否存在
newInputStream:打开一个文件,内容写进InputSream里面
outputStream:打开或创建一个问件,内容写进outputSteam里面
read:读取
writer:写入
18.java容器都有哪些?
java.util.collection
List:ArrayList、LinkList、Vector
Set:HashSet、LinkSet、TreeSet
Queue:ArraryDeq…
java.util.Map
Map:hashMap、hashTable、linkHashMap、TreeMap
19.Collection和Collections有什么区别?
Collection:集合的父接口,提供一些集合的基本操作方法,子接口有List,Set,Queue。
Collections:集合Collection的包装类,专门为List,Set,Map提供服务。它包含有各种有关集合操作的静态多态方法。此类不能实例化,就像一个工具类,用于对集合中元素进行排序、搜索以及线程安全等各种操作,服务于java的Collection框架。
20.List、Set、Map之间的区别是什么?
List:父接口是collection,List集合里面的元素是可重复有序的。
Set:父接口是collection,Set集合里面的元素是不可重复无序的。
Map:Map是一个键值对类似于目录的特殊集合,是由两个集合组成,其中键(key)是一个Set集合,而值(value)是一个List集合。
21.HashMap和Hashtable有什么区别?
HashMap:父接口是Map,是线程不安全的,相比较而言,性能好,适用于单线程。
Hashtable:父接口是Map,是线程安全的,相比较而言,性能不好,适用于多线程线程,现在一般不用。
22.如何决定是使用HashMap还是TreeMap?
TreeMap内部的键(key)是无序的,但是他会基于二叉树进行比较大小,而每当我们根据键(key)获得值的时候,可以快速找到键(key),从而提高查询速度。但同时当需要插入的时候,每次插入都需要比较,从而会对性能有一点影响。
总结:但我们大量的查询Map的时候,可以考虑使用TreeMap,而当我们需要较多增删改时建议使用LinkHashMap,一般的时候使用HashMap。
23.说一下HashMap的实现原理?
HashMap底层是有两个集合组成,键(key)是一个set,值(value)是一个ArrayList。
24.说一下HashSet的实现原理?
HashSet底层是一HashMap,每次往HashSet中存放数据的时候,都存放在底层的HashMap里面,把HashSet的值作为HashMap的键(key),而值(value)是PRESENT虚拟值,是一个object对象。
25.ArrayList和LinkedList区别是什么?
ArrayList:有序不重复的集合,每次增加或者删除,所有元素都需要重排序,从而影响性能。但是查询遍历快。
LinkedList:储存方式是链表式的,每个元素只知道他的上一个元素和下一个元素,当增删的时候,只需要把这个元素的相连系的两个元素修改他们的关系就行了,相对而言性能好,但是查询遍历的时候,他都需要链式的一个个找,性能低下。
总结:ArrayList查询块,增删慢,LinkedList增删快,查询慢。实际使用,根据自己场景使用。
26.如何实现数组和List之间的转换?
数据转List:调用数组的包装类Array的asList方法。底层是通过循环遍历数组里面的每一个元素取出来放到集合中。
List转数组:调用List集合的toArray方法。以正确的顺序(从第一个到最后一个元素)返回一个包含此列表中所有元素的数组。
27.ArrayList和Vector有何区别?
ArrayList:是线程不安全的,适用于单线程。
Vector:是线程安全的,适用于多线程,一般不用(已淘汰)。
28.Array和ArrayList有何区别?
Array:Array类提供静态方法来动态创建和访问Java数组。Array允许在获取或设置操作期间扩大转换,但如果发生缩小转换,则抛出IllegalArgumentException 。
ArrayList:可调整大小的数组的实现List接口。 实现所有可选列表操作,并允许所有元素,包括null 。 除了实现List 接口之外,该类还提供了一些方法来操纵内部使用的存储列表的数组的大小。 (这个类是大致相当于Vector,不同之处在于它是不同步的)。 每个ArrayList实例都有一个容量 。 容量是用于存储列表中的元素的数组的大小。 它总是至少与列表大小一样大。 当元素添加到ArrayList时,其容量会自动增长。 没有规定增长政策的细节,除了添加元素具有不变的摊销时间成本。
29.在Queue中poll()和remove()有什么区别?
remove()和poll()方法删除并返回队列的头。 从队列中删除哪个元素是队列排序策略的一个功能,它与实现不同。 remove()和poll()方法在队列为空时的行为不同: remove()方法抛出异常,而poll()方法返回null 。
30.哪些集合类是线程安全的?
Hashtable:线程安全的不建议使用
Vector:效率较低,现在不建议使用
statck:堆栈类,先进后出
ConcurrentHashMap底层使用二叉树,分区锁
enumeration:枚举,相当于迭代器
31.迭代器Iterator是什么?
迭代器(Iterator)模式,又叫做游标(Cursor)模式。GOF给出的定义是:提供一种方法访问一个容器(container)对象中的各个元素,而又不需要暴露该对象的内部细节。
32.Iterator怎么使用?有什么特点?
容器对象调用Iterator方法返回一个迭代器对象,通过While循环调用Iterator的hasNext()和next()进行遍历。
特点:专门为容器提供一种遍历方法,访问一个容器(container)对象中的各个元素,而又不需要暴露该对象的内部细节。
33.Iterator和ListIterator有什么区别?
Iterator:提供一种方法访问一个容器(container)对象中的各个元素,而又不需要暴露该对象的内部细节。
ListIterator:用于允许程序员沿任一方向遍历列表的列表的迭代器,在迭代期间修改列表,并获取列表中迭代器的当前位置。
34.怎么确保一个集合不能被修改?
调用集合包装类Collections的unmondifiableCollection()方法来创建一个只读集合。
多线程
35.并行和并发有什么区别?
并行:是同一时刻,两个线程都在执行。
并发:是同一时刻,只有一个执行,但是同一时间段内,两个线程都执行了。
36.线程和进程的区别?
1)进程和线程都是有操作系统所体会的程序运行的基本单元,系统利用该基本单元实现系统对应用的并发性。
2)一个进程对应一个主线程,由主线程可创建多个子线程,线程和进程的区别在于线程不能够单独执行,他必须运行处活动状态的应用程序进程中。
37.守护线程是什么?
java线程分为用户线程和守护线程。
守护线程是程序运行的时候在后台提供的一种通用服务的线程。所有用户线程停止,进程会停掉所有守护线程,退出程序。
java中把线程设置为守护线程的方法:在start线程之前调用线程的setDaemon(true)方法。
守护线程创建的线程也是守护线程。
38.创建线程有哪几种方式?
NO.1继承Thread类
NO.2实现runnable接口
NO.3自定义线程类使其实现Callable接口,在main方法中创建一个FutureTask对象,在创建一个Thread类,将FutureTask的对象作为参数传递给Thread构造方法
39.说一下runnable和callable有什么区别?
callable:返回结果并可能引发异常的任务。 实现者定义一个没有参数的单一方法,称为call 。
Callable接口类似于Runnable ,因为它们都是为其实例可能由另一个线程执行的类设计的。 然而,A Runnable不返回结果,也不能抛出被检查的异常。
call()方法计算一个结果,如果不能这样做,就会抛出一个异常。
40.线程有哪些状态?
创建:创建还没有调用start();
就绪:当线程处于可运行状态,但调度线程还没有把他选定运行时的状态,或者从阻塞、休眠、等待重新回到可就绪状态。
运行:线程调度程序从可运行池中选择一个线程作为当前线程所处的状态,这也是线程进入运行状态的唯一方式。
阻塞:这条线程是有资格运行时的状态,特点,该线程任是活的,但是他们有可运行的条件,当达到条件触发是,该线程又变成可运行的。
死亡: 线程执行完run方法时,就认为他是死的,但是该对相是活的,线程一死就不可一在度调用start()运行,否则会报错。
41.sleep()和wait()有什么区别?
sleep:让运行状态的线程一段时间之内处于阻塞状态,然后休眠结束,在进入运行状态。
wait:让运行状态的线程由阻塞然后到就绪状态,等其他线程通知,才能再次进入运行状态。
42.notify()和notifyAll()有什么区别?
notify :当一条线程调用了wait()等待方法,我们就可以在其他线程调用notify通知等待的一条线程可以运行了。
notify:通过调用线程的notifyAll()就可以是所有等待的线程时间到了,可运行了,使其他所有等待的线程变成运行状态。
43.线程的run()和start()有什么区别?
run:run虽然是线程执行的方法,但是当他调用run()时,只会是当成这个线程的普通方法,不会启动线程。
start:调用start方法相当于启动一条新线程。
44.创建线程池有哪几种方式?
Java通过Executors提供四种线程池,分别为:
newCachedThreadPool创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。
newFixedThreadPool 创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。
newScheduledThreadPool 创建一个定长线程池,支持定时及周期性任务执行。
newSingleThreadExecutor 创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行。
45.线程池都有哪些状态?
下面的几个static final变量表示runState可能的几个取值。
当创建线程池后,初始时,线程池处于RUNNING状态;
如果调用了shutdown()方法,则线程池处于SHUTDOWN状态,此时线程池不能够接受新的任务,它会等待所有任务执行完毕;
如果调用了shutdownNow()方法,则线程池处于STOP状态,此时线程池不能接受新的任务,并且会去尝试终止正在执行的任务;
当线程池处于SHUTDOWN或STOP状态,并且所有工作线程已经销毁,任务缓存队列已经清空或执行结束后,线程池被设置为TERMINATED状态。
46.线程池中submit()和execute()方法有什么区别?
1、接收的参数不一样
2、submit有返回值,而execute没有
Method submit extends base method Executor.execute by creating and returning a Future that can be used to cancel execution and/or wait for completion.
3、submit方便Exception处理
There is a difference when looking at exception handling. If your tasks throws an exception and if it was submitted with execute this exception will go to the uncaught exception handler (when you don’t have provided one explicitly, the default one will just print the stack trace to System.err). If you submitted the task with submit any thrown exception, checked or not, is then part of the task’s return status. For a task that was submitted with submit and that terminates with an exception, the Future.get will rethrow this exception, wrapped in an ExecutionException.
47.在java程序中怎么保证多线程的运行安全?
1.当多个线程要共享一个实例对象的值得时候,那么在考虑安全的多线程并发编程时就要保证下面3个要素:
原子性(Synchronized, Lock)
有序性(Volatile,Synchronized, Lock)
可见性(Volatile,Synchronized,Lock)
2.如何做到类的线程安全呢?
1)让类无状态
类中没有成员变量(既没有静态变量,又没有实例变量)
2)让变量线程私有化
栈是线程私有的,所以方法中定义的局部变量便是线程私有的
3)ThreadLocal让变量在每个线程中都保存一份副本,副本便是线程私有的
4)栈封闭
ThreadLocal
变量用private修饰,不提供get、set方法
5)get方法提供的是一份副本
比如说现在有个get方法,要求返回List,那么在方法中可以new一个新的List,将String对象添加进去
6)保证操作是原子操作(加锁)
synchronized关键字
CAS(单点登录)
Lock
volatile可以保证可见性和有序性,适合一写多读的场景
48.多线程锁的升级原理是什么?
读后解读Synchronized下的三种锁
偏向锁
轻量锁
重量锁
共享场景骑单车007号车(转载)
获取偏向锁
1、 张飞要骑
有人吗
没人
写上张飞的名字
成功获取偏向锁
骑走
成功偏向锁
1.1、张飞要骑车
有我的名字
骑走
争抢进入轻量级锁
2、 刘备要骑
看到张飞的名字在,问张飞在吗
在
尝试写上刘备的名字失败
张飞我在等你
刘备骑完后把他的名字抹去进入轻量级锁
2.1、 尝试写上刘备名字成功
获取偏向锁
骑走
争抢轻量级锁
3、 诸葛亮要骑
拍照单车挂身上
尝试单车上连到照片上
成功
成功获取轻量级锁
骑走
还车成功
已经争抢成了重量级锁
3.1、 还车失败,好了好了你们快抢(关羽)
争抢轻量级锁
4、关羽要骑车
拍照单车
尝试单车上连到照片上
失败
再试多次(自旋锁)
艹有完没完了,设置重量级锁
蹲等
49.什么是死锁?
在计算机系统中有很多一次只能由一个进程使用的资源,如打印机,磁带机,一个文件的I节点等。在多道程序设计环境中,若干进程往往要共享这类资源,而且一个进程所需要的资源不止一个。这样,就会出现若干进程竞争有限资源,又推进顺序不当,从而构成无限期循环等待的局面。这种状态就是死锁。系统发生死锁现象不仅浪费大量的系统资源,甚至导致整个系统崩溃,带来灾难性后果。所以,对于死锁问题在理论上和技术上都必须给予高度重视。
50.怎么防止死锁?
〈1〉打破互斥条件。即允许进程同时访问某些资源。但是,有的资源是不允许被同时访问的,像打印机等等,这是由资源本身的属性所决定的。所以,这种办法并无实用价值。
〈2〉打破不可抢占条件。即允许进程强行从占有者那里夺取某些资源。就是说,当一个进程已占有了某些资源,它又申请新的资源,但不能立即被满足时,它必须释放所占有的全部资源,以后再重新申请。它所释放的资源可以分配给其它进程。这就相当于该进程占有的资源被隐蔽地强占了。这种预防死锁的方法实现起来困难,会降低系统性能。
预防策略:
1.安全序列(执行有序的操作)
2.银行家算法(有序合理的分配资源)
51.ThreadLocal是什么?有哪些使用场景?
ThreadLocal,很多地方叫做线程本地变量,也有些地方叫做线程本地存储,其实意思差不多。可能很多朋友都知道ThreadLocal为变量在每个线程中都创建了一个副本,那么每个线程可以访问自己内部的副本变量。
最常见的ThreadLocal使用场景为 用来解决数据库连接、Session管理等。
52.说一下synchronized底层实现原理?
synchronized可以保证方法或者代码块在运行时,同一时刻只有一个方法可以进入到临界区,同时它还可以保证共享变量的内存可见性
同步代码块:monitorenter指令插入到同步代码块的开始位置,monitorexit指令插入到同步代码块的结束位置,JVM需要保证每一个monitorenter都有一个monitorexit与之相对应。任何对象都有一个monitor与之相关联,当且一个monitor被持有之后,他将处于锁定状态。线程执行到monitorenter指令时,将会尝试获取对象所对应的monitor所有权,即尝试获取对象的锁;
同步方法:synchronized方法则会被翻译成普通的方法调用和返回指令如:invokevirtual、areturn指令,在VM字节码层面并没有任何特别的指令来实现被synchronized修饰的方法,而是在Class文件的方法表中将该方法的access_flags字段中的synchronized标志位置1,表示该方法是同步方法并使用调用该方法的对象或该方法所属的Class在JVM的内部对象表示Klass做为锁对象。(摘自:http://www.cnblogs.com/javaminer/p/3889023.html)
53.synchronized和volatile的区别是什么?
volatile本质是在告诉jvm当前变量在寄存器(工作内存)中的值是不确定的,需要从主存中读取; synchronized则是锁定当前变量,只有当前线程可以访问该变量,其他线程被阻塞住。
volatile仅能使用在变量级别;synchronized则可以使用在变量、方法、和类级别的
volatile仅能实现变量的修改可见性,不能保证原子性;而synchronized则可以保证变量的修改可见性和原子性
volatile不会造成线程的阻塞;synchronized可能会造成线程的阻塞。
volatile标记的变量不会被编译器优化;synchronized标记的变量可以被编译器优化
54.Synchronized和Lock有什么区别?
