









1、前言
今天想谈谈ptmalloc如何为应用程序分配释放内存的,基于以下几点原因才聊它:
- C/C++ 70%的问题是内存问题。了解一点分配器原理对解决应用程序内存问题肯定有帮助。
- C++也在用ptmalloc. 当你在C++中new一个对象时,底层还是依赖glibc中的ptmalloc.
- 虽然市面上还有jemalloc/tcmalloc, 但ptmalloc被glibc内嵌,用的最广.
2、初识ptmalloc
ptmalloc是glibc(GNU C库)中使用的内存分配器,它基于dlmalloc(Doug Lea’s Malloc)的设计。ptmalloc的主要目标是为多线程应用程序提供高效的内存分配和释放,其名称中的“pt”代表“pthreads”,即POSIX线程库。
ptmalloc所有版本的源代码可在Index of /gnu/glibc下载,其中2.26为了增强多线程情况下的性能引入了tcache, 不过为了使讲解简单,我们还是以2.26之前的版本2.17来分析其原理。
相信很多程序员都思考过一个问题而且也知道答案:
free函数释放内存时只有一个参数 -- 要释放内存的指针,那要释放多大的内存哪???
答案就是这块内存前面的8个字节(64bit下,之后默认都是64bit)存了这块内存大小,让我们看个例子快速入门一下:
void *p1= malloc(10);
memset(p1,'a',10);
就像大大小小不同种类的卡车都有个车斗拉东西,ptmalloc的卡车叫malloc chunk用来拉内存, 它有自重,0x602000~0x602010便是自重(大小:0x10字节,有个特例,以后再说),对用户来说浪费掉了不能用来拉东西,还剩0x20-0x10=0x10个字节可以放用户数据,比我们申请的10个字节多一点点,这是故意预留的。

ptmalloc本质就是一个内存缓冲池,缓存的最小单位就是malloc chunk. 之后我们提到chunk或者malloc chunk都是一个东西。即使free的内存实际可能并没有free,而是被ptmalloc管理了起来。
3、卡车的定义 malloc_chunk
通过上面的例子我们看到了卡车的一个零部件:size(卡车大小)。那它有其它零部件吗?让我们看下它的庐山真面目:
struct malloc_chunk
{
INTERNAL_SIZE_T prev_size; /* 上一个malloc_chunk的size(如果它是free状态). */
INTERNAL_SIZE_T size; /* 本malloc_chunk的size,包括16个字节的自重 */
struct malloc_chunk *fd; /* 用来构造双向链表 -- 仅仅用在free的chunk上. */
struct malloc_chunk *bk; /* 用来构造双向链表 -- 仅仅用在free的chunk上. */
/* 以下两个字段用在large chunk上,以后介绍. */
struct malloc_chunk *fd_nextsize;
struct malloc_chunk *bk_nextsize;
};正如代码组织所暗示,两两一组, prev_size & size, fd & bk, fd_nextsize & bk_nextsize.
后两组只有在本chunk free的状态下才有意义,不然就存储用户数据。
3.1、prev_size & size 虚拟地址相邻的chunk
prev_size表示上个chunk的大小,只有上个chunk是free时才有此意义。size表示本chunk大小,但是最后三位从最不重要的位开始由特别意义分别表示:
- 相邻的上个chunk在用(非free, PREV_INUSE)
- 本chunk是由mmap()分配的(IS_MMAPPED)
- 本chunk是属于非主arena的(NON_MAIN_ARENA)
我们着重讲下第一个PREV_INUSE:
所有的chunk在虚拟地址上都是相邻的,就像火车车厢一样连在一起,

不过与直觉相反的是:不是自己表示自己空不空,而是由下一个chunk表示上一个chunk空不空(原因在下面的总结中)。
下面看个例子理解下PREV_INUSE、prev_size:
int main(int argc, char* argv[])
{
void *p1= malloc(192); //192是故意的,较小的数字free后会到fastbin中
//PREV_INUSE依然保持1,那样达不到演示PREV_INUSE的效果
memset(p1,'a',192); //原因在fastbin中介绍
void *p2= malloc(20);
memset(p2,'b',20);
free(p1);
}调试到free但还没free,通过下图理解下p2所在malloc chunk前两个字段的意义。

