






对于线性回归模型,使用L1正则化的模型建叫做Lasso回归,使用L2正则化的模型叫做Ridge回归(岭回归)。
1. L1和L2正则化(Regularization)
L1正则化,又叫Lasso Regression
如下图所示,L1是向量各元素的绝对值之和
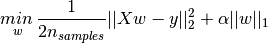
L2正则化,又叫Ridge Regression
如下图所示,L2是向量各元素的平方和
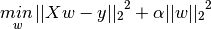
表示特征的系数,从上式可以看到正则化项是对系数做了处理(限制)。
也被称为权重衰减(weight decay)
2. L1 L2 区别:
相同点:都用于避免过拟合
不同点:L1可以让一部分特征的系数缩小到0,从而间接实现特征选择。所以L1适用于特征之间有关联的情况。
L2让所有特征的系数都缩小,但是不会减为0,它会使优化求解稳定快速。所以L2适用于特征之间没有关联的情况
1. L2 regularizer :使得模型的解偏向于 norm 较小的 W,通过限制 W 的 norm 的大小实现了对模型空间的限制,从而在一定程度上避免了 overfitting 。不过 ridge regression 并不具有产生稀疏解的能力,得到的系数 仍然需要数据中的所有特征才能计算预测结果,从计算量上来说并没有得到改观。会选择更多的特征,这些特征都会接近于0。 最优的参数值很小概率出现在坐标轴上,因此每一维的参数都不会是0。当最小化||w||时,就会使每一项趋近于0
2. L1 regularizer : 它的优良性质是能产生稀疏性,因为最优的参数值很大概率出现在坐标轴上,这样就会导致某一维的权重为0 ,产生稀疏权重矩阵, 导致 W 中许多项变成零。 稀疏的解除了计算量上的好处之外,更重要的是更具有“可解释性”。
1. 权重衰减(weight decay)
L2正则化的目的就是为了让权重衰减到更小的值,在一定程度上减少模型过拟合的问题,所以权重衰减也叫L2正则化。
1.1 L2正则化与权重衰减系数
L2正则化就是在代价函数后面再加上一个正则化项:
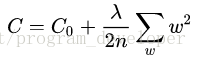
其中C0代表原始的代价函数,后面那一项就是L2正则化项,它是这样来的:所有参数w的平方的和,除以训练集的样本大小n。λ就是正则项系数,权衡正则项与C0项的比重。另外还有一个系数1/2,1/2 经常会看到,主要是为了后面求导的结果方便,后面那一项求导会产生一个2,与1/2相乘刚好凑整为1。系数λ就是权重衰减系数。
1.2 为什么可以对权重进行衰减
我们对加入L2正则化后的代价函数进行推导,先求导:
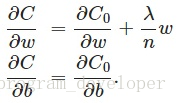
可以发现L2正则化项对b的更新没有影响,但是对于w的更新有影响:
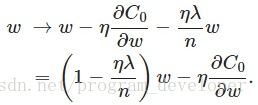
在不使用L2正则化时,求导结果中w前系数为1,现在w前面系数为1-ηλ/n,因为η、λ、n都是正的,所以1-ηλ/n小于1,它的效果是减小w,这也就是权重衰减(weight decay)的由来。当然考虑到后面的导数项,w最终的值可能增大也可能减小。
另外,需要提一下,对于基于mini-batch的随机梯度下降,w和b更新的公式跟上面给出的有点不同:
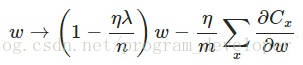
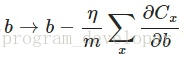
对比上面w的更新公式,可以发现后面那一项变了,变成所有导数加和,乘以η再除以m,m是一个mini-batch中样本的个数。
1.3 权重衰减(L2正则化)的作用
作用: 权重衰减(L2正则化)可以避免模型过拟合问题。
思考: L2正则化项有让w变小的效果,但是为什么w变小可以防止过拟合呢?