Synchronized:
1)、存在层次 Java的关键字,在jvm层面上
2)、锁的释放 @1以获取锁的线程执行完同步代码,释放锁 @2线程执行发生异常,jvm会让线程释放锁
3)、锁的获取 假设A线程获得锁,B线程等待。如果A线程阻塞,B线程会一直等待
4)、锁状态 无法判断
5)、锁类型 可重入 不可中断 非公平
6)、性能 少量同步
Lock:
1)、存在层次 是一个类
2)、锁的释放 在finally中必须释放锁,不然容易造成线程死锁
3)、锁的获取 分情况而定,Lock有多个锁获取的方式,具体下面会说道,大致就是可以尝试获得锁,线程可以不用一直等待
4)、锁状态 可以判断
5)、锁类型 可重入 可判断 可公平(两者皆可)
6)、性能 大量同步
55.Synchronized和ReentrantLock区别是什么?
相似点:
这两种同步方式有很多相似之处,它们都是加锁方式同步,而且都是阻塞式的同步,也就是说当如果一个线程获得了对象锁,进入了同步块,其他访问该同步块的线程都必须阻塞在同步块外面等待,而进行线程阻塞和唤醒的代价是比较高的(操作系统需要在用户态与内核态之间来回切换,代价很高,不过可以通过对锁优化进行改善)。
区别:
这两种方式最大区别就是对于Synchronized来说,它是java语言的关键字,是原生语法层面的互斥,需要jvm实现。而ReentrantLock它是JDK 1.5之后提供的API层面的互斥锁,需要lock()和unlock()方法配合try/finally语句块来完成。
1.Synchronized
Synchronized进过编译,会在同步块的前后分别形成monitorenter和monitorexit这个两个字节码指令。在执行monitorenter指令时,首先要尝试获取对象锁。如果这个对象没被锁定,或者当前线程已经拥有了那个对象锁,把锁的计算器加1,相应的,在执行monitorexit指令时会将锁计算器就减1,当计算器为0时,锁就被释放了。如果获取对象锁失败,那当前线程就要阻塞,直到对象锁被另一个线程释放为止。
2.ReentrantLock
由于ReentrantLock是java.util.concurrent包下提供的一套互斥锁,相比Synchronized,ReentrantLock类提供了一些高级功能,主要有以下3项:
1.等待可中断,持有锁的线程长期不释放的时候,正在等待的线程可以选择放弃等待,这相当于Synchronized来说可以避免出现死锁的情况。
2.公平锁,多个线程等待同一个锁时,必须按照申请锁的时间顺序获得锁,Synchronized锁非公平锁,ReentrantLock默认的构造函数是创建的非公平锁,可以通过参数true设为公平锁,但公平锁表现的性能不是很好。
3.锁绑定多个条件,一个ReentrantLock对象可以同时绑定对个对象。
56.说一下Atomic的原理?
Atomic包是java.util.concurrent下的另一个专门为线程安全设计的Java包,包含多个原子操作类。这个包里面提供了一组原子变量类。其基本的特性就是在多线程环境下,当有多个线程同时执行这些类的实例包含的方法时,具有排他性,即当某个线程进入方法,执行其中的指令时,不会被其他线程打断,而别的线程就像自旋锁一样,一直等到该方法执行完成,才由JVM从等待队列中选择一个另一个线程进入,这只是一种逻辑上的理解。实际上是借助硬件的相关指令来实现的,不会阻塞线程(或者说只是在硬件级别上阻塞了)。可以对基本数据、数组中的基本数据、对类中的基本数据进行操作。原子变量类相当于一种泛化的volatile变量,能够支持原子的和有条件的读-改-写操作。—— 引自@chenzehe 的博客。
Compare and swap(CAS):
当前的处理器基本都支持CAS,只不过每个厂家所实现的算法并不一样罢了,每一个CAS操作过程都包含三个运算符:一个内存地址V,一个期望的值A和一个新值B,操作的时候如果这个地址上存放的值等于这个期望的值A,则将地址上的值赋为新值B,否则不做任何操作。CAS的基本思路就是,如果这个地址上的值和期望的值相等,则给其赋予新值,否则不做任何事儿,但是要返回原值是多少
反射
57.什么是反射?
JAVA反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法,这种动态获取、调用对象方法的功能称为java语言的反射机制。
反射获取对象的三种方式:
1)
//通过该类的静态属性class获得people
people p1=people.class;
2)
//通过该类的getClass()方法获得people
people p2=people.getClass();
3)
//此方法含义是:加载参数指定的类,并且初始化它。
people p3=Class.forName(“people路径”);
58.什么是java序列化?什么情况下需要序列化?
序列化就是一种用来处理对象流的机制,所谓对象流也就是将对象的内容进行流化。
可以对流化后的对象进行读写操作,也可将流化后的对象传输于网络之间。
序列化是为了解决在对对象流进行读写操作时所引发的问题。
序列化的实现:将需要被序列化的类实现Serializable接口,该接口没有需要实现的方法,
implements Serializable只是为了标注该对象是可被序列化的,然后使用一个输出流
(如:FileOutputStream)来构造一个ObjectOutputStream(对象流)对象,接着,
使用ObjectOutputStream对象的writeObject(Object obj)方法就可以将参数为obj的对象写出(即保存其状态),
要恢复的话则用输入流。
序列化:序列化是将对象转换为容易传输的格式的过程。
例如,可以序列化一个对象,然后使用 HTTP 通过 Internet 在客户端和服务器之间传输该对象。
在另一端,反序列化将从该流重新构造对象。
是对象永久化的一种机制。
确切的说应该是对象的序列化,一般程序在运行时,产生对象,
这些对象随着程序的停止运行而消失,但如果我们想把某些对象
(因为是对象,所以有各自不同的特性)保存下来,在程序终止运行后,这些对象仍然存在,
可以在程序再次运行时读取这些对象的值,或者在其他程序中利用这些保存下来的对象。这种情况下就要用到对象的序列化。
对象序列化的最主要的用处就是在传递,和保存对象(object)的时候,保证对象的完整性和可传递性。
譬如通过网络传输,或者把一个对象保存成一个文件的时候,要实现序列化接口 。
59.动态代理是什么,有哪些应用?
动态代理是实现对接口中全部的方法进行统一的拦截,不需要在每一处代理方法中添加拦截内容。
动态代理是AOP的一种实现。
AOP(AspectOrientedProgramming):将日志记录,性能统计,安全控制,事务处理,异常处理等代码从业务逻辑代码中划分出来,通过对这些行为的分离,我们希望可以将它们独立到非指导业务逻辑的方法中,进而改变这些行为的时候不影响业务逻辑的代码—解耦。
60.怎么实现动态代理?
在java的动态代理API中,有两个重要的类和接口,一个是 InvocationHandler(Interface)、另一个则是 Proxy(Class),这一个类和接口是实现我们动态代理所必须用到的。
通过实现 InvocationHandler 接口创建自己的调用处理器;
通过为Proxy类的newProxyInstance方法指定代理类的ClassLoader 对象和代理要实现的interface以及调用处理器InvocationHandler对象 来创建动态代理类的对象;
对象拷贝
61.为什么要使用克隆?
克隆的对象可能包含一些已经修改过的属性,而new出来的对象的属性都还是初始化时候的值,所以当需要一个新的对象来保存当前对象的“状态”就靠clone方法了。
所以我们需要能够实现对于输入的实参进行了一份拷贝,若方法参数为基本类型,则在栈内存中开辟新的空间,所有的方法体内部的操作都是针对这个拷贝的操作,并不会影响原来输入实参的值 。若方法参数为引用类型,该拷贝与输入实参指向了同一个对象,方法体内部对于对象的操作,都是针对的同一个对象。
62.如何实现对象克隆?
有两种方式:
1). 实现Cloneable接口并重写Object类中的clone()方法;
2). 实现Serializable接口,通过对象的序列化和反序列化实现克隆,可以实现真正的深度克隆;
63.深拷贝和浅拷贝区别是什么?
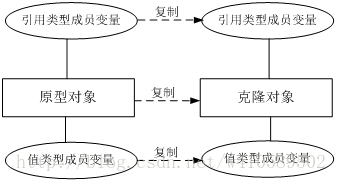
1)浅克隆
在浅克隆中,如果原型对象的成员变量是值类型,将复制一份给克隆对象;如果原型对象的成员变量是引用类型,则将引用对象的地址复制一份给克隆对象,也就是说原型对象和克隆对象的成员变量指向相同的内存地址。
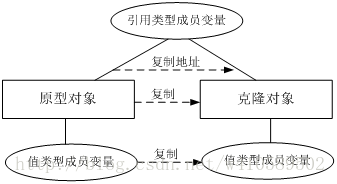
2)深克隆
在深克隆中,无论原型对象的成员变量是值类型还是引用类型,都将复制一份给克隆对象,深克隆将原型对象的所有引用对象也复制一份给克隆对象。
简单来说,在深克隆中,除了对象本身被复制外,对象所包含的所有成员变量也将复制。
java Web
64.jsp和servlet有什么区别?
相通点:servlet是java的 we工程,内部实现接受请求和进行请求响应的方式,servlet就相当于一台服务器,接受请求和提供服务,而jsp其实就是一个servlet,只是是多种servlet实现中的一种而已。
区别:servlet是在服务器端运行返回html等静态页面,而servlet时运行在web容器里面,比如tomcat,通过服务器返回数据到jsp界面,然后容器通过jvm把jsp界面编辑成.java和.class文件,然后执行生成html界面。
65.jsp有哪些内置对象作用是什么?
1)request内置对象
request内置对象是最常用的对象之一,它代表的是java.servlet.HttpServletRequest类的对象。request内置对象中包含了有关浏览器请求的信息,并提供了多个用于获取cookie、header以及session内数据的方法。
2)response内置对象
response对象与request对象相对应,它是用于响应客户请求,向客户端输出信息。response是javax.servlet.HttpServletResponse类的对象。
response对象的常用方法
response对象提供了多个方法用来处理HTTP响应,可以调用response中的方法修改ContentType中的MIME类型以及实现页面的跳转等等,
3)page内置对象
page对象有点类似于Java编程中的this指针,就是指当前JSP页面本身。page是java.lang.Object类的对象。
4)session内置对象
session是与请求有关的会话期,它是java.servlet.http.HttpSession类的对象,用来表示和存储当前页面的请求信息。
在实际的Web应用开发过程会经常遇到这样的一个问题:会话状态的维持。当然有很多种方法可以用来解决这个问题,例如:Cookies、隐藏的表单输入域或者将状态信息直接附加到URL当中去,但是这些方法使用非常不便。
Java Servlet提供了一个可以在多个请求之间持续有效的会话对象HttpSession,此对象允许用户存储和提取会话状态的信息。JSP同样也支持了Servlet中的这个概念。JSP中的session内置对象就是对应于Servlet中的HttpSession对象。当Web应用系统希望通过多个页面完成一个事务的时候,session的使用是非常有用和方便的。
5)application内置对象
application是javax.servlet.ServletContext类对象的一个实例,用于实现用户之间的数据共享(多使用于网络聊天系统)。
application对象与session对象的区别
它的作用有点类似于前一节介绍的session内置对象。但是它们之间还是有区别的,一般来说,一个用户对应着一个session,并且随着用户的离开session中的信息也会消失,所以不同客户之间的会话必须要确保某一时刻至少有一个客户没有终止会话;而application则不同,它会一直存在,类似于系统的“全局变量”,而且只有一个实例。
6)out内置对象
用来对数据的整理输出
7)exception内置对象
exception内置对象是用来处理页面出现的异常错误,它是java.lang.Throwable类的一个对象。前面已经讲过,在实际JSP网站开发过程中,通常是在其页面中加入page指令的errorPage属性来将其指向一个专门处理异常错误的页面。如果这个错误处理页面已经封装了这个页面收到的错误信息,并且错误处理页面页面含有的isErrorpage属性设置为true,则这个错误处理页面可以使用以下方法来访问错误的信息:
8)config内置对象
config内置对象是ServletConfig类的一个实例。在Servlet初始化的时候,JSP引擎通过config向它传递信息。这种信息可以是属性名/值匹配的参数,也可以是通过ServletContext对象传递的服务器的有关信息。
9)pageContext内置对象
pageContext对象是一个比较特殊的对象。它相当于页面中所有其他对象功能的最大集成者,即使用它可以访问到本页面中所有其他对象,例如前面已经描述的request、response以及application对象等。
66.说一下jsp的4种作用域?
1)page:只在当前页面有效。
2)request:当前页面和请求界面有效。
3)session:整个会话期间都是有效的。
4)application:全局有效,除非服务器停止。
67.Session和Cookie有什么区别?
session:保存数据在服务器,开启会话界面会有保存信息在服务器,数据安全,但有效时间一般,大约30分钟,一般用来保存用户登录信息。
cookie:保存数据在本地,可保存一些不重要的信息储存在本地,数据不安全,方便下次等路附带提示功能,有效期长。
68.说一下session的工作原理?
:当客户端请求服务器的时候,servlet会创建一个session对象,然后把数据存在session中,这样每次跳其他界面的时候,进入拦截器,验证session,如果能够从里面拿到数据,表示是已登录,不需要注册,如果没有,进行拦截,跳转到登录页面。
69.如果客户端禁止Cookie能实现Session还能用吗?
:每次请求服务器,会创建一个Session回话,并把Session id放在Cookie中,当在次访问的时候,他会判断本地有没有保存session id,如果没有,就会重新创建一个新session,如果有,就用这个session,所以可知,禁止Cookic,下次访问需要重行创建session,所以答案是不能用。
70.spring MVC和Struts的区别是什么?
1)、Struts2是类级别的拦截, 一个类对应一个request上下文,SpringMVC是方法级别的拦截,一个方法对应一个request上下文,而方法同时又跟一个url对应,所以说从架构本身上SpringMVC就容易实现restful url,而struts2的架构实现起来要费劲,因为Struts2中Action的一个方法可以对应一个url,而其类属性却被所有方法共享,这也就无法用注解或其他方式标识其所属方法了。
2)、由上边原因,SpringMVC的方法之间基本上独立的,独享request response数据,请求数据通过参数获取,处理结果通过ModelMap交回给框架,方法之间不共享变量,而Struts2搞的就比较乱,虽然方法之间也是独立的,但其所有Action变量是共享的,这不会影响程序运行,却给我们编码 读程序时带来麻烦,每次来了请求就创建一个Action,一个Action对象对应一个request上下文。
3)、由于Struts2需要针对每个request进行封装,把request,session等servlet生命周期的变量封装成一个一个Map,供给每个Action使用,并保证线程安全,所以在原则上,是比较耗费内存的。
4)、 拦截器实现机制上,Struts2有以自己的interceptor机制,SpringMVC用的是独立的AOP方式,这样导致Struts2的配置文件量还是比SpringMVC大。
5)、SpringMVC的入口是servlet,而Struts2是filter(这里要指出,filter和servlet是不同的。以前认为filter是servlet的一种特殊),这就导致了二者的机制不同,这里就牵涉到servlet和filter的区别了。
6)、SpringMVC集成了Ajax,使用非常方便,只需一个注解@ResponseBody就可以实现,然后直接返回响应文本即可,而Struts2拦截器集成了Ajax,在Action中处理时一般必须安装插件或者自己写代码集成进去,使用起来也相对不方便。
7)、SpringMVC验证支持JSR303,处理起来相对更加灵活方便,而Struts2验证比较繁琐,感觉太烦乱。
8)、Spring MVC和Spring是无缝的。从这个项目的管理和安全上也比Struts2高(当然Struts2也可以通过不同的目录结构和相关配置做到SpringMVC一样的效果,但是需要xml配置的地方不少)。
9)、 设计思想上,Struts2更加符合OOP的编程思想, SpringMVC就比较谨慎,在servlet上扩展。
10)、SpringMVC开发效率和性能高于Struts2。
11)、SpringMVC可以认为已经100%零配置。## 70.
71.如何避免SQL注入?