(gdb) p *(mchunkptr)(p2-16)
$2 = {prev_size = 0, size = 33, fd = 0x6262626262626262, bk = 0x6262626262626262, fd_nextsize = 0x62626262,
bk_nextsize = 0x20f11}然后把p1释放,再看下p2 malloc chunk.size:

(gdb) p *(mchunkptr)(p2-16)
$3 = {prev_size = 208, size = 32, fd = 0x6262626262626262, bk = 0x6262626262626262, fd_nextsize = 0x62626262,
bk_nextsize = 0x20f11}
这里眼尖的同学可能已经注意到prev_size只有在上个chunk free的状态下有意义,如果上个chunk分配给用户了则什么也没存,浪费掉了!ptmalloc的作者早就想到了这一点:prev_size这8个字节还真可以让渡给上个chunk用来存用户数据,我们把上面程序中的192改成194或者200看一看

总结一下:
1. prev size, prev inuse中的prev指的是物理上相邻的两个chunk的前一个(内存地址小的那个)
2. size字段指本chunk自己的size大小,包括自重(overhead)。size的最不重要的三位(bit)是三个flag,其中最后那个位(bit)表示上个chunk是否free,如果上个chunk是free则prev_size有意义且表示上个chunk的size。为什么要在一个chunk里存上一个chunk的size哪?这是为了方便两者都是free时好合并成一个大的chunk, p - prev_size就指向了上一个chunk。
3. malloc_chunk虽然有这么多数据成员,但只有size永远有意义,为了提高负载率其它字段在某种情况下会被用来放用户数据:a. 本chunk假如分配出去了(malloc),则fd、bk、fd_nextsize、bk_nextsize都无意义,可以用来放用户数据; b. 上个chunk假如分配出去了(malloc)且malloc的大小%8<=8, 则本chunk的prev_size字段会被用来存储上个chunk的用户数据。
3.2、fd & bk 逻辑上把free的chunk串起来
ptmalloc中有个bin的概念,正如字面意思就是回收垃圾用的垃圾桶(放free掉的chunk),bin有如下几类:
fastbin - 单向链表,放小chunk,默认为小到0x20大到0x80大小的,以16字节递进。比如main_arena.fastbinsY[0]指向大小为0x20的chunk链表,main_arena.fastbinsY[1]指向大小为0x30的chunk链表...
unsortedbin - 双向链表,临时垃圾桶,里面的chunk的size不一致。
smallbin - 双向链表,也是放小chunk,但上限到0x3F0, 以16字节递进, 共62个smallbin。
largebin - 双向链表,放大chunk, 63个.(largebin本节不具体展开)
main_arena是一个全局变量,它是一个很好的入口去找到这些bin,如下图示:
4、fastbin
fastbin, 正如它的名字,是用的最频繁的bin。当一块小内存被释放后,极大可能会被放到对应大小的fastbin链条上的,以加快下次分配同样大小的内存。
void* p1 = malloc(10);
free(p1);
void* p2 = malloc(10);上面这段代码,p1 p2应该是相等的。
fastbin是单链表,fd指向下一个;先释放的在链尾,后释放的放在链头。也就是说那些最近别使用过得内存更容易被再次使用;那些很久以前free掉最近都没用过的内存,有较大的概率被swap out了,重新使用的代价可能较大。
下面看个例子:
int main(int argc, char* argv[])
{
void *p1= malloc(10);
memset(p1,'a',10);
void *p2= malloc(10);
memset(p2,'b',10);
void *p3= malloc(30);
memset(p3,'c',10);
void *p4= malloc(30);
memset(p4,'d',10);
free(p1);
free(p2);
free(p3);
free(p4);
getchar();
#链接我自己编译出来的glibc
[mzhai]$ gcc fastbin.c -I/usr/local/glibc-2.17/include -L/usr/local/glibc-2.17/lib -Wl,--rpath=/usr/local/glibc-2.17/lib -Wl,--rpath=/lib64 -Wl,--dynamic-linker=/usr/local/glibc-2.17/lib/ld-2.17.so -g
[mzhai]$ gdb ./a.out
运行到getchar, 看下fastbinsY[0] & [1],
(gdb) p main_arena
$2 = {mutex = 0, flags = 0, fastbinsY = {0x602020, 0x602070, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0}, top = 0x6020a0,
last_remainder = 0x0, bins = {0x7ffff7dd7678 <main_arena+88>, 0x7ffff7dd7678 <main_arena+88>,
#chunk大小为0x20的链表.
(gdb) p /x *(mchunkptr)0x602020
$7 = {prev_size = 0x0, size = 0x21, fd = 0x602000, bk = 0x6262, fd_nextsize = 0x0, bk_nextsize = 0x31}
(gdb) p /x *(mchunkptr)0x602000
$8 = {prev_size = 0x0, size = 0x21, fd = 0x0, bk = 0x6161, fd_nextsize = 0x0, bk_nextsize = 0x21}
#chunk大小为0x30的链表。
(gdb) p /x *(mchunkptr)0x602070
$9 = {prev_size = 0x0, size = 0x31, fd = 0x602040, bk = 0x6464, fd_nextsize = 0x0, bk_nextsize = 0x0}
(gdb) p /x *(mchunkptr)0x602040
$10 = {prev_size = 0x0, size = 0x31, fd = 0x0, bk = 0x6363, fd_nextsize = 0x0, bk_nextsize = 0x0}

