







第1章文字和语言VS数字和信息
文字作为信息的载体,而非信息本身,这就使得不同语言的文字可以相互翻译,因为它们承载信息的能力是等价的。实际上,数字也可以作为信息的载体,这构成了现代通信的基础。因此,文字和数字是统一的,它们都是信息编码的单位。
在早期,数字还是文字的一部分,但是阿拉伯数字的诞生,标志着数字和文字的分离,两者各自的发展,逐渐产生了数学和语言学。
人类文明早期的文字是象形文字,后来诞生了拼音文字,这是一个飞跃,它表示着人类记录信息的方式,从单纯的具体的外表进化到了抽象的概念,并且学会了对信息进行编码。
第2章自然语言处理:从规则到统计
受传统语言学研究的影响,最初科学家使用基于规则的方法即句法分析+语义分析来理解自然语言,但是遇到了很大的问题:
一是在句法分析中,文法规则几乎不可能覆盖多数的真实语句,同时过多的文法规则很难用计算机去解析(自然语言的复杂性);
二是在语义分析中,词的多义性等因素很难用基于规则的方法来解决。
随着基于统计的方法取得巨大的成果,自然语言处理研究逐渐从基于规则的方法过渡到基于统计的方法。
第3章统计语言模型
自然语言具有上下文相关的特性,让计算机对其进行处理,基本问题就是建立数学模型,也即统计语言模型。
贾里尼克的出发点:一个句子是否合理,取决于它的可能性大小(概率)。结合马尔科夫假设,就可以得到常用的二元模型、三元模型等。
这种模型理解起来较为简单,但存在许多细节问题,如平滑问题。解决平滑问题的方法是,将出现频率小于阈值的词(相对不可信)的概率打折扣,然后将折扣分给未看见的事件。
第4章谈谈分词
词是表达语义的最小单位,因此有必要先对句子进行分词。最简单的分词方法是查词典,但是无法解决较复杂的问题。而利用统计语言模型,只要使分词后句子出现的概率最大,就可以找到最佳分词方法。
第5章隐含马尔可夫模型
几乎所有的自然语言处理问题都可以等价为通信中的解码问题。在通信中,欲解码一接收到的信号,只需找出最有可能产生该信号的源信息。使用概率论的语言来说,就是在已知某事件(接收到了信号)发生的情况下,求事件(源信息是S)的发生的概率,使得这一条件概率最大的S即为所求(见图1)。这里可以使用贝叶斯公式(逆概率公式)来对公式变形,然后使用隐含马尔可夫模型来估计(需要用到下面两个假设)。
马尔可夫假设:随机过程中一个状态的概率分布,只与它的前一个状态有关。
独立输出假设:在隐含马尔可夫模型中,状态是不可见的,但是每个时刻会输出一个符号,该符号仅与当前状态有关。
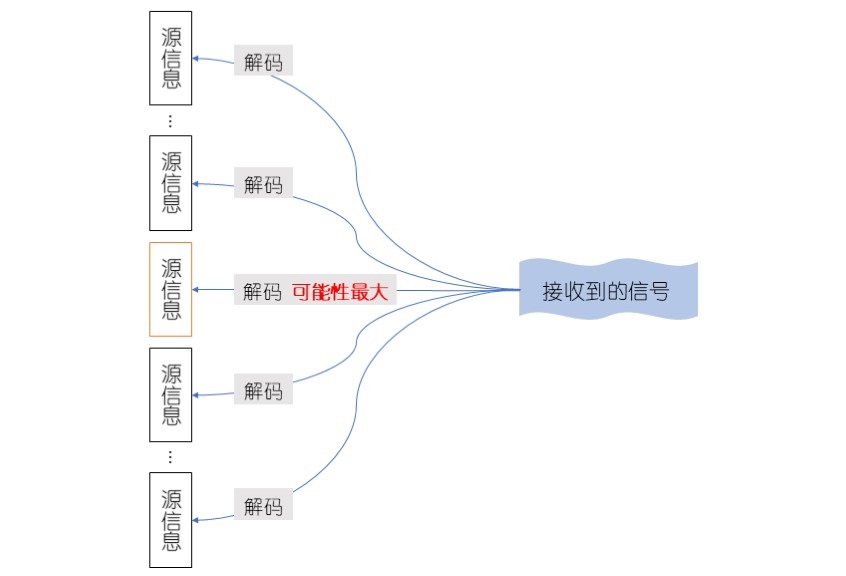
图1















 3067
3067











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