1)严格限制Web应用的数据库的操作权限,给此用户提供仅仅能够满足其工作的最低权限,从而最大限度的减少注入攻击对数据库的危害。
2)检查输入的数据是否具有所期望的数据格式,严格限制变量的类型,例如使用regexp包进行一些匹配处理,或者使用strconv包对字符串转化成其他基本类型的数据进行判断。
3)对进入数据库的特殊字符(’"\尖括号&*;等)进行转义处理,或编码转换
4)所有的查询语句建议使用数据库提供的参数化查询接口,参数化的语句使用参数而不是将用户输入变量嵌入到SQL语句中,即不要直接拼接SQL语句。例如使用database/sql里面的查询函数Prepare和Query,或者Exec(query string, args …interface{})。
5)在应用发布之前建议使用专业的SQL注入检测工具进行检测,以及时修补被发现的SQL注入漏洞。网上有很多这方面的开源工具,例如sqlmap、SQLninja等。
6)避免网站打印出SQL错误信息,比如类型错误、字段不匹配等,把代码里的SQL语句暴露出来,以防止攻击者利用这些错误信息进行SQL注入。
7)使用PreparedStatement来代替Statement来执行SQL语句
72.什么是XSS攻击,如何避免?
XSS攻击又称CSS,全称Cross Site Script (跨站脚本攻击),其原理是攻击者向有XSS漏洞的网站中输入恶意的 HTML 代码,当用户浏览该网站时,这段 HTML 代码会自动执行,从而达到攻击的目的。XSS 攻击类似于 SQL 注入攻击,SQL注入攻击中以SQL语句作为用户输入,从而达到查询/修改/删除数据的目的,而在xss攻击中,通过插入恶意脚本,实现对用户游览器的控制,获取用户的一些信息。 XSS是 Web 程序中常见的漏洞,XSS 属于被动式且用于客户端的攻击方式。
避免方法:
1.利用 php htmlentities()函数对传入参数的非法的 HTML 代码包括单双引号等进行转义。但是,中文情况下, htmlentities() 却会转化所有的 html 代码,连同里面的它无法识别的中文字符也给转化了。
2.利用 php htmlspecialchars()函数对传入参数的非法的 HTML 代码包括单双引号等进行转义,需要注意的是第二个参数默认是 ENT_COMPAT,函数默认只是转化双引号("),不对单引号(’)做转义。更多的时候要加上第二个参数,应该这样用 : htmlspecialchars($string,ENT_QUOTES)对单双引号都进行转义。如果需要不转化任何的引号第二个参数使用ENT_NOQUOTES。
3.通过正则表达式过滤传入参数的html标签来防范XSS攻击
73.什么是CSRF攻击,如何避免?
CSRF(Cross-site request forgery)

如何防御
防范 CSRF 可以遵循以下几种规则:
1)Get 请求不对数据进行修改
2)不让第三方网站访问到用户 Cookie
3)阻止第三方网站请求接口
4)请求时附带验证信息,比如验证码或者 token
防抓包
使用HTTPS(HTTPS 还是通过了 HTTP 来传输信息,但是信息通过 TLS 协议进行了加密。)替换HTTP,对传输的数据进行加密,这样,当请求的信息被抓包工具抓包后,也无法修改提交的数据。
异常
74.throw和throws的区别?
@1、throw:throw是语句抛出一个异常,一般是在代码块的内部,当程序出现某种逻辑错误时由程序员主动抛出某种特定类型的异常。
throws:throws是方法可能抛出异常的声明。(用在声明方法时,表示该方法可能要抛出异常),当某个方法可能会抛出某种异常时用于throws 声明可能抛出的异常,然后交给上层调用它的方法程序处理
@2、throw与throws的比较
1)throws出现在方法函数头;而throw出现在函数体。
2)throws表示出现异常的一种可能性,并不一定会发生这些异常;throw则是抛出了异常,执行throw则一定抛出了某种异常对象。
3)两者都是消极处理异常的方式(这里的消极并不是说这种方式不好),只是抛出或者可能抛出异常,但是不会由函数去处理异常,真正的处理异常由函数的上层调用处理。
@3、编程习惯
1)在写程序时,对可能会出现异常的部分通常要用try{…}catch{…}去捕捉它并对它进行处理;
2)用try{…}catch{…}捕捉了异常之后一定要对在catch{…}中对其进行处理,那怕是最简单的一句输出语句,或栈输入e.printStackTrace();
3)如果是捕捉IO输入输出流中的异常,一定要在try{…}catch{…}后加finally{…}把输入输出流关闭;
4)如果在函数体内用throw抛出了某种异常,最好要在函数名中加throws抛异常声明,然后交给调用它的上层函数进行处理。
75.final、finally、finalize有什么区别?
final:Java中的关键子,可用来修饰类、方法、属性,用在类上表示该类不能被继承,用在方法上表示该方法不能被重写,用在属性上表示该属性是常量不能修改。
finally:Java关键子,和try{…}catch(…){…}finally{…}一起使用,不管try{}块里面的代码报不报错,finally{}块都会执行,除非程序结束、退出(System.exit(0))。
finalize:finalize是方法名。java技术允许使用finalize()方法在垃圾收集器将对象从内存中清除出去之前做必要的清理工作。这个方法是由垃圾收集器在确定这个对象没有被引用时对这个对象调用的。它是在object类中定义的,因此所有的类都继承了它。子类覆盖finalize()方法以整理系统资源或者被执行其他清理工作。finalize()方法是在垃圾收集器删除对象之前对这个对象调用的。
76.try-catch-finally中那个部分可以省略?
:finally块
77.try-catch-finally中,如果catch中return了,finally还会执行吗?
:陈序执行的循序是try -----catch----finally----return ,所以finally会先执行,最后才执行return。
78.常见的异常类有那些?
异常非常多,Throwable 是异常的根类。
Throwable 包含子类 错误-Error 和 异常-Exception 。
Exception 又分为 一般异常和运行时异常 RuntimeException。
运行时异常不需要代码显式捕获处理。
下图是常见异常类及其父子关系:
Throwable
| ├ Error
| │ ├ IOError
| │ ├ LinkageError
| │ ├ ReflectionError
| │ ├ ThreadDeath
| │ └ VirtualMachineError
| │
| ├ Exception
| │ ├ CloneNotSupportedException
| │ ├ DataFormatException
| │ ├ InterruptedException
| │ ├ IOException
| │ ├ ReflectiveOperationException
| │ ├ RuntimeException
| │ ├ ArithmeticException
| │ ├ ClassCastException
| │ ├ ConcurrentModificationException
| │ ├ IllegalArgumentException
| │ ├ IndexOutOfBoundsException
| │ ├ NoSuchElementException
| │ ├ NullPointerException
| │ └ SecurityException
| │ └ SQLException
网络
79.HTTP响应吗301和302代表的是什么?有什么区别?
官方的比较简洁的说明:
301 redirect: 301 代表永久性转移(Permanently Moved)
302 redirect: 302 代表暂时性转移(Temporarily Moved )
ps:这里也顺带记住了两个比较相近的英语单词(permanently、temporarily),嘻哈!
详细来说,301和302状态码都表示重定向,就是说浏览器在拿到服务器返回的这个状态码后会自动跳转到一个新的URL地址,这个地址可以从响应的Location首部中获取(用户看到的效果就是他输入的地址A瞬间变成了另一个地址B)——这是它们的共同点。他们的不同在于。301表示旧地址A的资源已经被永久地移除了(这个资源不可访问了),搜索引擎在抓取新内容的同时也将旧的网址交换为重定向之后的网址;302表示旧地址A的资源还在(仍然可以访问),这个重定向只是临时地从旧地址A跳转到地址B,搜索引擎会抓取新的内容而保存旧的网址。
当一个网站或者网页24—48小时内临时移动到一个新的位置,这时候就要进行302跳转,打个比方说,我有一套房子,但是最近走亲戚去亲戚家住了,过两天我还回来的。而使用301跳转的场景就是之前的网站因为某种原因需要移除掉,然后要到新的地址访问,是永久性的,就比如你的那套房子其实是租的,现在租期到了,你又在另一个地方找到了房子,之前租的房子不住了。
清晰明确而言:
使用301跳转的场景:
1)域名到期不想续费(或者发现了更适合网站的域名),想换个域名。
2)在搜索引擎的搜索结果中出现了不带www的域名,而带www的域名却没有收录,这个时候可以用301重定向来告诉搜索引擎我们目标的域名是哪一个。
3)空间服务器不稳定,换空间的时候。
使用302跳转的场景:
–尽量使用301跳转!
为什么尽量要使用301跳转?——网址劫持!
这里摘录百度百科上的解释:
从网址A 做一个302 重定向到网址B 时,主机服务器的隐含意思是网址A 随时有可能改主意,重新显示本身的内容或转向其他的地方。大部分的搜索引擎在大部分情况下,当收到302 重定向时,一般只要去抓取目标网址就可以了,也就是说网址B。如果搜索引擎在遇到302 转向时,百分之百的都抓取目标网址B 的话,就不用担心网址URL 劫持了。问题就在于,有的时候搜索引擎,尤其是Google,并不能总是抓取目标网址。比如说,有的时候A 网址很短,但是它做了一个302 重定向到B 网址,而B 网址是一个很长的乱七八糟的URL 网址,甚至还有可能包含一些问号之类的参数。很自然的,A 网址更加用户友好,而B 网址既难看,又不用户友好。这时Google 很有可能会仍然显示网址A。由于搜索引擎排名算法只是程序而不是人,在遇到302 重定向的时候,并不能像人一样的去准确判定哪一个网址更适当,这就造成了网址URL 劫持的可能性。也就是说,一个不道德的人在他自己的网址A 做一个302 重定向到你的网址B,出于某种原因, Google 搜索结果所显示的仍然是网址A,但是所用的网页内容却是你的网址B 上的内容,这种情况就叫做网址URL 劫持。你辛辛苦苦所写的内容就这样被别人偷走了。302 重定向所造成的网址URL 劫持现象,已经存在一段时间了。不过到目前为止,似乎也没有什么更好的解决方法。在正在进行的谷歌大爸爸数据中心转换中,302 重定向问题也是要被解决的目标之一。从一些搜索结果来看,网址劫持现象有所改善,但是并没有完全解决。
80.forward和redirect的区别?
答:Forward和Redirect代表了两种请求转发方式:直接转发和间接转发。对应到代码里,分别是RequestDispatcher类的forward()方法和HttpServletRequest类的sendRedirect()方法。
对于间接方式,服务器端在响应第一次请求的时候,让浏览器再向另外一个URL发出请求,从而达到转发的目的。它本质上是两次HTTP请求,对应两个request对象。
对于直接方式,客户端浏览器只发出一次请求,Servlet把请求转发给Servlet、HTML、JSP或其它信息资源,由第2个信息资源响应该请求,两个信息资源共享同一个request对象。
最后,祝大家都能找到一个称心满意的工作!
81.简述 TCP和UDP的区别?
a) TCP面向连接(如打电话要先拨号建立连接);UDP是无连接的,即发送数据之前不需要建立连接
b) TCP提供可靠的服务。也就是说,通过TCP连接传送的数据,无差错,不丢失,不重复,且按序到达;UDP尽最大努力交付,即不保证可靠交付
Tcp通过校验和,重传控制,序号标识,滑动窗口、确认应答实现可靠传输。如丢包时的重发控制,还可以对次序乱掉的分包进行顺序控制。
c) UDP具有较好的实时性,工作效率比TCP高,适用于对高速传输和实时性有较高的通信或广播通信。
d) 每一条TCP连接只能是点到点的;UDP支持一对一,一对多,多对一和多对多的交互通信
e) TCP对系统资源要求较多,UDP对系统资源要求较少。
82.TCP为什么需要三次握手,两次不行吗?为什么?
以下部分转载自:tcp建立连接为什么需要三次握手
在《计算机网络》一书中其中有提到,三次握手的目的是“为了防止已经失效的连接请求报文段突然又传到服务端,因而产生错误”,这种情况是:一端(client)A发出去的第一个连接请求报文并没有丢失,而是因为某些未知的原因在某个网络节点上发生滞留,导致延迟到连接释放以后的某个时间才到达另一端(server)B。本来这是一个早已失效的报文段,但是B收到此失效的报文之后,会误认为是A再次发出的一个新的连接请求,于是B端就向A又发出确认报文,表示同意建立连接。如果不采用“三次握手”,那么只要B端发出确认报文就会认为新的连接已经建立了,但是A端并没有发出建立连接的请求,因此不会去向B端发送数据,B端没有收到数据就会一直等待,这样B端就会白白浪费掉很多资源。如果采用“三次握手”的话就不会出现这种情况,B端收到一个过时失效的报文段之后,向A端发出确认,此时A并没有要求建立连接,所以就不会向B端发送确认,这个时候B端也能够知道连接没有建立。(知乎上对上面的解释的评论:这个解答不是问题的本质,这个课本很多知识比较片面。问题的核心在于保证信道数据传输的可靠性,避免资源浪费仅仅是一个小的弱原因,不重要。)
这里写图片描述

问题的本质是,信道是不可靠的,但是我们要建立可靠的连接发送可靠的数据,也就是数据传输是需要可靠的。在这个时候三次握手是一个理论上的最小值,并不是说是tcp协议要求的,而是为了满足在不可靠的信道上传输可靠的数据所要求的。
83.说一下TCP粘包是怎么产生的?
这么说吧,TCP在传输数据的时候,是不区分边界的(数据和数据之间没有边界),因为是基于字节流,字节流是由字节组成,不包含边界数据的连续流。所以数据对TCP来说就是一大堆没有结构区别的字节块。那意味着什么?意味着TCP并不能对多个数据的整体的信息进行区分(打个比方:就像是你说一堆话没有标点符号全部连在一起,别人很可能弄错)或者对单个整体信息的错误区分(比如你要发送的整块数据被分成了好几块发送,然后这些数据在传输过程中可能由于网络原因,有的大数据块中被分片后的部分片段到了,可能由于接收端缓冲区满了,开始读取,而它们又没有边界之分,这时候就解释错误了)。那样就会使得我们要传输的信息可能粘连在一起,而被计算机解释错误。
而UDP是基于消息的传输服务,传输的是数据报,是有边界的。对于基于消息的协议来说,能保证对等方一次读操作返回的是一条消息,所以不会产生粘包问题。
84.OSI的七层模型都有那些?
物理层:物理接口规范,传输比特流,网卡是工作在物理层的。
数据层:成帧,保证帧的无误传输,MAC地址,形成EHTHERNET帧
网络层:路由选择,流量控制,IP地址,形成IP包
传输层:端口地址,如HTTP对应80端口。TCP和UDP工作于该层,还有就是差错校验和流量控制。
会话层:组织两个会话进程之间的通信,并管理数据的交换使用NETBIOS和WINSOCK协议。QQ等软件进行通讯因该是工作在会话层的。
表示层:使得不同操作系统之间通信成为可能。
应用层:对应于各个应用软件
85.Get和Post有哪些区别?
1. GET使用URL或Cookie传参。而POST将数据放在BODY中。
2. GET的URL会有长度上的限制,则POST的数据则可以非常大。
3. POST比GET安全,因为数据在地址栏上不可见。
(大佬说这写都是错的)
如何实现跨域?
跨域是由浏览器的同源策略引起的,跨域访问,简单来说就是 A 网站的 js脚本代码试图去访问 B 网站(代码中包括提交内容和获取内容)。但是由于安全原因,跨域访问是被各大浏览器所默认禁止的,而跨域与否的判断是根据同源策略来的。
87.说一下jsonp实现原理?
jsonp是解决跨域的一种方法
浏览器有一种约定叫同源策略,为了保证用户访问的安全,现代浏览器使用了同源策略,即不允许访问非同源的页面,但是有三个标签是允许跨域加载资源
<img src=xxx>
<link href=xxx>
<script src=xxx>
就是利用上述script标签没有跨域限制的漏洞,网页可以得到从其他来源动态产生的jsonp数据。前提条件是jsonp请求一定需要对方的服务器支持相应的格式,允许用户传递一个callback参数给服务端,然后服务端返回数据时会将这个callback参数作为函数名来包裹住JSON数据,这样客户端就可以随意定制自己的函数来自动处理返回数据了。
设计模式
88.说一下你熟悉的设计模式?