fastbin共有最多10个链表 ,已由arena.fastbinY[10]限制死,默认7个。用户能通过mallopt(M_MXFAST, value)个性化设置链表个数,但意义不大,最多也就10个。

5、unsortedbin
双向链表,临时垃圾桶,里面的chunk的size不一致。
是第二常用的bin,free时没进fastbin则大概率要进unsortedbin. 之后的malloc可能会把unsortedbin上的chunk挪到smallbin.
int main(int argc, char* argv[])
{
void *p1= malloc(200);
memset(p1,'a',200);
void *temp1= malloc(10); //把p1 p2隔开,防止合并
memset(temp1,'b',10);
void *p2= malloc(300);
memset(p2,'a',300);
void *temp2= malloc(10); //把p2 top 隔开,防止合并
memset(temp2,'c',10);
free(p1);
free(p2);
getchar();
调试到getchar,
(gdb) p main_arena
$1 = {mutex = 0, flags = 1, fastbinsY = {0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0}, top = 0x602250,
last_remainder = 0x0, bins = {0x6020f0, 0x602000(gdb) p *(mchunkptr)0x6020f0
$4 = {prev_size = 0, size = 321, fd = 0x602000, bk = 0x7ffff7dd7678 <main_arena+88>, fd_nextsize = 0x6161616161616161,
bk_nextsize = 0x6161616161616161}
(gdb) p *(mchunkptr)0x602000
$5 = {prev_size = 0, size = 209, fd = 0x7ffff7dd7678 <main_arena+88>, bk = 0x6020f0, fd_nextsize = 0x6161616161616161,
bk_nextsize = 0x6161616161616161}

