








介绍
本文是分析Elasticsearch系列文章中的一篇,是一个译文。共有三篇,每篇讲解部分Elasticsearch的实现原理。
在翻译的过程中,也需要查看对应部分的源码,来加深对实现原理的理解。但这里并没有对源码进行分析,源码的分析放到后面的系列文章进行介绍。
本文介绍了Elasticsearch的以下原理:
- 是Master/Slave架构,还是Master-less架构?
- 存储模型是什么?
- 写入操作是如何工作的?
- 读操作是如何工作的?
- 搜索结果如何相关?
Elasticsearch介绍
Elasticsearch的index
Elasticsearch的索引(index)是用于组织数据的逻辑命名空间(如数据库)。Elasticsearch的索引有一个或多个分片(shard)(默认为5)。分片是实际存储数据的Lucene索引,它本身就是一个搜索引擎。每个分片可以有零个或多个副本(replicas)(默认为1)。Elasticsearch索引还具有“类型”(如数据库中的表),允许您在索引中对数据进行逻辑分区。Elasticsearch索引中给定“类型”中的所有文档(documents)具有相同的属性(如表的模式)。

图a显示了一个由三个主分片组成的Elasticsearch集群,每个主分片分别有一个副本。所有这些分片一起形成一个Elasticsearch索引,每个分片是Lucene索引本身。
图b演示了Elasticsearch索引,分片,Lucene索引和文档(document)之间的逻辑关系。
类比关系数据库术语
- Elasticsearch Index ~ Database
- Types ~ Tables
- Mapping ~ Schema
Elasticsearch集群的节点类型
Elasticsearch的一个实例是一个节点,一组节点形成一个集群。Elasticsearch集群中的节点可以通过三种不同的方式进行配置:
Master节点
- Master节点控制Elasticsearch集群,并负责在集群范围内创建/删除索引,跟踪哪些节点是集群的一部分,并将分片分配给这些节点。主节点一次处理一个集群状态,并将状态广播到所有其他节点,这些节点需要响应并确认主节点的信息。
- 在elasticsearch.yml中,将nodes.master属性设置为true(默认),可以将节点配置为有资格成为主节点的节点。
- 对于大型生产集群,建议拥有一个专用主节点来控制集群,并且不服务任何用户请求。
Data节点
- 数据节点用来保存数据和倒排索引。默认情况下,每个节点都配置为一个data节点,并且在elasticsearch.yml中将属性node.data设置为true。如果您想要一个专用的master节点,那么将node.data属性更改为false。
Client节点
如果将node.master和node.data设置为false,则将节点配置为客户端节点,并充当负载平衡器,将传入的请求路由到集群中的不同节点。
若你连接的是作为客户端的节点,该节点称为协调节点(coordinating node)。协调节点将客户机请求路由到集群中对应分片所在的节点。对于读取请求,协调节点每次选择不同的分片来提供请求以平衡负载。
在我们开始审查发送到协调节点的CRUD请求如何通过集群传播并由引擎执行之前,让我们看看Elasticsearch如何在内部存储数据,以低延迟为全文搜索提供结果。
存储模型
Elasticsearch使用Apache Lucene,它是由Java编写的全文搜索库,由Doug Cutting(Apache Hadoop的创建者)内部开发,它使用称为倒排索引的数据结构,用于提供低延迟搜索结果。
文档(document)是Elasticsearch中的数据单位,并通过对文档中的术语进行标记来创建倒排索引,创建所有唯一术语的排序列表,并将文档列表与可以找到该词的位置相关联。
它非常类似于一本书背面的索引,其中包含书中的所有独特的单词和可以找到该单词的页面列表。当我们说一个文档被索引时,我们引用倒排索引。我们来看看下面两个文档的倒排索引如何看待:

