







 文章讲述了在CEPH集群中,由于坏盘导致的PGsscrub延迟问题。通过调整osd_max_scrubs和osd_scrub_load_threshold参数,可以提高scrub操作的并行性,加快数据一致性检查速度。然而,增加并行数可能对网络带宽和磁盘利用率产生影响,建议使用10GE以上交换机,并谨慎设置osd_max_scrubs参数,以防止磁盘过度使用。
文章讲述了在CEPH集群中,由于坏盘导致的PGsscrub延迟问题。通过调整osd_max_scrubs和osd_scrub_load_threshold参数,可以提高scrub操作的并行性,加快数据一致性检查速度。然而,增加并行数可能对网络带宽和磁盘利用率产生影响,建议使用10GE以上交换机,并谨慎设置osd_max_scrubs参数,以防止磁盘过度使用。
背景:
ceph集群,近期刚好有块坏盘,在洗刷数据的时候比较慢
CEPH会定期(默认每个星期一次)对所有的PGs进行scrub,即通过检测PG中各个osds中数据是否一致来保证数据的安全。
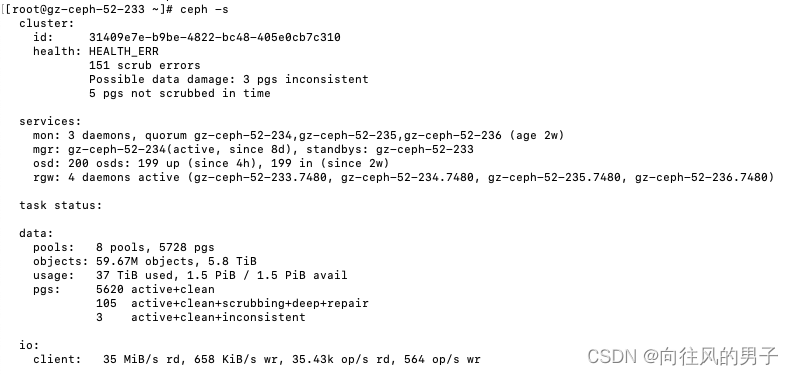
近期坏盘没更换,集群检查到坏盘,进行数据修复后,出现了大量的PGs不能及时进行scrub,甚至有些PGs数据不一致,导致CEPH系统报警,如下所示:

此时,需要提高对PGs的scrub速度。默认情况下一个OSD近能同时进行一个scrub操作且仅当主机低于0.5时才进行scrub操作。我运维的CEPH系统一个PG对应10个OSDs,每个OSD仅能同时进行一个scrub操作,导致大量scrub操作需要等待,而同时进行的scrub操作数量一般为8个。因此需要在各台存储服务器上对其OSDs进行参数修改,来提高scrub速度。
osd_max_scrubs参数用于设置单个OSD同时进行的最大scrub操作数量;osd_scrub_load参数设置负载阈值。主要修改以上两个参数来提高scrub速度,其默认值为1和0.5。
修改所有的OSD的osd_max_scrubs参数:
ceph tell osd.* injectargs --osd_max_scrubs=5 --osd_scrub_load_threshold=5
#查看
ceph daemon osd.0 config show | grep osd_max_scrubs
修改后的效果:速度明显快了
总结:
-提高scrub的并行数可能对CEPH集群内网的网速要求较高,推荐使用10GE以上交换机。
-scrub的并行数,会导致一个OSD对应的硬盘同时并行读取的操作数量较高,当导致磁盘100%被使用时,可能磁盘的利用效率并不高,因此不推荐将 osd_max_scrubs参数调节到10以上。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









