







关于 Apache Pulsar
Apache Pulsar 是 Apache 软件基金会顶级项目,是下一代云原生分布式消息流平台,集消息、存储、轻量化函数式计算为一体,采用计算与存储分离架构设计,支持多租户、持久化存储、多机房跨区域数据复制,具有强一致性、高吞吐、低延时及高可扩展性等流数据存储特性。
因基准测试报告较长,本篇文章为摘要部分。点击阅读原文即可下载完整版报告。
摘要
如今,为开发新产品和服务,许多公司纷纷开始关注实时数据流应用程序。企业必须首先了解不同事件流系统的优势和差异,才能选出与其业务需求最匹配的技术。
基准测试是各企业比较和衡量不同技术性能的一种方法。为了使该测试有参考价值,必须准确开展测试,并输出准确的信息。遗憾的是,总有诸多因素会影响基准测试的准确性。
备注:Confluent 最近发布博客《Apache Kafka、Apache Pulsar 与 RabbitMQ 基准测试:哪个运行最快?》,StreamNative 重复基准测试,并对此文做出了回应。有关系统介绍,可以参考“Pulsar 和 Kafka 的对比”:
第一部分:https://mp.weixin.qq.com/s/B_17Yxuv7JU81J6ZZGLVQQ
第二部分:https://streamnative.io/en/blog/tech/2020-07-22-pulsar-vs-kafka-part-2
Confluent 最近开展了一次基准测试,对比 Kafka、Pulsar 和 RabbitMQ 的吞吐量和延迟差异。Confluent 博客显示,Kakfa 能够以“低延迟”实现“最佳吞吐量”,而 RabbitMQ 能够以“较低的吞吐量” 达到 “低延迟”。总体而言,基准测试结果显示 Kafka 在“速度”方面无疑更胜一筹。
Kafka 技术成熟完善,但当今众多公司(从跨国公司到创新型初创公司)还是首先选择了 Pulsar。在近期举办的 Splunk 峰会 conf20 上,Splunk 公司首席产品官 Sendur Sellakumar 对外宣布,他们决定用 Pulsar 取代 Kafka:
“...我们已把 Apache Pulsar 作为基础流。我们把公司的前途压在了企业级多租户流的长期架构上。”
-- Splunk 首席产品官 Sendur Sellakumar