原理:
(1)从模型的复杂度上解释:更小的权值w,从某种意义上说,表示网络的复杂度更低,对数据的拟合更好(这个法则也叫做奥卡姆剃刀),而在实际应用中,也验证了这一点,L2正则化的效果往往好于未经正则化的效果。
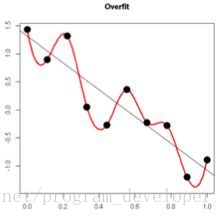
(2)从数学方面的解释:过拟合的时候,拟合函数的系数往往非常大,为什么?如下图所示,过拟合,就是拟合函数需要顾忌每一个点,最终形成的拟合函数波动很大。在某些很小的区间里,函数值的变化很剧烈。这就意味着函数在某些小区间里的导数值(绝对值)非常大,由于自变量值可大可小,所以只有系数足够大,才能保证导数值很大。而正则化是通过约束参数的范数使其不要太大,所以可以在一定程度上减少过拟合情况。
2、TensorFlow 版本的 weight decay 源码实现
def add_weight_decay(self, weights, lambda=5e-3):
weight_decay = tf.multiply(
tf.nn.l2_loss(weights), lambda, name='weight_loss')
tf.add_to_collection(tf.GraphKeys.REGULARIZATION_LOSSES,
weight_decay)
return weights这里定义了一个add_weight_decay函数,使用了tf.nn.l2_loss函数,其中参数lambda就是我们的λ正则化系数;
使用时需要先传入权重变量:
w = tf.Variable(tf.truncated_normal(shape=[128, 1024]))
w = add_weight_decay(w)这时我们已经将w的L2正则化Loss放入了REGULARIZATION_LOSSES这个集合里,再在Loss中加入正则化Loss即可
regular_loss = tf.get_collection(
tf.GraphKeys.REGULARIZATION_LOSSES)
regular_loss = tf.add_n(regular_loss)
loss = loss + regular_loss
PyTorch 实现
参考:Pytorch优化器的权重衰减(weight_decay)_笨笨的蛋的博客-CSDN博客
4. 学习率衰减(learning rate decay)
在训练模型的时候,通常会遇到这种情况:我们平衡模型的训练速度和损失(loss)后选择了相对合适的学习率(learning rate),但是训练集的损失下降到一定的程度后就不在下降了,比如training loss一直在0.7和0.9之间来回震荡,不能进一步下降。如下图所示:
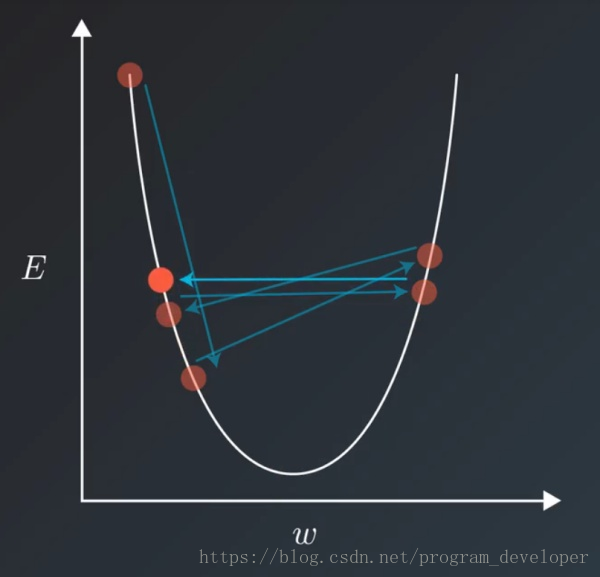
遇到这种情况通常可以通过适当降低学习率(learning rate)来实现。但是,降低学习率又会延长训练所需的时间。
学习率衰减(learning rate decay) 就是一种可以平衡这两者之间矛盾的解决方案。学习率衰减的基本思想是:学习率随着训练的进行逐渐衰减。
学习率衰减基本有两种实现方法:
线性衰减。例如:每过5个epochs学习率减半。
指数衰减。例如:随着迭代轮数的增加学习率自动发生衰减,每过5个epochs将学习率乘以0.9998。具体算法如下:
decayed_learning_rate=learning_rate*decay_rate^(global_step/decay_steps)
其中decayed_learning_rate为每一轮优化时使用的学习率,learning_rate为事先设定的初始学习率,decay_rate为衰减系数,decay_steps为衰减速度。
Reference
权重衰减(weight decay)与学习率衰减(learning rate decay)_Microstrong0305的博客-CSDN博客
机器学习中的范数规则化之(一)L0、L1与L2范数_zouxy09的博客-CSDN博客
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









