







首先简单介绍一下MongoDB:
MongoDB是一个基于分布式文件存储的数据库。由C++语言编写。旨在为WEB应用提供可扩展的高性能数据存储解决方案。
MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。它支持的数据结构非常松散,是类似json的bson格式,因此可以存储比较复杂的数据类型。Mongo最大的特点是它支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。
下面看一下MongoDb的存储方案:
MongoDB中的二进制数据存储存储在两个部分:
1、自身的文档存储(BSON格式的数据),有尺寸限制,最大为16M。
2、GridFS外部存储系统,适合大文件存储。
MongoDb的内部文件结构:
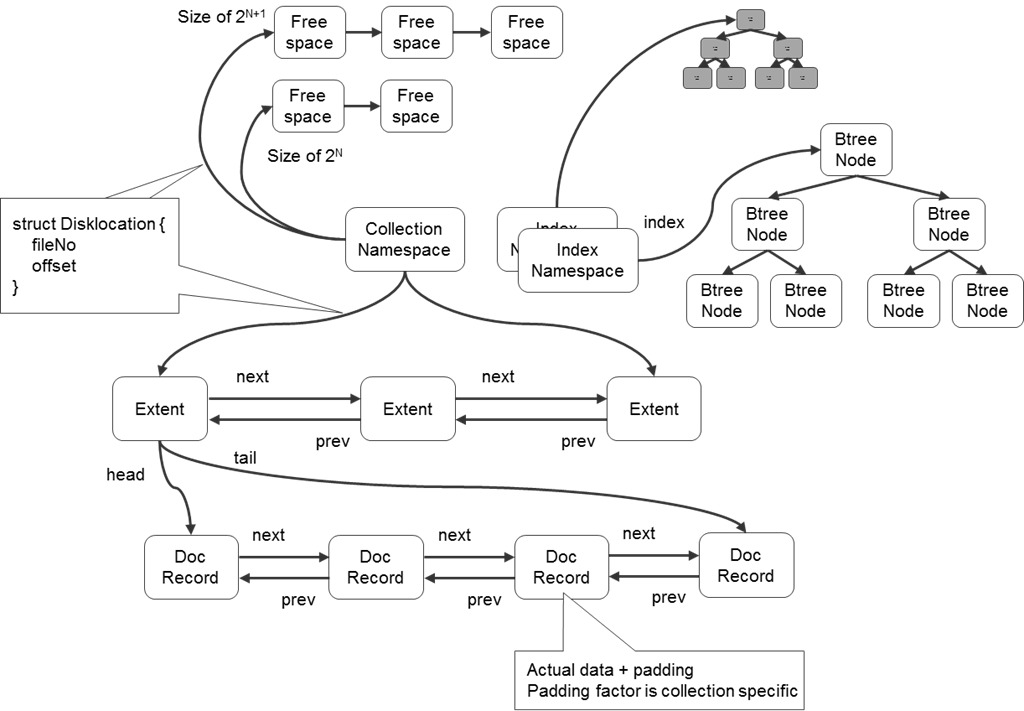
- MongoDB在数据存储上按命名空间来划分,一个collection是一个命名空间,一个索引也是一个命名空间
- 同一个命名空间的数据被分成很多个Extent,Extent之间使用双向链表连接
- 在每一个Extent中,保存了具体每一行的数据,这些数据也是通过双向链接连接的
- 每一行数据存储空间不仅包括数据占用空间,还可能包含一部分附加空间,这使得在数据update变大后可以不移动位置
- 索引以BTree结构实现
然后是GridFs的结构
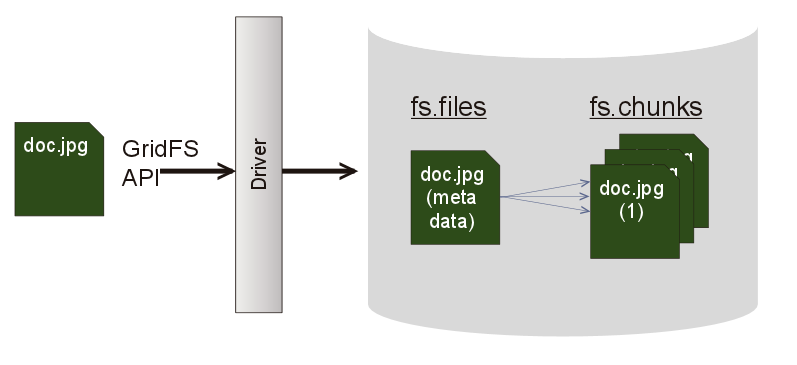
GridFS在数据库中,默认使用fs.chunks和fs.files来存储文件。
其中fs.files集合存放文件的信息,fs.chunks存放文件数据。
一个fs.files集合中的一条记录内容如下,即一个file的信息如下:
| 1 2 3 4 5 6 7 8 9 10 |
|
对应的fs.chunks中的chunk如下:
| 1 2 3 4 5 6 |
|
文件存入到GridFS过程中,如果文件大于chunksize,则把文件分割成多个chunk,再把这些chunk保存到fs.chunks中,最后再把文件信息存入到fs.files中。
在读取文件的时候,先据查询的条件,在fs.files中找到一个合适的记录,得到“_id”的值,再据这个值到fs.chunks中查找所有“files_id”为“_id”的chunk,并按“n”排序,最后依次读取chunk中“data”对象的内容,还原成原来的文件。
什么时候适合使用Gridfs
Gridfs最适合大文件存储 ,特别是视频,音频,大型图片超过16MB大小的文件。小型文件也可以存储,不过需要付出2次查询代价(metadata与file content)。不要修改存储文件的内容,而是更新文件元数据如版本,或上传新版本的文件,删除老版本的文件。对于大量文件存储时,需要多个数据节点,复制,数据分片等。 从互联网存储图片案例来看,图片大都是jpg, png与缩略图文件,分布式文件系统(DFS)会是更好的解决方案。















 2384
2384

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