6、smallbin
双向链表,也是放小chunk,但上限到0x3F0, 以16字节递进, 共62个smallbin。
smallbin与unsortedbin相似,都是双向链表,不同的是:smallbin每个链上chunk大小相等,这一点与fastbin一致。
free时不会直接往smallbin里扔chunk,而是malloc时把unsortedbin里的chunk整理到对应的smallbin链上。
请看下面的例子:
int main(int argc, char* argv[])
{
void *p1= malloc(30);
void *temp1= malloc(10);
void *p2= malloc(30);
void *temp2= malloc(10);
void *p3= malloc(30);
void *temp3= malloc(10);
free(p1);
free(p2);
free(p3); //fastbin 0x30链表上p3->p2->p1
void* large = malloc(1024); //fastbin->unsortedbin->smallbin
getchar();
free(p3)后
(gdb) p main_arena
$1 = {mutex = 0, flags = 0, fastbinsY = {0x0, 0x6020a0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0}, top = 0x6020f0,
last_remainder = 0x0, bins = {0x7ffff7dd7678 <main_arena+88>, 0x7ffff7dd7678 <main_arena+88>,
0x7ffff7dd7688 <main_arena+104>, 0x7ffff7dd7688 <main_arena+104>, 0x7ffff7dd7698 <main_arena+120>,(gdb) p *(mchunkptr)0x6020a0
$2 = {prev_size = 0, size = 49, fd = 0x602050, bk = 0x0, fd_nextsize = 0x0, bk_nextsize = 0x0}
(gdb) p *(mchunkptr)0x602050
$3 = {prev_size = 0, size = 49, fd = 0x602000, bk = 0x0, fd_nextsize = 0x0, bk_nextsize = 0x0}
(gdb) p *(mchunkptr)0x602000
$4 = {prev_size = 0, size = 49, fd = 0x0, bk = 0x0, fd_nextsize = 0x0, bk_nextsize = 0x0}
之后要分配1024字节,加上自重共1040个字节,借助这个malloc我们过一下malloc的大体流程:
1. 首先从fastbin中寻找。因为1040大于fastbin的范围(0x20~0x80/0xa0),找不到。
if ((unsigned long)(nb) <= (unsigned long)(get_max_fast ())) 2. 从smallbin中寻找。1040已超过smallbin的范围。
3315 if (in_smallbin_range(nb))
3355 else {
3356 idx = largebin_index(nb);
3357 if (have_fastchunks(av))
3358 malloc_consolidate(av); //fastbin -> unsortedbin
//只有要申请的字节数>=1024 且 fastbin不空 才触发 fastbin -> unsortedbin
//这才是我们的例子中要申请1024字节的原因
3359 } (gdb) p main_arena
$7 = {mutex = 1, flags = 1, fastbinsY = {0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0}, top = 0x6020f0,
last_remainder = 0x0, bins = {0x602000, 0x6020a0, 0x7ffff7dd7688 <main_arena+104>, 0x7ffff7dd7688 <main_arena+104>,
0x7ffff7dd7698 <main_arena+120>, 0x7ffff7dd7698 <main_arena+120>, 0x7ffff7dd76a8 <main_arena+136>,(gdb) p *(mchunkptr)0x602000
$8 = {prev_size = 0, size = 49, fd = 0x602050, bk = 0x7ffff7dd7678 <main_arena+88>, fd_nextsize = 0x0, bk_nextsize = 0x0}
(gdb) p *(mchunkptr)0x602050
$9 = {prev_size = 0, size = 49, fd = 0x6020a0, bk = 0x602000, fd_nextsize = 0x0, bk_nextsize = 0x0}