如果我们想要找到包含术语“insight”的文档,我们可以扫描倒排的索引(在哪里排序),找到“insight”这个词,并返回包含这个单词的文档ID,这在这种情况下将是文档1和Doc 2号文件。
为了提高可搜索性(例如,为小写字母和小写字提供相同的结果),首先分析文档并对其进行索引。
分析由两部分组成:
- 将句子标记成单词
- 将单词规范化为标准表单
默认情况下,Elasticsearch使用标准分析器 - 标准标记器(Standard tokenizer),用于在单词边界上分割单词
- 小写令牌过滤器(Lowercase token filter)将单词转换为小写
还有许多其他分析仪可用,您可以在文档中阅读它们。
注意:标准分析仪也使用停止令牌过滤器,但默认情况下禁用。
实现原理分析
write(写)/create(创建)操作实现原理
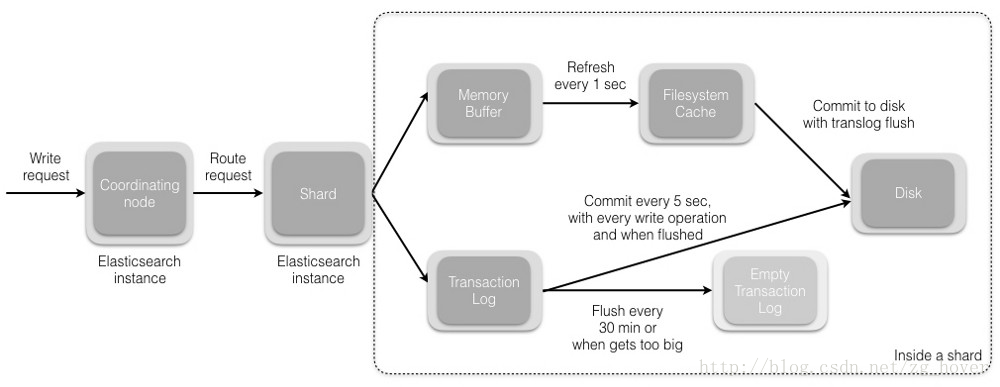
当您向协调节点发送请求以索引新文档时,将执行以下操作:
所有在Elasticsearch集群中的节点都包含:有关哪个分片存在于哪个节点上的元数据。协调节点(coordinating node)使用文档ID(默认)将文档路由到对应的分片。Elasticsearch将文档ID以murmur3作为散列函数进行散列,并通过索引中的主分片数量进行取模运算,以确定文档应被索引到哪个分片。
shard = hash(document_id) % (num_of_primary_shards)当节点接收到来自协调节点的请求时,请求被写入到translog(我们将在后续的post中间讲解translog),并将该文档添加到内存缓冲区。如果请求在主分片上成功,则请求将并行发送到副本分片。只有在所有主分片和副本分片上的translog被fsync’ed后,客户端才会收到该请求成功的确认。
- 内存缓冲区以固定的间隔刷新(默认为1秒),并将内容写入文件系统缓存中的新段。此分段的内容更尚未被fsync’ed(未被写入文件系统),分段是打开的,内容可用于搜索。
- translog被清空,并且文件系统缓存每隔30分钟进行一次fsync,或者当translog变得太大时进行一次fsync。这个过程在Elasticsearch中称为flush。在刷新过程中,内存缓冲区被清除,内容被写入新的文件分段(segment)。当文件分段被fsync’ed并刷新到磁盘,会创建一个新的提交点(其实就是会更新文件偏移量,文件系统会自动做这个操作)。旧的translog被删除,一个新的开始。
- 下图显示了写入请求和数据流程:
Update和Delete实现原理
删除和更新操作也是写操作。但是,Elasticsearch中的文档是不可变的(immutable),因此不能删除或修改。那么,如何删除/更新文档呢?
磁盘上的每个分段(segment)都有一个.del文件与它相关联。当发送删除请求时,该文档未被真正删除,而是在.del文件中标记为已删除。此文档可能仍然能被搜索到,但会从结果中过滤掉。当分段合并时(我们将在后续的帖子中包括段合并),在.del文件中标记为已删除的文档不会被包括在新的合并段中。