1)、创建型模式:单例模式、抽象工厂模式、建造者模式、工厂模式、原型模式。
2)、结构型模式:适配器模式、桥接模式、装饰模式、组合模式、外观模式、享元模式、代理模式。
3)、行为型模式:模版方法模式、命令模式、迭代器模式、观察者模式、中介者模式、备忘录模式、解释器模式、状态模式、策略模式、职责链模式、访问者模式。
89.简单工厂和抽象工厂有什么区别?
工厂模式(Factory Pattern)是 Java 中最常用的设计模式之一。这种类型的设计模式属于创建型模式,它提供了一种创建对象的最佳方式。
在工厂模式中,我们在创建对象时不会对客户端暴露创建逻辑,并且是通过使用一个共同的接口来指向新创建的对象。
简单工厂就是在工厂创建一个特定的对象。
抽象工厂模式(Abstract Factory Pattern)是围绕一个超级工厂创建其他工厂。该超级工厂又称为其他工厂的工厂。这种类型的设计模式属于创建型模式,它提供了一种创建对象的最佳方式。。
spring/spring MVC
90.为什么要使用Spring?
1).方便解耦,便于开发(Spring就是一个大工厂,可以将所有对象的创建和依赖关系维护都交给spring管理)
2).spring支持aop编程(spring提供面向切面编程,可以很方便的实现对程序进行权限拦截和运行监控等功能)
3).声明式事务的支持(通过配置就完成对事务的支持,不需要手动编程)
4).方便程序的测试,spring 对junit4支持,可以通过注解方便的测试spring 程序
5).方便集成各种优秀的框架()
6).降低javaEE API的使用难度(Spring 对javaEE开发中非常难用的一些API 例如JDBC,javaMail,远程调用等,都提供了封装,是这些API应用难度大大降低)
91.解释一下什么是AOP?
面向切面编程(Aspect Oriented Programming,AOP)其实就是一种关注点分离的技术,在软件工程领域一度是非常火的研究领域。我们软件开发时经常提一个词叫做“业务逻辑”或者“业务功能”,我们的代码主要就是实现某种特定的业务逻辑。但是我们往往不能专注于业务逻辑,比如我们写业务逻辑代码的同时,还要写事务管理、缓存、日志等等通用化的功能,而且每个业务功能都要和这些业务功能混在一起,痛苦!所以,为了将业务功能的关注点和通用化功能的关注点分离开来,就出现了AOP技术。这些通用化功能的代码实现,对应的就是我们说的切面(Aspect)
对方法的一种增强处理,像一些方法里面比较通用的方法,比如处理业务的时候,都需要事物,我们就可已把那些方法抽取取来,放在切面里,统一进行事物增强,从而减少编写事物的机械操作,使我们有更多的时间去专注处理业务逻辑。
原理:在外部存在一个和这个方法名相同的方法(切面),外部同名方法里面存在一个当前被增强的方法还有若干其他操作,比如事物,当掉用这个被增强的方法时,实际是调用外部的那个同名方法,从而达到增强效果。
92.解释一下什么是IOC?
通过IoC模式可以彻底解决代码耦合,它把耦合从代码中移出去,放到统一的XML文件中,通过一个容器在需要的时候把这个依赖关系形成,即把需要的接口实现注入到需要它的类中,这可能就是“依赖注入”说法的来源了。
IOC模式,系统中通过引入实现了IOC模式的IOC容器,即可由IOC容器来管理对象的生命周期、依赖关系等,从而使得应用程序的配置和依赖性规范与实际的应用程序代码分开。其中一个特点就是通过文本的配件文件进行应用程序组件间相互关系的配置,而不用重新修改并编译具体的代码。
93.spring有哪些主要模块?
Spring 框架是一个分层架构,由 7 个模块组成。
每个模块的作用如下:
核心容器(Spring Core):核心容器提供 Spring 框架的基本功能。核心容器的主要组件是 BeanFactory,它是工厂模式的实现。BeanFactory 使用控制反转 (IOC) 模式将应用程序的配置和依赖性规范与实际的应用程序代码分开。
Spring 上下文(Spring Context):Spring 上下文是一个配置文件,向 Spring 框架提供上下文信息。Spring 上下文包括企业服务,例如 JNDI(Java命名和目录接口)、EJB(Enterprise Java Beans称为Java 企业Bean)、电子邮件、国际化、校验和调度功能。
Spring AOP:通过配置管理特性,Spring AOP 模块直接将面向方面的编程功能集成到了 Spring 框架中。所以,可以很容易地使 Spring 框架管理的任何对象支持 AOP。Spring AOP 模块为基于 Spring 的应用程序中的对象提供了事务管理服务。通过使用 Spring AOP,不用依赖 EJB 组件,就可以将声明性事务管理集成到应用程序中。
Spring DAO:JDBC DAO 抽象层提供了有意义的异常层次结构,可用该结构来管理异常处理和不同数据库供应商抛出的错误消息。异常层次结构简化了错误处理,并且极大地降低了需要编写 的异常代码数量(例如打开和关闭连接)。Spring DAO 的面向 JDBC 的异常遵从通用的 DAO 异常层次结构。
Spring ORM:Spring 框架插入了若干个 ORM 框架,从而提供了 ORM 的对象关系工具,其中包括 JDO、Hibernate 和 iBatis SQL Map。所有这些都遵从 Spring 的通用事务和 DAO 异常层次结构。
Spring Web 模块:Web 上下文模块建立在应用程序上下文模块之上,为基于 Web 的应用程序提供了上下文。Web 模块还简化了处理多部分请求以及将请求参数绑定到域对象的工作。
Spring MVC 框架:MVC 框架是一个全功能的构建 Web 应用程序的 MVC 实现。通过策略接口,MVC 框架变成为高度可配置的,MVC 容纳了大量视图技术,其中包括 JSP。
94.Spring常用的注入方式有哪些?
一.基于注解注入
二.setter 方法注入
三:构造器注入
95.spring中的bean是线程安全的吗?
如果在你不定义成员变量的情况下,spring默认是线程安全的
否则,设置scope=“prototype”
一、在什么情况下,单例的Bean对象存在线程安全问题
当Bean对象对应的类存在可变的成员变量并且其中存在改变这个变量的线程时,多线程操作该Bean对象时会出现线程安全。
二、原因
当多线程中存在线程改变了bean对象的可变成员变量时,其他线程无法访问该bean对象的初始状态,从而造成数据错乱
三、解决办法
1.在Bean对象中尽量避免定义可变的成员变量;
2.在bean对象中定义一个ThreadLocal成员变量,将需要的可变成员变量保存在ThreadLocal中
96.Spring支持几种Bean的作用域?
scope属性如下
singleton:单例模式,在整个Spring IoC容器中,使用singleton定义的Bean将只有一个实例
prototype:原型模式,每次通过容器的getBean方法获取prototype定义的Bean时,都将产生一个新的Bean实例
request:对于每次HTTP请求,使用request定义的Bean都将产生一个新实例,即每次HTTP请求将会产生不同的Bean实例。只有在Web应用中使用Spring时,该作用域才有效
session:对于每次HTTP Session,使用session定义的Bean豆浆产生一个新实例。同样只有在Web应用中使用Spring时,该作用域才有效
globalsession:每个全局的HTTP Session,使用session定义的Bean都将产生一个新实例。典型情况下,仅在使用portlet context的时候有效。同样只有在Web应用中使用Spring时,该作用域才有效
97.spring自动装配Bean有哪些方式?
no:默认方式,手动装配方式,需要通过ref设定bean的依赖关系
byName:根据bean的名字进行装配,当一个bean的名称和其他bean的属性一致,则自动装配
byType:根据bean的类型进行装配,当一个bean的属性类型与其他bean的属性的数据类型一致,则自动装配
constructor:根据构造器进行装配,与 byType 类似,如果bean的构造器有与其他bean类型相同的属性,则进行自动装配
autodetect:如果有默认构造器,则以constructor方式进行装配,否则以byType方式进行装配
98.spring的事物实现方式有哪些?
(1)编程式事务管理对基于 POJO 的应用来说是唯一选择。我们需要在代码中调用beginTransaction()、commit()、rollback()等事务管理相关的方法,这就是编程式事务管理。
(2)基于 TransactionProxyFactoryBean的声明式事务管理
(3)基于 @Transactional 的声明式事务管理
(4)基于Aspectj AOP配置事务管理
99.说一下Spring的事物隔离?
事务特性(4种):
原子性 (atomicity):强调事务的不可分割.
一致性 (consistency):事务的执行的前后数据的完整性保持一致.
隔离性 (isolation):一个事务执行的过程中,不应该受到其他事务的干扰
持久性(durability) :事务一旦结束,数据就持久到数据库
解决读问题: 设置事务隔离级别(5种)
DEFAULT 这是一个PlatfromTransactionManager默认的隔离级别,使用数据库默认的事
务隔离级别.
未提交读(read uncommited) :脏读,不可重复读,虚读都有可能发生
已提交读 (read commited):避免脏读。但是不可重复读和虚读有可能发生
可重复读 (repeatable read) :避免脏读和不可重复读.但是虚读有可能发生.
串行化的 (serializable) :避免以上所有读问题.
事务的传播行为 (7)
PROPAGION_XXX :事务的传播行为
-
保证同一个事务中
PROPAGATION_REQUIRED 支持当前事务,如果不存在 就新建一个(默认)
PROPAGATION_SUPPORTS 支持当前事务,如果不存在,就不使用事务
PROPAGATION_MANDATORY 支持当前事务,如果不存在,抛出异常 -
保证没有在同一个事务中
PROPAGATION_REQUIRES_NEW 如果有事务存在,挂起当前事务,创建一个新的事务
PROPAGATION_NOT_SUPPORTED 以非事务方式运行,如果有事务存在,挂起当前事务
PROPAGATION_NEVER 以非事务方式运行,如果有事务存在,抛出异常
PROPAGATION_NESTED 如果当前事务存在,则嵌套事务执行
100.说一下Spring MVC的运行流程?
转自:http://blog.csdn.net/j080624/article/details/56273665
http://blog.csdn.net/j080624/article/details/57411870 springmvc流程流转源码的例子1
http://blog.csdn.net/j080624/article/details/58041191 springmvc流程流转源码的例子2
Spring MVC工作流程图



Spring工作流程描述
1. 用户向服务器发送请求,请求被Spring 前端控制Servelt DispatcherServlet捕获;
2. DispatcherServlet对请求URL进行解析,得到请求资源标识符(URI)。然后根据该URI,调用HandlerMapping获得该Handler配置的所有相关的对象(包括Handler对象以及Handler对象对应的拦截器),最后以HandlerExecutionChain对象的形式返回;
3. DispatcherServlet 根据获得的Handler,选择一个合适的HandlerAdapter。(附注:如果成功获得HandlerAdapter后,此时将开始执行拦截器的preHandler(…)方法)
4. 提取Request中的模型数据,填充Handler入参,开始执行Handler(Controller)。 在填充Handler的入参过程中,根据你的配置,Spring将帮你做一些额外的工作:
HttpMessageConveter: 将请求消息(如Json、xml等数据)转换成一个对象,将对象转换为指定的响应信息
数据转换:对请求消息进行数据转换。如String转换成Integer、Double等
数据根式化:对请求消息进行数据格式化。 如将字符串转换成格式化数字或格式化日期等
数据验证: 验证数据的有效性(长度、格式等),验证结果存储到BindingResult或Error中
5. Handler执行完成后,向DispatcherServlet 返回一个ModelAndView对象;
6. 根据返回的ModelAndView,选择一个适合的ViewResolver(必须是已经注册到Spring容器中的ViewResolver)返回给DispatcherServlet ;
7. ViewResolver 结合Model和View,来渲染视图
8. 将渲染结果返回给客户端
101.Spring MVC有哪些组件?
1. 前端控制器组件(DispatcherServlet)
2. 处理器组件(Controller)
3. 处理器映射器组件(HandlerMapping)
4. 处理器适配器组件(HandlerAdapter)
5. 拦截器组件(HandlerInterceptor)
6. 视图解析器组件(ViewResolver)
7. 视图组件(View)
8. 数据转换组件(DataBinder)
9. 消息转换器组件(HttpMessageConverter)
102.@requestMappping的作用是什么?
@RequestMapping是一个用来处理请求地址映射的注解,可用于类或者方法上。用于类上,表示类中的所有响应请求的方法都是以该地址作为父路径。
@RequestMapping注解有六个属性,下面进行详细的说明。
1.value, method
value:指定请求的实际地址,指定的地址可以是URI Template模式。
method:指定请求的method类型,GET、POST、PUT、DELETE等。
2.consumes, produces
consumes:指定处理请求的提交内容类型(Content-Type),例如application/json,text/html。
produces:指定返回的内容类型,仅当request请求头中的(Accept)类型中包含该指定类型才返回。
3.params, headers
params:指定request中必须包含某些参数值才让该方法处理。
headers:指定request中必须包含某些指定的header值,才能让该方法处理请求。
103.@autowired的作用是什么?
Spring2.5加入了@Autowired注解,它的作用是自动装配bean,而无需再为field设置getter,setter方法。
Spring Boot/Spring Cloud
104.什么是Spring Boot?
SpringBoot是伴随着Spring4.0诞生的;
从字面理解,Boot是引导的意思,因此SpringBoot帮助开发者快速搭建Spring框架;
SpringBoot帮助开发者快速启动一个Web容器;
SpringBoot继承了原有Spring框架的优秀基因;
SpringBoot简化了使用Spring的过程。
105.为什么要用Spring Boot?
-
Spring Boot使编码变简单
-
Spring Boot使配置变简单
-
Spring Boot使部署变简单
-
Spring Boot使监控变简单
-
Spring Boot的不足
-
106.Spring Boot核心配置文件是什么?
bootstrap (.yml 或者 .properties)
优先级跟高,属性不能覆盖
application (.yml 或者 .properties)
107.Spring Boot配置文件有哪几种类型?他们有什么区别?
bootstrap (.yml 或者 .properties)
application (.yml 或者 .properties)
官方原文描述:
Spring Cloud 构建于 Spring Boot 之上,在 Spring Boot 中有两种上下文,一种是 bootstrap, 另外一种是 application, bootstrap 是应用程序的父上下文,也就是说 bootstrap 加载优先于 applicaton。bootstrap 主要用于从额外的资源来加载配置信息,还可以在本地外部配置文件中解密属性。这两个上下文共用一个环境,它是任何Spring应用程序的外部属性的来源。bootstrap 里面的属性会优先加载,它们默认也不能被本地相同配置覆盖。
108.Spring Boot有哪些方式可以实现热部署?
在项目开发过程中,常常会改动页面数据或者修改数据结构,为了显示改动效果,往往需要重启应用查看改变效果,其实就是重新编译生成了新的 Class 文件,这个文件里记录着和代码等对应的各种信息,然后 Class 文件将被虚拟机的 ClassLoader 加载。
而热部署正是利用了这个特点,它监听到如果有 Class 文件改动了,就会创建一个新的 ClaassLoader 进行加载该文件,经过一系列的过程,最终将结果呈现在我们眼前。
类加载机制
Java 中的类经过编译器可以把代码编译为存储字节码的 Class 文件,该 Class 文件存储了各种信息,最终要加载到虚拟机中运行使用。
类加载机制(摘自《深入理解 Java 虚拟机》)
虚拟机把描述类的数据从 Class 文件加载到内存中,并对数据进行校验、转换解析和初始化,最终形成可以被虚拟机直接使用的 Java 类型。
使用 Spring Loaded
使用 spring-boot-devtools
109.JPA和Hibernate有什么区别?