很多公司都在使用 Pulsar,Splunk 只是其中一例。这些公司之所以选择 Pulsar,是因为在现代弹性云环境(如 Kubernetes)中,Pulsar 能够以经济有效的方式横向扩展处理海量数据,不存在单点失效的问题。同时,Pulsar 具有诸多内置特性,诸如数据自动重平衡、多租户、跨地域复制和持久化分层存储等,不仅简化了运维,同时还让团队更容易专注于业务目标。
开发者们最终选择 Pulsar 是因为 Pulsar 这些独特的功能和性能,让 Pulsar 成了流数据的基石。
了解了这些情况后,还需仔细研究 Confluent 的基准测试设置和结论。我们发现有两个问题存在高度争议。
其一,Confluent 对 Pulsar 的了解有限,这正是造成结论不准确的最大根源。如不了解 Pulsar,就不能用正确的衡量标准来测试 Pulsar 性能。
其二,Confluent 的性能测试基于一组狭窄的测试参数。这限制了结果的适用性,也无法为读者提供不同工作负载和实际应用场景相匹配的准确结果。
为了向社区提供更准确的测试结果,我们决定解决这些问题并重复测试。重要调整包括:
我们调整了基准测试设置,包含了 Pulsar 和 Kafka 支持的各持久性级别,在同一持久性级别下对比两者的吞吐量和延迟。
我们修复了 OpenMessaging 基准测试(OMB)框架,消除因运用不同实例产生的变量,并纠正了 OMB Pulsar 驱动程序中的配置错误。
最后,我们测量了其他性能因素和条件,例如分区的不同数量和包含 write、tailing-read 和 catch-up read 的混合工作负载,更全面地了解性能。
完成这些工作之后,我们重复了测试。测试结果显示,对于更接近真实工作负载的场景,Pulsar 的性能明显优于 Kafka,而对于 Confluent 在测试中所应用的基本场景,Pulsar 性能与 Kafka 性能相当。
以下各部分将重点说明本次测试得出的最重要结论。在 StreamNative 基准测试结果章节,我们详细介绍了测试设置和测试报告。
StreamNative 基准测试结果概要
| 1: 在与 Kafka 的持久性保证相同的情况下,Pulsar 可达到 605 MB/s 的发布和端到端吞吐量(与 Kafka 相同)以及 3.5 GB/s 的 catch-up read 吞吐量(比 Kafka 高 3.5 倍)。Pulsar 的吞吐量不会因分区数量的增加和持久性级别的改变而受到影响,而 Kafka 的吞吐量会因分区数量或持久性级别的改变而受到严重影响。 |