现在,我们来看看更新是如何工作的。创建新文档时,Elasticsearch将为该文档分配一个版本号。对文档的每次更改都会产生一个新的版本号。当执行更新时,旧版本在.del文件中被标记为已删除,并且新版本在新的分段中编入索引。旧版本可能仍然与搜索查询匹配,但是从结果中将其过滤掉。
indexed/updated文档后,我们希望执行搜索请求。我们来看看如何在Elasticsearch中执行搜索请求。
Read的实现原理
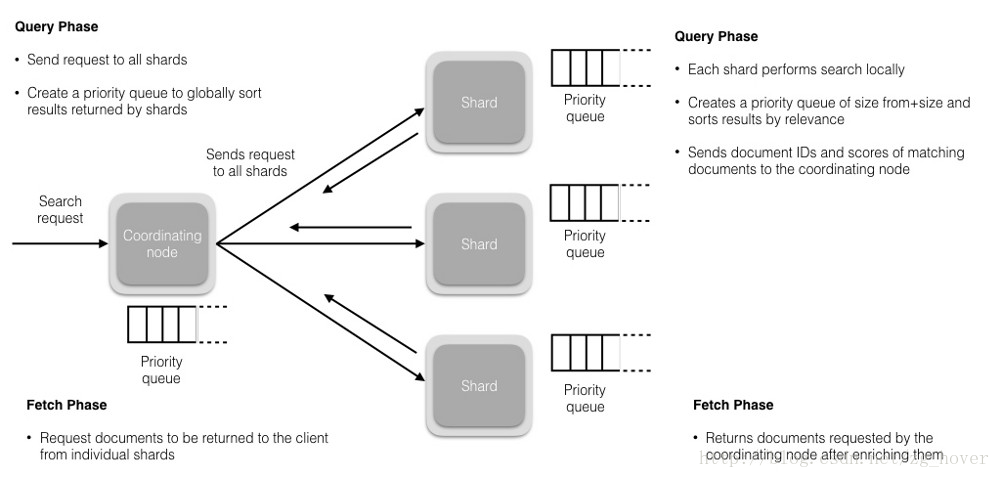
读操作由两个阶段组成:
- 查询阶段(Query Phase)
- 获取阶段(Fetch Phase)
查询阶段(Query Phase)
在此阶段,协调节点将搜索请求路由到索引(index)中的所有分片(shards)(包括:主要或副本)。分片独立执行搜索,并根据相关性分数创建一个优先级排序结果(稍后我们将介绍相关性分数)。所有分片将匹配的文档和相关分数的文档ID返回给协调节点。协调节点创建一个新的优先级队列,并对全局结果进行排序。可以有很多文档匹配结果,但默认情况下,每个分片将前10个结果发送到协调节点,协调创建优先级队列,从所有分片中分选结果并返回前10个匹配。
获取阶段(Fetch Phase)
在协调节点对所有结果进行排序,已生成全局排序的文档列表后,它将从所有分片请求原始文档。
所有的分片都会丰富文档并将其返回到协调节点。
如上所述,搜索结果按相关性排序。我们来回顾一下相关性的定义。
搜索相关性(Search Relevance)
相关性由Elasticsearch给予搜索结果中返回的每个文档的分数确定。用于评分的默认算法为tf / idf(术语频率/逆文档频率)。该术语频率测量术语出现在文档中的次数(更高频率=更高的相关性),逆文档频率测量术语在整个索引中出现的频率占索引中文档总数的百分比(更高的频率
==较少的相关性)。最终得分是tf-idf分数与其他因素(如词语邻近度(短语查询)),术语相似度(用于模糊查询)等的组合。
参考
https://blog.insightdatascience.com/anatomy-of-an-elasticsearch-cluster-part-i-7ac9a13b05db
https://blog.insightdatascience.com/anatomy-of-an-elasticsearch-cluster-part-ii-6db4e821b571
https://blog.insightdatascience.com/anatomy-of-an-elasticsearch-cluster-part-iii-8bb6ac84488d
https://www.elastic.co/blog/index-vs-type















 716
716

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