JPA全称: Java Persistence API
JPA本身是一种规范,它的本质是一种ORM规范(不是ORM框架,因为JPA并未提供ORM实现,只是制定了规范)因为JPA是一种规范,所以,只是提供了一些相关的接口,但是接口并不能直接使用,JPA底层需要某种JPA实现,JPA现在就是Hibernate功能的一个子集
Hibernate 从3.2开始,就开始兼容JPA。Hibernate3.2获得了Sun TCK的 JPA(Java Persistence API) 兼容认证。JPA和Hibernate之间的关系,可以简单的理解为JPA是标准接口,Hibernate是实现,并不是对标关系,借用下图可以看清楚他们之间的关系,Hibernate属于遵循JPA规范的一种实现,但是JPA是Hibernate遵循的规范之一,Hibernate还有其他实现的规范,所以它们的关系更像是JPA是一种做面条的规范,而Hibernate是一种遵循做面条的规范的汤面,他不仅遵循了做面条的规范,同时也会遵循做汤和调料的其他规范,他们之间并不是吃面条和吃米饭的关系
总的来说,JPA是规范,Hibernate是框架,JPA是持久化规范,而Hibernate实现了JPA。
题外的一些思考:如果抛开JPA直接使用Hibernate的注解来定义一个实例,很快发现了几个问题:
1)jpa中有Entity, Table,hibernate中也有,但是内容不同
2)jpa中有Column,OneToMany等,Hibernate中没有,也没有替代品
hibernate对jpa的支持,不是另提供了一套专用于jpa的注解。一些重要的注解如Column, OneToMany等,hibernate没有提供,这说明jpa的注解已经是hibernate 的核心,hibernate只提供了一些补充,而不是两套注解。要是这样,hibernate对jpa的支持还真够足量,我们要使用hibernate注解就必定要使用jpa。
110.什么是Spring Cloud?
Spring Cloud是一个相对比较新的微服务框架,今年(2016)才推出1.0的release版本. 虽然Spring Cloud时间最短, 但是相比Dubbo等RPC框架, Spring Cloud提供的全套的分布式系统解决方案。
Spring Cloud 为开发者提供了在分布式系统(配置管理,服务发现,熔断,路由,微代理,控制总线,一次性token,全居琐,leader选举,分布式session,集群状态)中快速构建的工具,使用Spring Cloud的开发者可以快速的启动服务或构建应用、同时能够快速和云平台资源进行对接。
111.Spring Cloud断路器的作用是什么?
多个微服务之间调用的时候,假设微服务A调用微服务B和微服务C,微服务B和微服务C又在调用其他的微服务,这就是所谓的“扇出”。如果扇出的链路上某个微服务的调用响应时间过长或者不可用,那么对微服务A的调用就会占用越来越多的系统资源,进而引起系统崩溃,这就是所谓的“雪崩效应”。
那么当某个服务发生故障时,通过 Hystrix,会向调用方返回一个符合预期的、可处理的默认响应(也称备选响应,即fallBack),而不是长时间的等待或者直接返回一个异常信息。这样就能保证服务调用方可以顺利的处理逻辑,而不是那种漫长的等待或者其他故障。
这就叫“服务熔断”,就跟熔断保险丝一个道理。
112.Spring Cloud核心组件有哪些?
Spring Cloud技术应用从场景上可以分为两大类:润物无声类和独挑大梁类。
润物无声,融合在每个微服务中、依赖其它组件并为其提供服务。
Ribbon,客户端负载均衡,特性有区域亲和、重试机制。
Hystrix,客户端容错保护,特性有服务降级、服务熔断、请求缓存、请求合并、依赖隔离。
Feign,声明式服务调用,本质上就是Ribbon+Hystrix
Stream,消息驱动,有Sink、Source、Processor三种通道,特性有订阅发布、消费组、消息分区。
Bus,消息总线,配合Config仓库修改的一种Stream实现,
Sleuth,分布式服务追踪,需要搞清楚TraceID和SpanID以及抽样,如何与ELK整合。
独挑大梁,独自启动不需要依赖其它组件。
Eureka,服务注册中心,特性有失效剔除、服务保护。
Dashboard,Hystrix仪表盘,监控集群模式和单点模式,其中集群模式需要收集器Turbine配合。
Zuul,API服务网关,功能有路由分发和过滤。
Config,分布式配置中心,支持本地仓库、SVN、Git、Jar包内配置等模式,
Hibernate
113.为什么要使用Hibernate?
- 对JDBC访问数据库的代码做了封装,大大简化了数据访问层繁琐的重复性代码。
- Hibernate是一个基于JDBC的主流持久化框架,是一个优秀的ORM实现。他很大程度的简化DAO层的编码工作
- hibernate使用Java反射机制,而不是字节码增强程序来实现透明性。
- hibernate的性能非常好,因为它是个轻量级框架。映射的灵活性很出色。它支持各种关系数据库,从一对一到多对多的各种复杂关系。
114.什么是ORM框架?
对象关系映射,目前数据库是关系型数据库 ORM 主要是把数据库中的关系数据映射称为程序中的对象
115.Hibernate中如何在控制台打印的SQL语句?
在配置文件中加入:
spring.jpa.properties.hibernate.show_sql=true //控制台是否打印
spring.jpa.properties.hibernate.format_sql=true //格式化sql语句
spring.jpa.properties.hibernate.use_sql_comments=true //指出是什么操作生成了该语句
116.hibernate有几种查询方式?
hql查询,sql查询,条件查询
HQL: Hibernate Query Language. 面向对象的写法:
Query query = session.createQuery(“from Customer where name = ?”);
query.setParameter(0, “苍老师”);
Query.list();
QBC: Query By Criteria.(条件查询)
Criteria criteria = session.createCriteria(Customer.class);
criteria.add(Restrictions.eq(“name”, “花姐”));
List list = criteria.list();
SQL:
SQLQuery query = session.createSQLQuery(“select * from customer”);
List<Object[]> list = query.list();
SQLQuery query = session.createSQLQuery(“select * from customer”);
query.addEntity(Customer.class);
List list = query.list();
Hql: 具体分类
1、 属性查询 2、 参数查询、命名参数查询 3、 关联查询 4、 分页查询 5、 统计函数
HQL和SQL的区别
HQL是面向对象查询操作的,SQL是结构化查询语言 是面向数据库表结构的
117.Hibernate实体类可以被定义为final吗?
:不能
使用非final类:在运行时生成代理是Hibernate的一个重要的功能。如果持久化类没有实现任何接口,hibernate使用CGLIB生成代理。如果使用的是final类,则无法生成CGLIB代理
118.在Hibernate中使用Integer和int有什么区别?
1、返回数据库字段值是null的话,int类型会报错。int是基本数据类型,其声明的是变量,而null则是对象。所以hibernate实体建议用integer;
2、通过jdbc将实体存储到数据库的操作通过sql语句,基本数据类型可以直接存储,对象需要序列化存储。
119.Hibernate是如何工作的?
hibernate核心接口
session:负责被持久化对象CRUD操作
sessionFactory:负责初始化hibernate,创建session对象
configuration:负责配置并启动hibernate,创建SessionFactory
Transaction:负责事物相关的操作
Query和Criteria接口:负责执行各种数据库查询
Hibernate工作原理
1.通过Configuration config = new Configuration().configure();//读取并解析hibernate.cfg.xml配置文件
2.由hibernate.cfg.xml中的读取并解析映射信息
3.通过SessionFactory sf = config.buildSessionFactory();//创建SessionFactory
4.Session session = sf.openSession();//打开Sesssion
5.Transaction tx = session.beginTransaction();//创建并启动事务Transation
6.persistent operate操作数据,持久化操作
7.tx.commit();//提交事务
8.关闭Session
9.关闭SesstionFactory
120.get()和load()的区别?
-
对于Hibernate get方法,Hibernate会确认一下该id对应的数据是否存在,首先在session缓存中查找,然后在二级缓存中查找,还没有就查询数据库,数据 库中没有就返回null。这个相对比较简单,也没有太大的争议。主要要说明的一点就是在这个版本(bibernate3.2以上)中get方法也会查找二级缓存!
-
Hibernate load方法加载实体对象的时候,根据映射文件上类级别的lazy属性的配置(默认为true),分情况讨论:
(1)若为true,则首先在Session缓存中查找,看看该id对应的对象是否存在,不存在则使用延迟加载,返回实体的代理类对象(该代理类为实体类的子类,由CGLIB动态生成)。等到具体使用该对象(除获取OID以外)的时候,再查询二级缓存和数据库,若仍没发现符合条件的记录,则会抛出一个ObjectNotFoundException。
(2)若为false,就跟Hibernateget方法查找顺序一样,只是最终若没发现符合条件的记录,则会抛出一个ObjectNotFoundException。
这里get和load有两个重要区别:
如果未能发现符合条件的记录,Hibernate get方法返回null,而load方法会抛出一个ObjectNotFoundException。
load方法可返回没有加载实体数据的代 理类实例,而get方法永远返回有实体数据的对象。
(对于load和get方法返回类型:好多书中都说:“get方法永远只返回实体类”,实际上并不正 确,get方法如果在session缓存中找到了该id对应的对象,如果刚好该对象前面是被代理过的,如被load方法使用过,或者被其他关联对象延迟加 载过,那么返回的还是原先的代理对象,而不是实体类对象,如果该代理对象还没有加载实体数据(就是id以外的其他属性数据),那么它会查询二级缓存或者数 据库来加载数据,但是返回的还是代理对象,只不过已经加载了实体数据。)
总之对于get和load的根本区别,一句话,hibernate对于 load方法认为该数据在数据库中一定存在,可以放心的使用代理来延迟加载,如果在使用过程中发现了问题,只能抛异常;而对于get方 法,hibernate一定要获取到真实的数据,否则返回null。
121.说一下Hibernate的缓存机制?
Hibernate缓存的作用:
Hibernate是一个持久层框架,经常访问物理数据库,为了降低应用程序对物理数据源访问的频次,从而提高应用程序的运行性能。缓存内的数据是对物理数据源中的数据的复制,应用程序在运行时从缓存读写数据,在特定的时刻或事件会同步缓存和物理数据源的数据
Hibernate缓存分类:
Hibernate缓存包括两大类:Hibernate一级缓存和Hibernate二级缓存
Hibernate一级缓存又称为“Session的缓存”,它是内置的,意思就是说,只要你使用hibernate就必须使用session缓存。由于Session对象的生命周期通常对应一个数据库事务或者一个应用事务,因此它的缓存是事务范围的缓存。在第一级缓存中,持久化类的每个实例都具有唯一的OID。
Hibernate二级缓存又称为“SessionFactory的缓存”,由于SessionFactory对象的生命周期和应用程序的整个过程对应,因此Hibernate二级缓存是进程范围或者集群范围的缓存,有可能出现并发问题,因此需要采用适当的并发访问策略,该策略为被缓存的数据提供了事务隔离级别。第二级缓存是可选的,是一个可配置的插件,在默认情况下,SessionFactory不会启用这个插件。
122.Hibernate对象有哪些状态?
瞬时状态(Transient):比如new出来的对象,和数据库没一点关系的。
持久状态(Persistent):比如从数据库中查到数据或者新增的数据。
游离状态(Detached):比如删除数据。和数据库没什么关系的。
123.在hibernate中getCurrentSession和openSession的区别是什么?
1、openSession() 是获取一个新的session;而getCurrentSession() 是获取和当前线程绑定的session,换言之,在同一个线程中,我们获取的session是同一个session,这样可以利于事务控制。
2、使用getCurrentSession()需要在hibernate.cfg.xml文件中加入如下配置:
如果使用的是本地事务(jdbc事务)
thread
如果使用的是全局事务(jta事务)
jta
3、通过 getCurrentSession() 获取的session在commit或rollback时会自动关闭;通过openSession()获取的session则必须手动关闭。
4、通过getCurrentSession() 获取sesssion进行查询需要事务提交;而通过openSession()进行查询时可以不用事务提交。
openSession需要手动关闭session。
getCurrentSession用完自动关闭session。
124.Hibernate实体类必须要有无参构造函数吗?为什么?
hibernate 为什么持久化类时必须提供一个不带参数的默认构造函数,因为hibernate框架会调用这个默认构造方法来构造实例对象。
即Class类的newInstance方法 这个方法就是通过调用默认构造方法来创建实例对象的 ,
mybatis
125.Mybatis中#{}和${}的区别?
1.数据类型匹配
#:会进行预编译,而且进行类型匹配
$:不进行数据类型匹配
2.实现方式
#:用于变量替换
$:实质上是字符串拼接
3.#和$的使用场景
(1)变量的传递,必须使用#,使用#{}就等于使用了PrepareStatement这种占位符的形式,提高效率。可以防止sql注入等等问题。#方式一般用于传入添加,修改的值或查询,删除的where条件 id值
select * from t_user where name = #{param}
(2) 只 是 只 是 简 单 的 字 符 串 拼 接 , 要 特 别 小 心 s q l 注 入 问 题 , 对 应 非 变 量 部 分 , 只 能 用 只是只是简单的字符串拼接,要特别小心sql注入问题,对应非变量部分,只能用 只是只是简单的字符串拼接,要特别小心sql注入问题,对应非变量部分,只能用。 方 式 一 般 用 于 传 入 数 据 库 对 象 , 比 如 这 种 g r o u p b y 字 段 , o r d e r b y 字 段 , 表 名 , 字 段 名 等 没 法 使 用 占 位 符 的 就 需 要 使 用 方式一般用于传入数据库对象,比如这种group by 字段 ,order by 字段,表名,字段名等没法使用占位符的就需要使用 方式一般用于传入数据库对象,比如这种groupby字段,orderby字段,表名,字段名等没法使用占位符的就需要使用{}
select count(*), from t_user group by ${param}
(3)能同时使用#和$的时候,最好用#。
126.Mybatis有几种分页方式?
:两种
逻辑分页:用MySQL数据库关键字limit,oracle需要嵌套子查询分页。
物理分页(假分页):查询所有匹配的数据,在内存中进行分页。
127.RowBounds是一次性查询全部结果吗?为什么?
RowBounds在处理分页时,只是简单的把offset之前的数据都skip掉,超过limit之后的数据不取出,上图中的代码取自MyBatis中的DefaultResultSetHandler类。跳过offset之前的数据是由方法skipRows处理,判断数据是否超过了limit则是由shouldProcessMoreRows方法进行判断。简单点说道,就是先把数据全部查询到ResultSet,然后从ResultSet中取出offset和limit之间的数据,这就实现了分页查询。
128.Mybatis逻辑分页和物理分页的区别是什么?
逻辑分页:用MySQL数据库关键字limit,oracle需要嵌套子查询分页。
物理分页(假分页):查询所有匹配的数据,在程序中进行分页。
129.mybatis是否支持延迟加载?延迟加载的原理是什么?
:支持懒加载
当我们在处里一对N个关系(就是一个对象对应多个对象时)时,我们查询该对象,势必要关联查询其他表的数据,但是了,有可能我们关联的数据业务中也许用不到,查询出来没用,这样很浪费系统的资源,这是我们就可以设置这个属性为延迟加载,又叫懒加载,当我们用到的时候再去关联查询数据库,节省系统开销。
130.说一下Mybatis一级缓存和二级缓存?
一级缓存:是SQlSession级别的缓存。在操作数据库时需要构造SqlSession对象,在对象中有一个数据结构(HashMap)用于存储缓存数据。不同的SqlSession之间的缓存数据区域(HashMap)是互相不影响的。
MyBatis的一级缓存指的是在一个Session域内,session为关闭的时候执行的查询会根据SQL为key被缓存(跟mysql缓存一样,修改任何参数的值都会导致缓存失效)。
二级缓存:二级缓存就是global caching,它超出session范围之外,可以被所有sqlSession共享,它的实现机制和mysql的缓存一样,开启它只需要在mybatis的配置文件开启settings里的
以及在相应的Mapper文件(例如userMapper.xml)里开启
复制代码
… select statement …
131.Mybatis和Hibernate的区别有哪些?