表 1:在不同工作负载及不同持久性保证下,Pulsar 与 Kafka 的吞吐量差异
1. 有关 Pulsar 和 Kafka 持久性差异的详细探讨,可查阅“分布式系统的持久性概述”一节。
2:在不同的测试实例(包括不同订阅数量、不同主题数量和不同持久性保证)中,Pulsar 的延迟显著低于 Kafka。 |
Pulsar P99 延迟在 5 到 15 毫秒之间。Kafka P99 延迟可能长达数秒,并且会因主题数量、订阅数量和不同持久性保证而受到巨大影响。
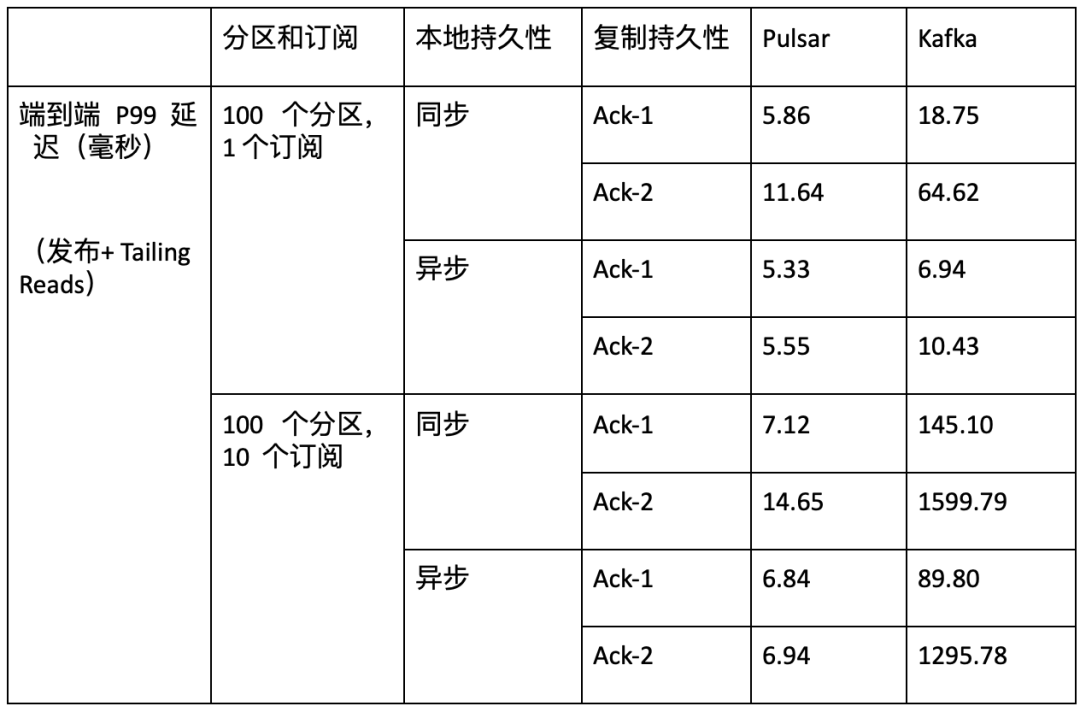
表 2:在不同订阅数量及不同持久性保证下,Pulsar 与 Kafka 端到端 P99 延迟差异
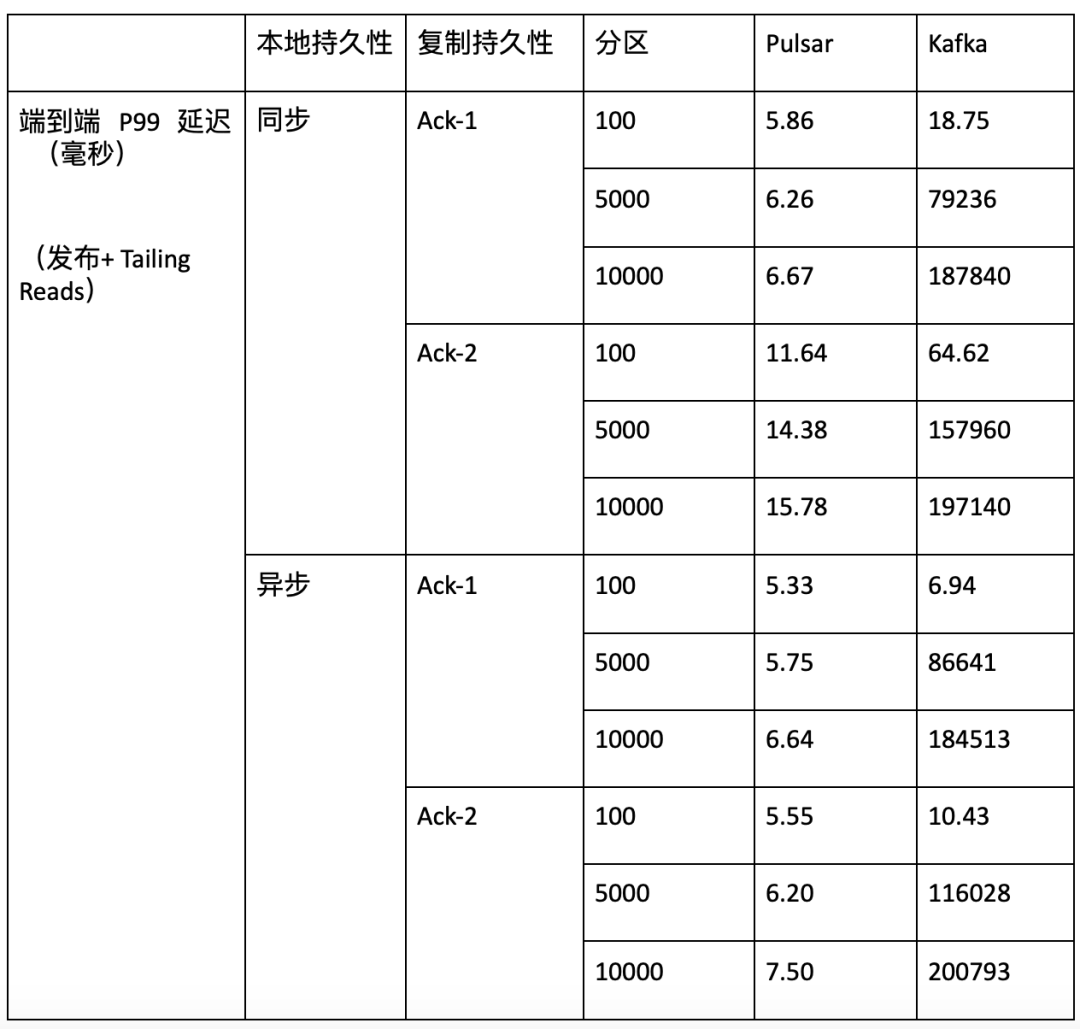
表 3:在不同主题数量及不同持久性保证下,Pulsar 与 Kafka 端到端 P99延迟差异
3:Pulsar 的 I/O 隔离显著优于 Kafka。在有消费者 catch up 读取历史数据时,Pulsar P99 发布延迟仍然在 5 毫秒左右。相比之下,Kafka 的延迟会因 catch up read 而受到严重影响。Kafka P99 发布延迟可能会从几毫秒增加到几秒。 |
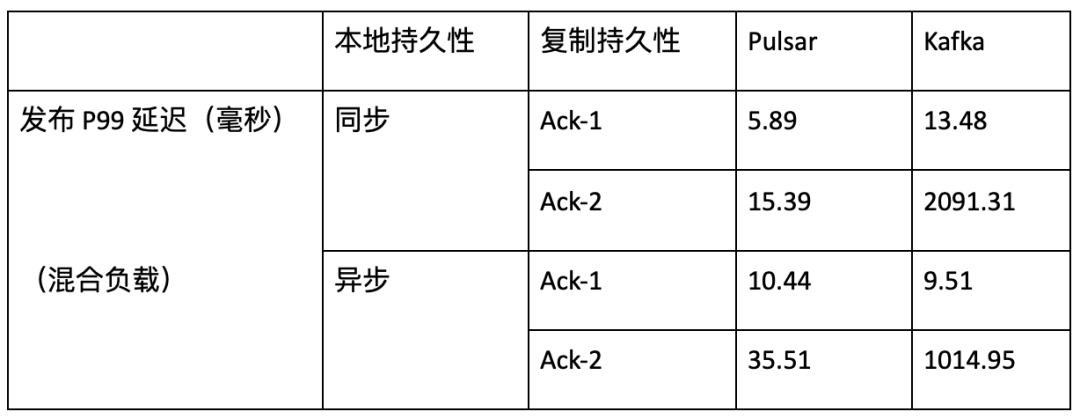
表 4:在 catch up read 下,Pulsar 和 Kafka P99发布延迟差异
我们所有的基准测试均开源,感兴趣的读者可以自行生成结果,也可更深入研究该测试结果及仓库中提供的指标。 点击阅读原文也可下载完整版报告。
尽管我们的基准测试比 Confluent 的基准测试更准确全面,但并未涵盖全部场景。归根结底,通过自己的硬件/实际工作负载进行的测试,是任何一个基准测试都替代不了的。我们也鼓励各位读者评估其他变量和场景,并利用自己的设置和环境进行测试。
点击阅读原文,获取完整版报告 ☟


















 873
873

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









