






今天接到一个优化性能的任务,把一个过滤非汉字字符的算法性能提高一下,原来方法使用了如下方法:
if (Character.UnicodeBlock.of(c) == Character.UnicodeBlock.CJK_UNIFIED_IDEOGRAPHS)
这个方法内部使用了一个二分查找的算法在一个100多个元素的数组中查找对应的UnicodeBlock,对于一个50K的html文件说,性能非常差。
经过查看发现,其实中文字符的Unicode区间只有以下几种:
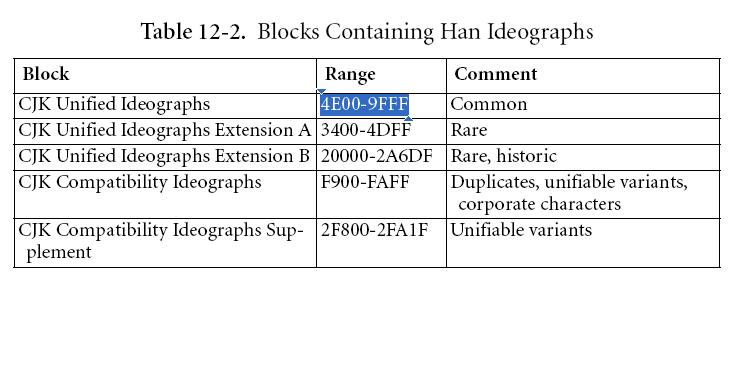
所以对于我们这个简单的算法只要判断字符是否在0x4E00~0X9FFF之间就可以了,实现后仅仅这个因素性能提升就可以提升7倍(当然还有方法调用的消耗)。















 8000
8000

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