一、mybatis和hibernate的区别
Mybatis和hibernate不同,它不完全是一个ORM框架,因为MyBatis需要程序员自己编写Sql语句,不过mybatis可以通过XML或注解方式灵活配置要运行的sql语句,并将java对象和sql语句映射生成最终执行的sql,最后将sql执行的结果再映射生成java对象。
Mybatis学习门槛低,简单易学,程序员直接编写原生态sql,可严格控制sql执行性能,灵活度高,非常适合对关系数据模型要求不高的软件开发,例如互联网软件、企业运营类软件等,因为这类软件需求变化频繁,一但需求变化要求成果输出迅速。但是灵活的前提是mybatis无法做到数据库无关性,如果需要实现支持多种数据库的软件则需要自定义多套sql映射文件,工作量大。
Hibernate对象/关系映射能力强,数据库无关性好,对于关系模型要求高的软件(例如需求固定的定制化软件)如果用hibernate开发可以节省很多代码,提高效率。但是Hibernate的学习门槛高,要精通门槛更高,而且怎么设计O/R映射,在性能和对象模型之间如何权衡,以及怎样用好Hibernate需要具有很强的经验和能力才行。
总之,按照用户的需求在有限的资源环境下只要能做出维护性、扩展性良好的软件架构都是好架构,所以框架只有适合才是最好。
132.mybatis有哪些执行器(Executor)?
SimpleExecutor、ReuseExecutor、BatchExecutor。
SimpleExecutor:每执行一次update或select,就开启一个Statement对象,用完立刻关闭Statement对象。
ReuseExecutor:执行update或select,以sql作为key查找Statement对象,存在就使用,不存在就创建,用完后,不关闭Statement对象,而是放置于Map内,供下一次使用。简言之,就是重复使用Statement对象。
BatchExecutor:执行update(没有select,JDBC批处理不支持select),将所有sql都添加到批处理中(addBatch()),等待统一执行(executeBatch()),它缓存了多个Statement对象,每个Statement对象都是addBatch()完毕后,等待逐一执行executeBatch()批处理。与JDBC批处理相同。
作用范围:Executor的这些特点,都严格限制在SqlSession生命周期范围内。
133.Mybatis分页插件的实现原理是什么?
PageHelper拦截的是org.apache.ibatis.executor.Executor的query方法,其传参的核心原理是通过ThreadLocal进行的。当我们需要对某个查询进行分页查询时,我们可以在调用Mapper进行查询前调用一次PageHelper.startPage(…),这样PageHelper会把分页信息存入一个ThreadLocal变量中。在拦截到Executor的query方法执行时会从对应的ThreadLocal中获取分页信息,获取到了,则进行分页处理,处理完了后又会把ThreadLocal中的分页信息清理掉,以便不影响下一次的查询操作。所以当我们使用了PageHelper.startPage(…)后,每次将对最近一次的查询进行分页查询,如果下一次查询还需要进行分页查询,需要重新进行一次PageHelper.startPage(…)。这样就做到了在引入了分页后可以对原来的查询代码没有任何的侵入性。此外,在进行分页查询时,我们的返回结果一般是一个java.util.List,PageHelper分页查询后的结果会变成com.github.pagehelper.Page类型,其继承了java.util.ArrayList,所以不会对我们的方法声明造成影响。com.github.pagehelper.Page中包含有返回结果的分页信息,包括总记录数,总的分页数等信息,所以一般我们需要把返回结果强转为com.github.pagehelper.Page类型。以下是一个简单的使用PageHelper进行分页查询的示例代码。
@Test
public void test() {
int pageNum = 2;//页码,从1开始
int pageSize = 10;//每页记录数
PageHelper.startPage(pageNum, pageSize);//指定开始分页
UserMapper userMapper = this.session.getMapper(UserMapper.class);
List all = userMapper.findAll();
Page page = (Page) all;
System.out.println(page.getPages());
System.out.println(page);
}
134.Mybatis如何编写一个自定义插件?
- 编写Interceptor的实现类
- 使用@Intercepts注解完成插件签名 说明插件的拦截四大对象之一的哪一个对象的哪一个方法
- 将写好的插件注册到全局配置文件中
RabbtMQ
135.RabbtMQ的使用场景有哪些?
1)异步处理
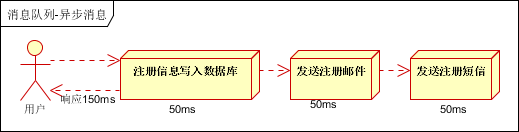

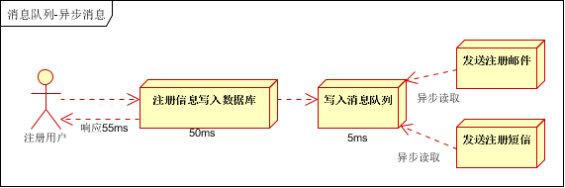
2)应用解耦
3)流量削峰
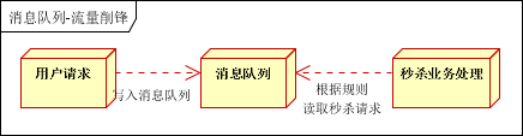
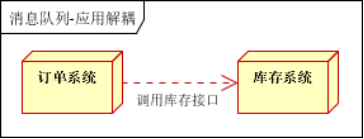
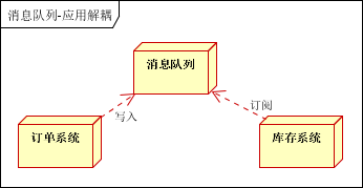
在应用方面,RabbitMQ起源于金融系统,主要用于分布式系统的内部各子系统之间的数据存储转发,这是系统解耦方面的一种运用。
1)即如果是单体应用则通常可以使用内存队列,如Java的BlockingQueue即可,而将单体应用拆分为分布式系统之后,则通过RabbitMQ这种进程队列来在各子系统之间进行消息传递,从而达到解耦的作用。
2)除此之外,RabbitMQ还可以运用在高并发系统当中的流量削峰,即将请求流量数据临时存放到RabbitMQ当中,从而避免大量的请求流量直接达到后台服务,把后台服务冲垮。通过使用RabbitMQ来存放这些请求流量,后台服务从RabbitMQ中消费数据,从而达到流量削峰的目的。
3)处理系统解耦和流量削峰外,RabbitMQ最常用于消息通讯,即可以用于实现IM聊天系统。
136.RabbitMQ有哪些重要的角色?
RabbitMQ 中重要的角色有:生产者、消费者和代理:
生产者:消息的创建者,负责创建和推送数据到消息服务器;
消费者:消息的接收方,用于处理数据和确认消息;
代理:就是 RabbitMQ 本身,用于扮演“快递”的角色,本身不生产消息,只是扮演“快递”的角色。
RabbitMQ各类角色描述:
1)none
不能访问 management plugin
2)management
用户可以通过AMQP做的任何事外加:
列出自己可以通过AMQP登入的virtual hosts
查看自己的virtual hosts中的queues, exchanges 和 bindings
查看和关闭自己的channels 和 connections
查看有关自己的virtual hosts的“全局”的统计信息,包含其他用户在这些virtual hosts中的活动。
3)policymaker
management可以做的任何事外加:
查看、创建和删除自己的virtual hosts所属的policies和parameters
4)monitoring
management可以做的任何事外加:
列出所有virtual hosts,包括他们不能登录的virtual hosts
查看其他用户的connections和channels
查看节点级别的数据如clustering和memory使用情况
查看真正的关于所有virtual hosts的全局的统计信息
5)administrator
policymaker和monitoring可以做的任何事外加:
创建和删除virtual hosts
查看、创建和删除users
查看创建和删除permissions
关闭其他用户的connections
可以创建管理员用户,负责整个MQ的运维,例如:
$sudo rabbitmqctl add_user user_admin passwd_admin
赋予其administrator角色:
$sudo rabbitmqctl set_user_tags user_admin administrator
137.RabbitMQ有哪些重要的组件?
1)Message
消息,消息是不具名的,它由消息头和消息体组成。消息体是不透明的,而消息头则由一系列的可选属性组成,这些属性包括routing-key(路由键)、priority(相对于其他消息的优先权)、delivery-mode(指出该消息可能需要持久性存储)等。
2)Publisher
消息的生产者,也是一个向交换器发布消息的客户端应用程序。
3)Exchange
交换器,用来接收生产者发送的消息并将这些消息路由给服务器中的队列。
Exchange有4种类型:direct(默认),fanout, topic, 和headers,不同类型的Exchange转发消息的策略有所区别
4)Queue
消息队列,用来保存消息直到发送给消费者。它是消息的容器,也是消息的终点。一个消息可投入一个或多个队列。消息一直在队列里面,等待消费者连接到这个队列将其取走。
5)Binding
绑定,用于消息队列和交换器之间的关联。一个绑定就是基于路由键将交换器和消息队列连接起来的路由规则,所以可以将交换器理解成一个由绑定构成的路由表。
Exchange 和Queue的绑定可以是多对多的关系。
6)Connection
网络连接,比如一个TCP连接。
7)Channel
信道,多路复用连接中的一条独立的双向数据流通道。信道是建立在真实的TCP连接内的虚拟连接,AMQP 命令都是通过信道发出去的,不管是发布消息、订阅队列还是接收消息,这些动作都是通过信道完成。因为对于操作系统来说建立和销毁 TCP 都是非常昂贵的开销,所以引入了信道的概念,以复用一条 TCP 连接。
8)Virtual Host
多租户或者称为虚拟主机vhost,主要用于实现不同业务系统之间的消息队列的隔离,即可以部署一个RabbitMQ服务端,但是可以设置多个虚拟主机给多个不同的业务系统使用,这些虚拟主机对应的消息队列内部的数据是相互隔离的。所以多个虚拟主机也类似于同一套房子里面的多个租户,每个租户都自己做饭吃饭,而不会去其他租户家里做饭吃饭。
虚拟主机的概念相当于Java应用程序的命名空间namespace,不同虚拟主机内部可以包含相同名字的队列。
RabbitMQ服务器默认包含一个虚拟主机,即“/”,如果需要创建其他的虚拟主机,可以在RabbitMQ控制台执行如下命令:通过rabbitmqctl add_vhost命令添加一个新的“test_host”虚拟主机。
9)Broker
在AMQP协议中,消息队列服务器称为Broker,在Broker中接收生产者的消息,将该消息放入对应的队列中,然后将消息分发给消息这个队列消息的消费者。所以Broker内部通常包含数据交换器Exchanger,队列Queue两大组件和需要实现这两大组件之间的绑定。

138.RabbitMQ中VHost的作用是什么?
vhost本质上是一个mini版的RabbitMQ服务器,拥有自己的队列、绑定、交换器和权限控制;
vhost通过在各个实例间提供逻辑上分离,允许你为不同应用程序安全保密地运行数据;
vhost是AMQP概念的基础,必须在连接时进行指定,RabbitMQ包含了默认vhost:“/”;
当在RabbitMQ中创建一个用户时,用户通常会被指派给至少一个vhost,并且只能访问被指派vhost内的队列、交换器和绑定,vhost之间是绝对隔离的。
多租户或者称为虚拟主机vhost,主要用于实现不同业务系统之间的消息队列的隔离,即可以部署一个RabbitMQ服务端,但是可以设置多个虚拟主机给多个不同的业务系统使用,这些虚拟主机对应的消息队列内部的数据是相互隔离的。所以多个虚拟主机也类似于同一套房子里面的多个租户,每个租户都自己做饭吃饭,而不会去其他租户家里做饭吃饭。
虚拟主机的概念相当于Java应用程序的命名空间namespace,不同虚拟主机内部可以包含相同名字的队列。
RabbitMQ服务器默认包含一个虚拟主机,即“/”,如果需要创建其他的虚拟主机,可以在RabbitMQ控制台执行如下命令:通过rabbitmqctl add_vhost命令添加一个新的“test_host”虚拟主机。
139.RabbitMQ的消息是怎么发送的?

生产者发送消息(对象或字符串),把消息序列化或转成json格式(统一转化,因为不能够发送对象),然后发送到交换机(这里用的是topic),然后通过路由键发送到消息队列。等待消费。具体发送过程自己查。
140.RabbitMQ怎么保证消息的稳定性?
RabbitMQ提供了持久化的机制,将内存中的消息持久化到硬盘上,即使重启RabbitMQ,消息也不会丢失。
RabbitMQ对于queue中的message的保存方式有两种方式:disc(磁盘)和ram(内存)。如果采用disc,则需要对exchange/queue/delivery mode都要设置成durable模式。Disc方式的好处是当RabbitMQ失效了,message仍然可以在重启之后恢复。而使用ram方式,RabbitMQ处理message的效率要高很多,ram和disc两种方式的效率比大概是3:1。所以如果在有其它HA手段保障的情况下,选用ram方式是可以提高消息队列的工作效率的。
如果使用ram方式,RabbitMQ能够承载的访问量则取决于可用的内存数了。RabbitMQ使用两个参数来限制使用系统的内存,避免系统被自己独占。
[{rabbit, [{vm_memory_high_watermark_paging_ratio, 0.75}, {vm_memory_high_watermark, 0.4}]}].
vm_memory_high_watermark:表示RabbitMQ使用内存的上限为系统内存的40%。也可以通过absolute参数制定具体可用的内存数。当RabbitMQ使用内存超过这个限制时,RabbitMQ 将对消息的发布者进行限流,直到内存占用回到正常值以内。
Vm_memory_high_watermark_paging_ratio:表示当RabbitMQ达到0.4*0.75=30%,系统将对queue中的内容启用paging机制,将message等内容换页到disk 中。
RabbitMQ的内存使用情况可以通过“rabbitmqctl status”或者管理插件中的Web UI查询。
各个内存条目的含义请参照:https://www.rabbitmq.com/memory-use.html
141.RabbitMQ怎么避免消息的丢失?
RabbitMQ中,消息丢失可以简单的分为两种:客户端丢失和服务端丢失。针对这两种消息丢失,RabbitMQ都给出了相应的解决方案。
引入消息确认机制
生产者P向队列中生产消息,C1和C2消费队列中的消息,默认情况下,RabbitMQ会平均的分发消费给C1C2(Round-robin dispatching),假设一个任务的执行时间非常长,在执行过程中,客户端挂了(连接断开),那么,该客户端正在处理且未完成的消息,以及分配给它还没来得及执行的消息,都将丢失。因为默认情况下,RabbitMQ分发完消息后,就会从内存中把消息删除掉。
为了解决上述问题,RabbitMQ引入了消息确认机制,当消息处理完成后,给Server端发送一个确认消息,来告诉服务端可以删除该消息了,如果连接断开的时候,Server端没有收到消费者发出的确认信息,则会把消息转发给其他保持在线的消费者。
通过消息确认机制(Acknowlege)来实现,当消费者获取消息后,会向mq发送回执ACK,告知消息已经被接收。
补充:忘记确认将引起内存泄漏
RabbitMQ只有在收到消费者确认后,才会从内存中删除消息,如果消费者忘了确认(更多情况是因为代码问题没有执行到确认的代码),将会导致内存泄漏
142.要保证消息持久化成功的条件有哪些?
声明队列必须设置持久化 durable 设置为 true.
消息推送投递模式必须设置持久化,deliveryMode 设置为 2(持久)。
消息已经到达持久化交换器。
消息已经到达持久化队列。
以上四个条件都满足才能保证消息持久化成功。
143.RabbitMQ持久化有什么缺点?
持久化的缺地就是降低了服务器的吞吐量,因为使用的是磁盘而非内存存储,从而降低了吞吐量。可尽量使用 ssd 硬盘来缓解吞吐量的问题。
144.RabbitMQ有几种广播类型?
