









前言:在了解这玩意儿之前我一直以为数据库的索引原理类似于缓存的key-value存储(原谅我可能本科数据库学习的时候确实没注重这一块),了解之后才发现数据结构的伟大。当然有数据结构基础的同学(二叉树和排序那两章就够了),看数据库的索引会简单到可怕,没有的话那就可能有些困难了。
知识点导航:从浅入深分别是二叉树—>二叉排序树—>B树—>B+树—>数据库的索引,其中B树到B+树需要了解一下数据的链式结构。
在这里二叉树和二叉排序树就不说了,直接从B树开始:
B 树可以看作是对2-3查找树的一种扩展,即他允许每个节点有M-1个子节点。
- 根节点至少有两个子节点
- 每个节点有M-1个key,并且以升序排列
- 位于M-1和M key的子节点的值位于M-1 和M key对应的Value之间
- 其它节点至少有M/2个子节点
下图是一个M=4 阶的B树:
B+树是对B树的一种变形树,它与B树的差异在于:
- 有k个子结点的结点必然有k个关键码;
- 非叶结点仅具有索引作用,跟记录有关的信息均存放在叶结点中。
- 树的所有叶结点构成一个有序链表,可以按照关键码排序的次序遍历全部记录。
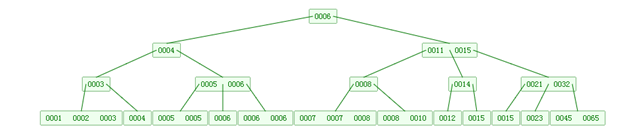
如下图,是一个B+树:

便于理解下面是B树和B+树的创建动画:
6 10 4 14 5 11 15 3 2 12 1 7 8 8 6 3 6 21 5 15 15 6 32 23 45 65 7 8 6 5 4
下图是B树的插入动画:

下图是B+树的插入动画:

由上图可以看出B+树相对于B树而言在底部多了一层链式结构,从数据结构的角度出发,B+树底部的链式结构存放了全部的数据,其上的叶子节点则类似于块查找中的索引块部分(可以理解为目录),在目录中找到数据的区间在往下继续查找,每次都必须要查找到B+树的最底层部分。而在B树中它的查找则更类似于二叉排序的查找,B树的叶子节点存放的就是其正式数据,每次找到数据后可以马上返回,不需要查找到最底层,。
举个例子在上面两张图中查找0005,在B树中找到第二层就ok,查找长度为2,而在B+树中则需要找到最底层的链式结构中,查找长度为3。
在数据库的索引中B和B+树的区别在于,B+树的非叶子结点只包含导航信息,不包含实际的值,所有的叶子结点和相连的节点使用链表相连,便于区间查找和遍历。B树和B+树各有各的优点,B树优势在于每个节点都包含key和value,因此经常访问的元素可能离根节点更近,不需要查询到最底层,因此访问也更迅速。B+ 树的优点在于由于B+树在内部节点上不包含数据信息,因此在内存页中能够存放更多的key, 数据存放的更加紧密,具有更好的空间局部性,因此访问叶子节点上关联的数据也具有更好的缓存命中率。B+树的叶子结点都是相链的,因此对整棵树的便利只需要一次线性遍历叶子结点即可。而且由于数据顺序排列并且相连,所以便于区间查找和搜索。而B树则需要进行每一层的递归遍历。相邻的元素可能在内存中不相邻,所以缓存命中性没有B+树好。
总结:数据库的索引每次在创建的时候会根据索引字段和以上的步骤来创建B/B+树,之后每次查询都是根据这支B/B+树来查询数值。















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