(gdb) p *(mchunkptr)0x6020a0
$10 = {prev_size = 0, size = 49, fd = 0x7ffff7dd7678 <main_arena+88>, bk = 0x602050, fd_nextsize = 0x0, bk_nextsize = 0x0}fastbin上的3个chunk 已被move到 unsortedbin上
3. 整理unsortedbin上的chunk到smallbin/largebin上
3377 while ( (victim = unsorted_chunks(av)->bk) != unsorted_chunks(av)) {
//从unsortedbin的最后一个chunk开始,unsorted_chunks(av)是那个虚拟chunk
3422 /* 把victic从unsortedbin上摘下来 */
3423 unsorted_chunks(av)->bk = bck;
3424 bck->fd = unsorted_chunks(av);
3439 /* 把victim放到相应的bin上(smallbin、largebin) */
3440
3441 if (in_smallbin_range(size)) {
3442 victim_index = smallbin_index(size);
3443 bck = bin_at(av, victim_index);
3444 fwd = bck->fd;
3445 }
3446 else {
3447 victim_index = largebin_index(size);
3448 bck = bin_at(av, victim_index);
3449 fwd = bck->fd; 4. 搜索largebin
5. 从top chunk割一块下来
6. 如果连top chunk都满足不了,调用sysmalloc从系统中分配
chunk move的过程,fastbin -> unsortedbin -> smallbin/largebin
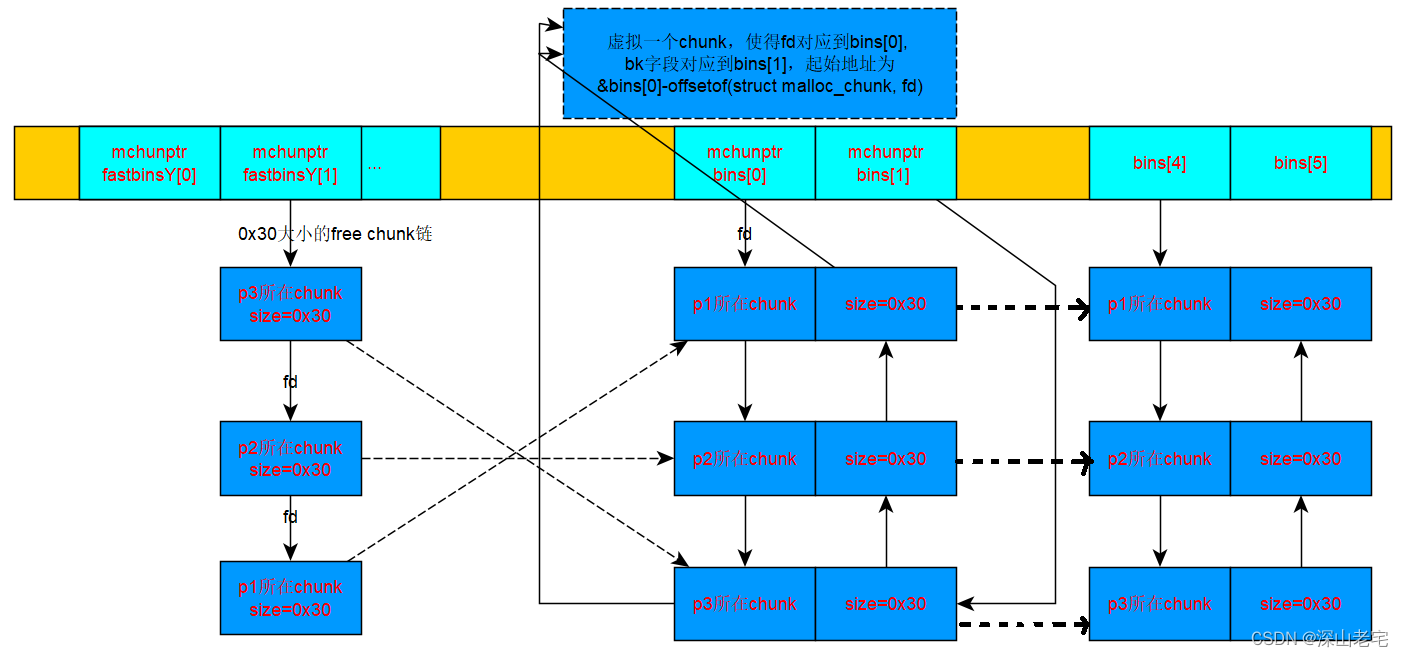
虽然这个例子很好的演示了chunk move的过程,但并没有诠释move的意义:正如malloc_consolidate名字所暗示的,它会合并fastbin中相邻的chunk以减少碎片,要知道fastbin的哲学是期盼同样小的内存申请很快到来,所以它不会合并相邻的chunk,这样时间长了碎片就会很多。看下面这个例子:
int main(int argc, char* argv[])
{
void *p1= malloc(30);
void *temp1= malloc(10);
void *p2= malloc(30);
void *temp2= malloc(10);
void *p3= malloc(30);
void *temp3= malloc(10);
free(p1);
free(p2);
free(p3);
void* large = malloc(1024);
(gdb) p main_arena
$1 = {mutex = 0, flags = 1, fastbinsY = {0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0}, top = 0x6024d0,
last_remainder = 0x0, bins = {0x7ffff7dd7678 <main_arena+88>, 0x7ffff7dd7678 <main_arena+88>,
0x7ffff7dd7688 <main_arena+104>, 0x7ffff7dd7688 <main_arena+104>, 0x7ffff7dd7698 <main_arena+120>,
0x7ffff7dd7698 <main_arena+120>, 0x7ffff7dd76a8 <main_arena+136>, 0x7ffff7dd76a8 <main_arena+136>,
0x7ffff7dd76b8 <main_arena+152>, 0x7ffff7dd76b8 <main_arena+152>, 0x7ffff7dd76c8 <main_arena+168>,
0x7ffff7dd76c8 <main_arena+168>, 0x7ffff7dd76d8 <main_arena+184>, 0x7ffff7dd76d8 <main_arena+184>,
0x7ffff7dd76e8 <main_arena+200>, 0x7ffff7dd76e8 <main_arena+200>, 0x602000, 0x602000,(gdb) p *(mchunkptr)0x602000
$2 = {prev_size = 0, size = 145, fd = 0x7ffff7dd76f8 <main_arena+216>, bk = 0x7ffff7dd76f8 <main_arena+216>,
fd_nextsize = 0x0, bk_nextsize = 0x0}
三个相邻的小碎片被 合体了!

















 257
257











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