模式1:简单模式(Simple / HelloWorld 单生产单消费)
简单的发送与接收,没有特别的处理。

模式2:工作模式(Work单发送多接收)
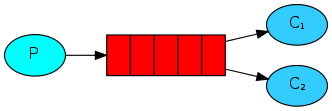
一个生产者端,多个消费者端。示例中为了保证消息发送的可靠性,不丢失消息,使消息持久化了。同时为了防止接收端在处理消息时down掉,只有在消息处理完成后才发送消息确认。
模式3:发布、订阅模式(Publish/Subscribe)
使用场景:发布、订阅模式,生产者端发送消息,多个消费者同时接收所有的消息。
模式4:路由模式(Routing)
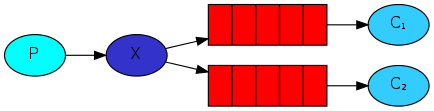
生产者按routing key发送消息,不同的消费者端按不同的routing key接收消息。
模式5:通配符(或主题)模式(Topics ,按topic发送接收)
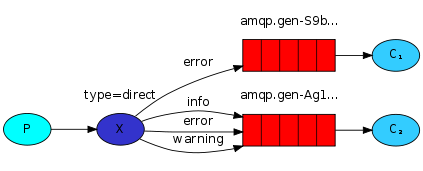
生产者端不只按固定的routing key发送消息,而是按字符串“匹配”发送,消费者端同样如此。
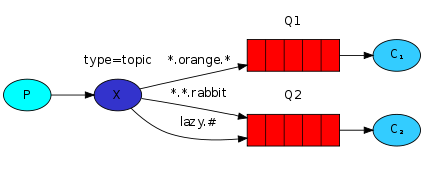
与之前的路由模式相比,它将信息的传输类型的key更加细化,以“key1.key2.keyN…”的模式来指定信息传输的key的大类型和大类型下面的小类型,让消费者端可以更加精细的确认自己想要获取的信息类型。而在消费者端,不用精确的指定具体到哪一个大类型下的小类型的key,而是可以使用类似正则表达式(但与正则表达式规则完全不同)的通配符在指定一定范围或符合某一个字符串匹配规则的key,来获取想要的信息。“通配符交换机”(Topic Exchange)将路由键和某模式进行匹配。此时队列需要绑定在一个模式上。符号“#”匹配一个或多个词,符号“*”仅匹配一个词。
145.RabbitMQ怎么实现延迟消息队列?
什么是延迟队列
延迟队列存储的对象肯定是对应的延时消息,所谓"延时消息"是指当消息被发送以后,并不想让消费者立即拿到消息,而是等待指定时间后,消费者才拿到这个消息进行消费。
场景一:在订单系统中,一个用户下单之后通常有30分钟的时间进行支付,如果30分钟之内没有支付成功,那么这个订单将进行一场处理。这是就可以使用延时队列将订单信息发送到延时队列。
场景二:用户希望通过手机远程遥控家里的智能设备在指定的时间进行工作。这时候就可以将用户指令发送到延时队列,当指令设定的时间到了再将指令推送到智能设备。
1)方法一
AMQP协议和RabbitMQ队列本身没有直接支持延迟队列功能,但是可以通过以下特性模拟出延迟队列的功能。
但是我们可以通过RabbitMQ的两个特性来曲线实现延迟队列:
特性1、Time To Live(TTL)
RabbitMQ可以针对Queue设置x-expires 或者 针对Message设置 x-message-ttl,来 控制消息的生存时间,如果超时(两者同时设置以最先到期的时间为准),则消息变为dead letter(死信)
RabbitMQ针对队列中的消息过期时间有两种方法可以设置。
A: 通过队列属性设置,队列中所有消息都有相同的过期时间。
B: 对消息进行单独设置,每条消息TTL可以不同。
如果同时使用,则消息的过期时间以两者之间TTL较小的那个数值为准。消息在队列的生存时间一旦超过设置的TTL值,就成为dead letter
特性2、Dead Letter Exchanges(DLX)
RabbitMQ的Queue可以配置x-dead-letter-exchange 和x-dead-letter-routing-key(可选)两个参数,如果队列内出现了dead letter,则按照这两个参数重新路由转发到指定的队列。
x-dead-letter-exchange:出现dead letter之后将dead letter重新发送到指定exchange
x-dead-letter-routing-key:出现dead letter之后将dead letter重新按照指定的routing-key发送
队列出现dead letter的情况有:
消息或者队列的TTL过期
队列达到最大长度
消息被消费端拒绝(basic.reject or basic.nack)并且requeue=false
综合上述两个特性,设置了TTL规则之后当消息在一个队列中变成死信时,利用DLX特性它能被重新转发到另一个Exchange或者Routing Key,这时候消息就可以重新被消费了。
2)方法二
在rabbitmq 3.5.7及以上的版本提供了一个插件(rabbitmq-delayed-message-exchange)来实现延迟队列功能。同时插件依赖Erlang/OPT 18.0及以上。
插件源码地址:
https://github.com/rabbitmq/rabbitmq-delayed-message-exchange
插件下载地址:
https://bintray.com/rabbitmq/community-plugins/rabbitmq_delayed_message_exchange
146.RabbitMQ集群有什么用?
允许消费者和生产者在RabbitMQ节点崩溃的情况下继续运行
通过增加更多的节点来扩展消息通信的吞吐量
147.RabbitMQ节点的类型有哪些?
RAM node:内存节点将所有的队列、交换机、绑定、用户、权限和vhost的元数据定义存储在内存中,好处是可以使得像交换机和队列声明等操作更加的快速。
Disk node:将元数据存储在磁盘中,单节点系统只允许磁盘类型的节点,防止重启RabbitMQ的时候,丢失系统的配置信息。
(问题说明: RabbitMQ要求在集群中至少有一个磁盘节点,所有其他节点可以是内存节点,当节点加入或者离开集群时,必须要将该变更通知到至少一个磁盘节点。如果集群中唯一的一个磁盘节点崩溃的话,集群仍然可以保持运行,但是无法进行其他操作(增删改查),直到节点恢复。
解决方案:设置两个磁盘节点,至少有一个是可用的,可以保存元数据的更改。)
148.RabbitMQ集群搭建需要注意哪些问题?
各节点之间使用“--link”连接,此属性不能忽略。
各节点使用的 erlang cookie 值必须相同,此值相当于“秘钥”的功能,用于各节点的认证。
整个集群中必须包含一个磁盘节点。
149.RabbitMQ每个节点是其他节点的完整拷贝吗?为什么?
不是,原因有以下两个:
存储空间的考虑:如果每个节点都拥有所有队列的完全拷贝,这样新增节点不但没有新增存储空间,反而增加了更多的冗余数据;
性能的考虑:如果每条消息都需要完整拷贝到每一个集群节点,那新增节点并没有提升处理消息的能力,最多是保持和单节点相同的性能甚至是更糟。
150.RabbitMQ集群中唯一一个磁盘节点崩溃了会发生什么情况?
如果唯一磁盘的磁盘节点崩溃了,不能进行以下操作:
不能创建队列
不能创建交换器
不能创建绑定
不能添加用户
不能更改权限
不能添加和删除集群节点
唯一磁盘节点崩溃了,集群是可以保持运行的,但你不能更改任何东西。
151.RabbitMQ对集群节点停止顺序有要求吗?
RabbitMQ 对集群的停止的顺序是有要求的,应该先关闭内存节点,最后再关闭磁盘节点。如果顺序恰好相反的话,可能会造成消息的丢失。
Kafka
152.kafka可以脱离Zookeeper单独使用吗?为什么?
答1:kafka 不能脱离 zookeeper 单独使用,因为 kafka 使用 zookeeper 管理和协调 kafka 的节点服务器。
除非找到一个其他的服务注册中心
答2:不可以,kafka必须要依赖一个zookeeper集群才能运行。kafka系群里面各个broker都是通过zookeeper来同步topic列表以及其它broker列表的,一旦连不上zookeeper,kafka也就无法工作。
153.Kafka有几种保留数据的策略?
:两种
Kafka Broker默认的消息保留策略是:要么保留一定时间,要么保留到消息达到一定大小的字节数。
当消息达到设置的条件上限时,旧消息就会过期并被删除,所以,在任何时刻,可用消息的总量都不会超过配置参数所指定的大小。

topic可以配置自己的保留策略,可以将消息保留到不再使用他们为止。
因为在一个大文件里查找和删除消息是很费时的事,也容易出错,所以,分区被划分为若干个片段。默认情况下,每个片段包含1G或者一周的数据,以较小的那个为准。在broker往leader分区写入消息时,如果达到片段上限,就关闭当前文件,并打开一个新文件。当前正在写入数据的片段叫活跃片段。当所有片段都被写满时,会清除下一个分区片段的数据,如果配置的是7个片段,每天打开一个新片段,就会删除一个最老的片段,循环使用所有片段。
154.kafka 同时设置了 7 天和 10G 清除数据,到第五天的时候消息达到了 10G,这个时候 kafka 将如何处理?
这个时候 kafka 会执行数据清除工作,时间和大小不论那个满足条件,都会清空数据。
155.什么情况下回导致Kafka运行变慢?
cpu 性能瓶颈
磁盘读写瓶颈
网络瓶颈
156.使用Kafka集群需要注意什么?
集群的数量不是越多越好,最好不要超过 7 个,因为节点越多,消息复制需要的时间就越长,整个群组的吞吐量就越低。
集群数量最好是单数,因为超过一半故障集群就不能用了,设置为单数容错率更高。
Zookeeper
157.Zookeeper是什么?
zookeeper 是一个分布式的,开放源码的分布式应用程序协调服务,是 google chubby 的开源实现,是 hadoop 和 hbase 的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
158.Zookeeper都有那些功能?
1)集群管理:监控节点存活状态、运行请求等。
2)主节点选举:主节点挂掉了之后可以从备用的节点开始新一轮选主,主节点选举说的就是这个选举的过程,使用 zookeeper 可以协助完成这个过程。
3)分布式锁:zookeeper 提供两种锁:独占锁、共享锁。独占锁即一次只能有一个线程使用资源,共享锁是读锁共享,读写互斥,即可以有多线线程同时读同一个资源,如果要使用写锁也只能有一个线程使用。zookeeper可以对分布式锁进行控制。
4)命名服务:在分布式系统中,通过使用命名服务,客户端应用能够根据指定名字来获取资源或服务的地址,提供者等信息。
借鉴:
数据发布与订阅(配置中心)
负载均衡
命名服务(Naming Service)
分布式通知/协调
集群管理与Master选举
分布式锁
分布式队列
159.Zookeeper有几种部署模式?
zookeeper 有三种部署模式:
单机部署:一台集群上运行;
集群部署:多台集群运行;
伪集群部署:一台集群启动多个 zookeeper 实例运行。
160.Zookeeper怎么保证主从节点的状态同步?
zookeeper 的核心是原子广播,这个机制保证了各个 server 之间的同步。实现这个机制的协议叫做 zab 协议。 zab 协议有两种模式,分别是恢复模式(选主)和广播模式(同步)。当服务启动或者在领导者崩溃后,zab 就进入了恢复模式,当领导者被选举出来,且大多数 server 完成了和 leader 的状态同步以后,恢复模式就结束了。状态同步保证了 leader 和 server 具有相同的系统状态。
161.集群中为甚什么要有主节点?
在分布式环境中,有些业务逻辑只需要集群中的某一台机器进行执行,其他的机器可以共享这个结果,这样可以大大减少重复计算,提高性能,所以就需要主节点。
162.集群中有3台服务器,其中一个节点宕机,这个时候Zookeeper还可以使用吗?
可以继续使用,单数服务器只要没超过一半的服务器宕机就可以继续使用。
163.说一下Zookeeper的通知机制?
客户端端会对某个 znode 建立一个 watcher 事件,当该 znode 发生变化时,这些客户端会收到 zookeeper 的通知,然后客户端可以根据 znode 变化来做出业务上的改变。
Mysql
164.数据库的三范式是什么?
第一范式是最基本的范式。如果数据库表中的所有字段值都是不可分解的原子值,就说明该数据库满足第一范式。
第二范式在第一范式的基础上更进一层,第二范式需要确保数据库表中每一列都和主键相关,而不能只与主键的某一部分相关(主要针对联合主键而言)。也就是说在一个数据库表中,一个表中只能保存一种数据,不可以把多种数据保存在同一张数据库表中。
第三范式需要确保数据表中的每一列数据都和主键直接相关,而不能间接相关。
165. 一张自增表里面总共有 7 条数据,删除了最后 2 条数据,重启 mysql 数据库,又插入了一条数据,此时 id 是几?
表类型如果是 MyISAM ,那 id 就是 8。
表类型如果是 InnoDB,那 id 就是 6。
InnoDB 表只会把自增主键的最大 id 记录在内存中,所以重启之后会导致最大 id 丢失。
166. 如何获取当前数据库版本?
使用 select version() 获取当前 MySQL 数据库版本。
167.说一下 ACID 是什么?
Atomicity(原子性):一个事务(transaction)中的所有操作,或者全部完成,或者全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被恢复(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。即,事务不可分割、不可约简。
Consistency(一致性):在事务开始之前和事务结束以后,数据库的完整性没有被破坏。这表示写入的资料必须完全符合所有的预设约束、触发器、级联回滚等。
Isolation(隔离性):数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。事务隔离分为不同级别,包括读未提交(Read uncommitted)、读提交(read committed)、可重复读(repeatable read)和串行化(Serializable)。
Durability(持久性):事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
168. char 和 varchar 的区别是什么?
char(n) :固定长度类型,比如订阅 char(10),当你输入"abc"三个字符的时候,它们占的空间还是 10 个字节,其他 7 个是空字节。
chat 优点:效率高;缺点:占用空间;适用场景:存储密码的 md5 值,固定长度的,使用 char 非常合适。
varchar(n) :可变长度,存储的值是每个值占用的字节再加上一个用来记录其长度的字节的长度。
所以,从空间上考虑 varcahr 比较合适;从效率上考虑 char 比较合适,二者使用需要权衡。
169. float 和 double 的区别是什么?
float 最多可以存储 8 位的十进制数,并在内存中占 4 字节。
double 最可可以存储 16 位的十进制数,并在内存中占 8 字节。
170. mysql 的内连接、左连接、右连接有什么区别?
内连接关键字:inner join;左连接:left join;右连接:right join。
内连接是把匹配的关联数据显示出来;左连接是左边的表全部显示出来,右边的表显示出符合条件的数据;右连接正好相反。
171. mysql 索引是怎么实现的?
索引是满足某种特定查找算法的数据结构,而这些数据结构会以某种方式指向数据,从而实现高效查找数据。
具体来说 MySQL 中的索引,不同的数据引擎实现有所不同,但目前主流的数据库引擎的索引都是 B+ 树实现的,B+ 树的搜索效率,可以到达二分法的性能,找到数据区域之后就找到了完整的数据结构了,所有索引的性能也是更好的。
172. 怎么验证 mysql 的索引是否满足需求?
使用 explain 查看 SQL 是如何执行查询语句的,从而分析你的索引是否满足需求。
explain 语法:explain select * from table where type=1。
173. 说一下数据库的事务隔离?
MySQL 的事务隔离是在 MySQL. ini 配置文件里添加的,在文件的最后添加:transaction-isolation = REPEATABLE-READ
可用的配置值:READ-UNCOMMITTED、READ-COMMITTED、REPEATABLE-READ、SERIALIZABLE。
READ-UNCOMMITTED:未提交读,最低隔离级别、事务未提交前,就可被其他事务读取(会出现幻读、脏读、不可重复读)。
READ-COMMITTED:提交读,一个事务提交后才能被其他事务读取到(会造成幻读、不可重复读)。
REPEATABLE-READ:可重复读,默认级别,保证多次读取同一个数据时,其值都和事务开始时候的内容是一致,禁止读取到别的事务未提交的数据(会造成幻读)。
SERIALIZABLE:序列化,代价最高最可靠的隔离级别,该隔离级别能防止脏读、不可重复读、幻读。
脏读 :表示一个事务能够读取另一个事务中还未提交的数据。比如,某个事务尝试插入记录 A,此时该事务还未提交,然后另一个事务尝试读取到了记录 A。
不可重复读 :是指在一个事务内,多次读同一数据。
幻读 :指同一个事务内多次查询返回的结果集不一样。比如同一个事务 A 第一次查询时候有 n 条记录,但是第二次同等条件下查询却有 n+1 条记录,这就好像产生了幻觉。发生幻读的原因也是另外一个事务新增或者删除或者修改了第一个事务结果集里面的数据,同一个记录的数据内容被修改了,所有数据行的记录就变多或者变少了。
174. 说一下 mysql 常用的引擎?
InnoDB 引擎:InnoDB 引擎提供了对数据库 acid 事务的支持,并且还提供了行级锁和外键的约束,它的设计的目标就是处理大数据容量的数据库系统。MySQL 运行的时候,InnoDB 会在内存中建立缓冲池,用于缓冲数据和索引。但是该引擎是不支持全文搜索,同时启动也比较的慢,它是不会保存表的行数的,所以当进行 select count(*) from table 指令的时候,需要进行扫描全表。由于锁的粒度小,写操作是不会锁定全表的,所以在并发度较高的场景下使用会提升效率的。
MyIASM 引擎:MySQL 的默认引擎,但不提供事务的支持,也不支持行级锁和外键。因此当执行插入和更新语句时,即执行写操作的时候需要锁定这个表,所以会导致效率会降低。不过和 InnoDB 不同的是,MyIASM 引擎是保存了表的行数,于是当进行 select count(*) from table 语句时,可以直接的读取已经保存的值而不需要进行扫描全表。所以,如果表的读操作远远多于写操作时,并且不需要事务的支持的,可以将 MyIASM 作为数据库引擎的首选。
175. 说一下 mysql 的行锁和表锁?
MyISAM 只支持表锁,InnoDB 支持表锁和行锁,默认为行锁。
表级锁:开销小,加锁快,不会出现死锁。锁定粒度大,发生锁冲突的概率最高,并发量最低。
行级锁:开销大,加锁慢,会出现死锁。锁力度小,发生锁冲突的概率小,并发度最高。
176. 说一下乐观锁和悲观锁?
乐观锁:每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在提交更新的时候会判断一下在此期间别人有没有去更新这个数据。
悲观锁:每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会阻止,直到这个锁被释放。
数据库的乐观锁需要自己实现,在表里面添加一个 version 字段,每次修改成功值加 1,这样每次修改的时候先对比一下,自己拥有的 version 和数据库现在的 version 是否一致,如果不一致就不修改,这样就实现了乐观锁。
177. mysql 问题排查都有哪些手段?
使用 show processlist 命令查看当前所有连接信息。
使用 explain 命令查询 SQL 语句执行计划。
开启慢查询日志,查看慢查询的 SQL。
178. 如何做 mysql 的性能优化?
为搜索字段创建索引。
避免使用 select *,列出需要查询的字段。
垂直分割分表。
选择正确的存储引擎。
Redis
179.redis 是什么?都有哪些使用场景?
Redis是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。
Redis 使用场景:
数据高并发的读写
海量数据的读写
对扩展性要求高的数据
180. redis 有哪些功能?
数据缓存功能
分布式锁的功能
支持数据持久化
支持事务
支持消息队列
181. redis 和 memecache 有什么区别?
memcached所有的值均是简单的字符串,redis作为其替代者,支持更为丰富的数据类型
redis的速度比memcached快很多
redis可以持久化其数据
182. redis 为什么是单线程的?
因为 cpu 不是 Redis 的瓶颈,Redis 的瓶颈最有可能是机器内存或者网络带宽。既然单线程容易实现,而且 cpu 又不会成为瓶颈,那就顺理成章地采用单线程的方案了。
关于 Redis 的性能,官方网站也有,普通笔记本轻松处理每秒几十万的请求。
而且单线程并不代表就慢 nginx 和 nodejs 也都是高性能单线程的代表。
183. 什么是缓存穿透?怎么解决?
缓存穿透:指查询一个一定不存在的数据,由于缓存是不命中时需要从数据库查询,查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到数据库去查询,造成缓存穿透。
解决方案:最简单粗暴的方法如果一个查询返回的数据为空(不管是数据不存在,还是系统故障),我们就把这个空结果进行缓存,但它的过期时间会很短,最长不超过五分钟。
184. redis 支持的数据类型有哪些?
string、list、hash、set、zset。
185. redis 支持的 java 客户端都有哪些?
Redisson、Jedis、lettuce等等,官方推荐使用Redisson。
186. jedis 和 redisson 有哪些区别?
Jedis是Redis的Java实现的客户端,其API提供了比较全面的Redis命令的支持。
Redisson实现了分布式和可扩展的Java数据结构,和Jedis相比,功能较为简单,不支持字符串操作,不支持排序、事务、管道、分区等Redis特性。Redisson的宗旨是促进使用者对Redis的关注分离,从而让使用者能够将精力更集中地放在处理业务逻辑上。
187. 怎么保证缓存和数据库数据的一致性?
合理设置缓存的过期时间。
新增、更改、删除数据库操作时同步更新 Redis,可以使用事物机制来保证数据的一致性。
188. redis 持久化有几种方式?
Redis 的持久化有两种方式,或者说有两种策略:
RDB(Redis Database):指定的时间间隔能对你的数据进行快照存储。
AOF(Append Only File):每一个收到的写命令都通过write函数追加到文件中。
189. redis 怎么实现分布式锁?
Redis 分布式锁其实就是在系统里面占一个“坑”,其他程序也要占“坑”的时候,占用成功了就可以继续执行,失败了就只能放弃或稍后重试。
占坑一般使用 setnx(set if not exists)指令,只允许被一个程序占有,使用完调用 del 释放锁。
190. redis 分布式锁有什么缺陷?
Redis 分布式锁不能解决超时的问题,分布式锁有一个超时时间,程序的执行如果超出了锁的超时时间就会出现问题。
191. redis 如何做内存优化?
尽可能使用散列表(hashes),散列表(是说散列表里面存储的数少)使用的内存非常小,所以你应该尽可能的将你的数据模型抽象到一个散列表里面。
比如你的web系统中有一个用户对象,不要为这个用户的名称,姓氏,邮箱,密码设置单独的key,而是应该把这个用户的所有信息存储到一张散列表里面。
192. redis 淘汰策略有哪些?
volatile-lru:从已设置过期时间的数据集(server. db[i]. expires)中挑选最近最少使用的数据淘汰。
volatile-ttl:从已设置过期时间的数据集(server. db[i]. expires)中挑选将要过期的数据淘汰。
volatile-random:从已设置过期时间的数据集(server. db[i]. expires)中任意选择数据淘汰。
allkeys-lru:从数据集(server. db[i]. dict)中挑选最近最少使用的数据淘汰。
allkeys-random:从数据集(server. db[i]. dict)中任意选择数据淘汰。
no-enviction(驱逐):禁止驱逐数据。
193. redis 常见的性能问题有哪些?该如何解决?
主服务器写内存快照,会阻塞主线程的工作,当快照比较大时对性能影响是非常大的,会间断性暂停服务,所以主服务器最好不要写内存快照。
Redis 主从复制的性能问题,为了主从复制的速度和连接的稳定性,主从库最好在同一个局域网内。
194.说一下 jvm 的主要组成部分?及其作用?
类加载器(ClassLoader)
运行时数据区(Runtime Data Area)
执行引擎(Execution Engine)
本地库接口(Native Interface)
组件的作用: 首先通过类加载器(ClassLoader)会把 Java 代码转换成字节码,运行时数据区(Runtime Data Area)再把字节码加载到内存中,而字节码文件只是 JVM 的一套指令集规范,并不能直接交个底层操作系统去执行,因此需要特定的命令解析器执行引擎(Execution Engine),将字节码翻译成底层系统指令,再交由 CPU 去执行,而这个过程中需要调用其他语言的本地库接口(Native Interface)来实现整个程序的功能。
195. 说一下 jvm 运行时数据区?
程序计数器
虚拟机栈
本地方法栈
堆
方法区
有的区域随着虚拟机进程的启动而存在,有的区域则依赖用户进程的启动和结束而创建和销毁。
196.说一下堆栈的区别?
栈内存存储的是局部变量而堆内存存储的是实体;
栈内存的更新速度要快于堆内存,因为局部变量的生命周期很短;
栈内存存放的变量生命周期一旦结束就会被释放,而堆内存存放的实体会被垃圾回收机制不定时的回收。
197.队列和栈是什么?有什么区别?
队列和栈都是被用来预存储数据的。
队列允许先进先出检索元素,但也有例外的情况,Deque 接口允许从两端检索元素。
栈和队列很相似,但它运行对元素进行后进先出进行检索。
198. 什么是双亲委派模型?
在介绍双亲委派模型之前先说下类加载器。对于任意一个类,都需要由加载它的类加载器和这个类本身一同确立在 JVM 中的唯一性,每一个类加载器,都有一个独立的类名称空间。类加载器就是根据指定全限定名称将 class 文件加载到 JVM 内存,然后再转化为 class 对象。
类加载器分类:
启动类加载器(Bootstrap ClassLoader),是虚拟机自身的一部分,用来加载Java_HOME/lib/目录中的,或者被 -Xbootclasspath 参数所指定的路径中并且被虚拟机识别的类库;
其他类加载器:
扩展类加载器(Extension ClassLoader):负责加载<java_home style=“box-sizing: border-box; -webkit-tap-highlight-color: transparent; text-size-adjust: none; -webkit-font-smoothing: antialiased; outline: 0px !important;”>\lib\ext目录或Java. ext. dirs系统变量指定的路径中的所有类库;</java_home>
应用程序类加载器(Application ClassLoader)。负责加载用户类路径(classpath)上的指定类库,我们可以直接使用这个类加载器。一般情况,如果我们没有自定义类加载器默认就是用这个加载器。
双亲委派模型:如果一个类加载器收到了类加载的请求,它首先不会自己去加载这个类,而是把这个请求委派给父类加载器去完成,每一层的类加载器都是如此,这样所有的加载请求都会被传送到顶层的启动类加载器中,只有当父加载无法完成加载请求(它的搜索范围中没找到所需的类)时,子加载器才会尝试去加载类。
199. 说一下类加载的执行过程?
类加载分为以下 5 个步骤:
加载:根据查找路径找到相应的 class 文件然后导入;
检查:检查加载的 class 文件的正确性;
准备:给类中的静态变量分配内存空间;
解析:虚拟机将常量池中的符号引用替换成直接引用的过程。符号引用就理解为一个标示,而在直接引用直接指向内存中的地址;
初始化:对静态变量和静态代码块执行初始化工作。
200. 怎么判断对象是否可以被回收?
一般有两种方法来判断:
引用计数器:为每个对象创建一个引用计数,有对象引用时计数器 +1,引用被释放时计数 -1,当计数器为 0 时就可以被回收。它有一个缺点不能解决循环引用的问题;
可达性分析:从 GC Roots 开始向下搜索,搜索所走过的路径称为引用链。当一个对象到 GC Roots 没有任何引用链相连时,则证明此对象是可以被回收的。
201. java 中都有哪些引用类型?
强引用
软引用
弱引用
虚引用(幽灵引用/幻影引用)
202. 说一下 jvm 有哪些垃圾回收算法?
标记-清除算法
标记-整理算法
复制算法
分代算法
203. 说一下 jvm 有哪些垃圾回收器?
Serial:最早的单线程串行垃圾回收器。
Serial Old:Serial 垃圾回收器的老年版本,同样也是单线程的,可以作为 CMS 垃圾回收器的备选预案。
ParNew:是 Serial 的多线程版本。
Parallel 和 ParNew 收集器类似是多线程的,但 Parallel 是吞吐量优先的收集器,可以牺牲等待时间换取系统的吞吐量。
Parallel Old 是 Parallel 老生代版本,Parallel 使用的是复制的内存回收算法,Parallel Old 使用的是标记-整理的内存回收算法。
CMS:一种以获得最短停顿时间为目标的收集器,非常适用 B/S 系统。
G1:一种兼顾吞吐量和停顿时间的 GC 实现,是 JDK 9 以后的默认 GC 选项。
204. 详细介绍一下 CMS 垃圾回收器?
CMS 是英文 Concurrent Mark-Sweep 的简称,是以牺牲吞吐量为代价来获得最短回收停顿时间的垃圾回收器。对于要求服务器响应速度的应用上,这种垃圾回收器非常适合。在启动 JVM 的参数加上“-XX:+UseConcMarkSweepGC”来指定使用 CMS 垃圾回收器。
CMS 使用的是标记-清除的算法实现的,所以在 gc 的时候回产生大量的内存碎片,当剩余内存不能满足程序运行要求时,系统将会出现 Concurrent Mode Failure,临时 CMS 会采用 Serial Old 回收器进行垃圾清除,此时的性能将会被降低。
205.新生代垃圾回收器和老生代垃圾回收器都有哪些?有什么区别?
新生代回收器:Serial、ParNew、Parallel Scavenge
老年代回收器:Serial Old、Parallel Old、CMS
整堆回收器:G1
新生代垃圾回收器一般采用的是复制算法,复制算法的优点是效率高,缺点是内存利用率低;老年代回收器一般采用的是标记-整理的算法进行垃圾回收。
206. 简述分代垃圾回收器是怎么工作的?
分代回收器有两个分区:老生代和新生代,新生代默认的空间占比总空间的 1/3,老生代的默认占比是 2/3。
新生代使用的是复制算法,新生代里有 3 个分区:Eden、To Survivor、From Survivor,它们的默认占比是 8:1:1,它的执行流程如下:
把 Eden + From Survivor 存活的对象放入 To Survivor 区;
清空 Eden 和 From Survivor 分区;
From Survivor 和 To Survivor 分区交换,From Survivor 变 To Survivor,To Survivor 变 From Survivor。
每次在 From Survivor 到 To Survivor 移动时都存活的对象,年龄就 +1,当年龄到达 15(默认配置是 15)时,升级为老生代。大对象也会直接进入老生代。
老生代当空间占用到达某个值之后就会触发全局垃圾收回,一般使用标记整理的执行算法。以上这些循环往复就构成了整个分代垃圾回收的整体执行流程。
207. 说一下 jvm 调优的工具?
JDK 自带了很多监控工具,都位于 JDK 的 bin 目录下,其中最常用的是 jconsole 和 jvisualvm 这两款视图监控工具。
jconsole:用于对 JVM 中的内存、线程和类等进行监控;
jvisualvm:JDK 自带的全能分析工具,可以分析:内存快照、线程快照、程序死锁、监控内存的变化、gc 变化等。
208. 常用的 jvm 调优的参数都有哪些?
-Xms2g:初始化推大小为 2g;
-Xmx2g:堆最大内存为 2g;
-XX:NewRatio=4:设置年轻的和老年代的内存比例为 1:4;
-XX:SurvivorRatio=8:设置新生代 Eden 和 Survivor 比例为 8:2;
–XX:+UseParNewGC:指定使用 ParNew + Serial Old 垃圾回收器组合;
-XX:+UseParallelOldGC:指定使用 ParNew + ParNew Old 垃圾回收器组合;
-XX:+UseConcMarkSweepGC:指定使用 CMS + Serial Old 垃圾回收器组合;
-XX:+PrintGC:开启打印 gc 信息;
-XX:+PrintGCDetails:打印 gc 详细信息。















 98万+
98万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









