







volatile的特性
可见性: 对于其他线程是可见,假设线程1修改了volatile修饰的变量,那么线程2是可见的,并且是线程安全的
重排序: 由于CPU执行的时候,指令在后面的会先执行,在指令层级的时候
我们晓得volatile的特性后,我们就要去volatile是如何实现的,这个很重要!!!
其实是通过内存屏障去实现的.
volatile的实现有很多层,我这里就简单说下
-
JVM
-
汇编层
-
CPU层
由于设计到的知识点偏多,后面的我简单介绍下,大家明白原理就行
JVM层
在JVM层,要求虚拟机实现不同的内存屏障,如以下
-
LoadLoad屏障:举例语句是Load1; LoadLoad; Load2 (这句里面的LoadLoad里面的第一个Load对应Load1加载代码,然后LoadLoad里面的第二个Load对应Load2加载代码),此时的意思就是,在Load2及后续读取操作从内存读取数据到CPU前,保证Load1从主内存里要读取的数据读取完毕。
-
StoreStore屏障:举例语句是 Store1; StoreStore; Store2 (这句里面的StoreStore里面的第一个Store对应Store1存储代码,然后StoreStore里面的第二个Store对应Store2存储代码)。此时的意思就是在Store2及后续写入操作执行前,保证Store1的写入操作已经把数据写入到主内存里面,确认Store1的写入操作对其它处理器可见。
-
LoadStore屏障:举例语句是 Load1; LoadStore; Store2 (这句里面的LoadStore里面的Load对应Load1加载代码,然后LoadStore里面的Store对应Store2存储代码),此时的意思就是在Store2及后续代码写入操作执行前,保证Load1从主内存里要读取的数据读取完毕。
-
StoreLoad屏障:举例语句是 Store1; StoreLoad; Load2 (这句里面的StoreLoad里面的Store对应Store1存储代码,然后StoreLoad里面的Load对应Load2加载代码),在Load2及后续读取操作从内存读取数据到CPU前,保证Store1的写入操作已经把数据写入到主内存里,确认Store1的写入操作对其它处理器可见。
这里是JVM要求虚拟机实现(抄的别人的),那么JVM层是如何实现的呢
汇编层(这里可能是废话,但是看看还是值得)
X86指令
-
sfence(写屏障): 在sfence指令的写操作当必须在sfence指令后写操作之前完成
-
fence(读屏障): 在ifence指令之前的读操作当必须在ifence指令前读操作完成.
-
mfence(全屏障): 在mefence指令前的读写操作当必须在mfence指令的读操作完成。
-
lock: CPU层级的锁,锁住地址总线,只允许当前CPU才能去访问内存
这里是了解下就可以,不用去记下来.
CPU层
虚拟机在真正实现内存屏障,是lock指令去实现, lock 锁住的什么呢, 锁住的地址总线,没有去用CPU自带的屏障, 这里我猜测可能这些屏障底层也是用的lock,猜测哈
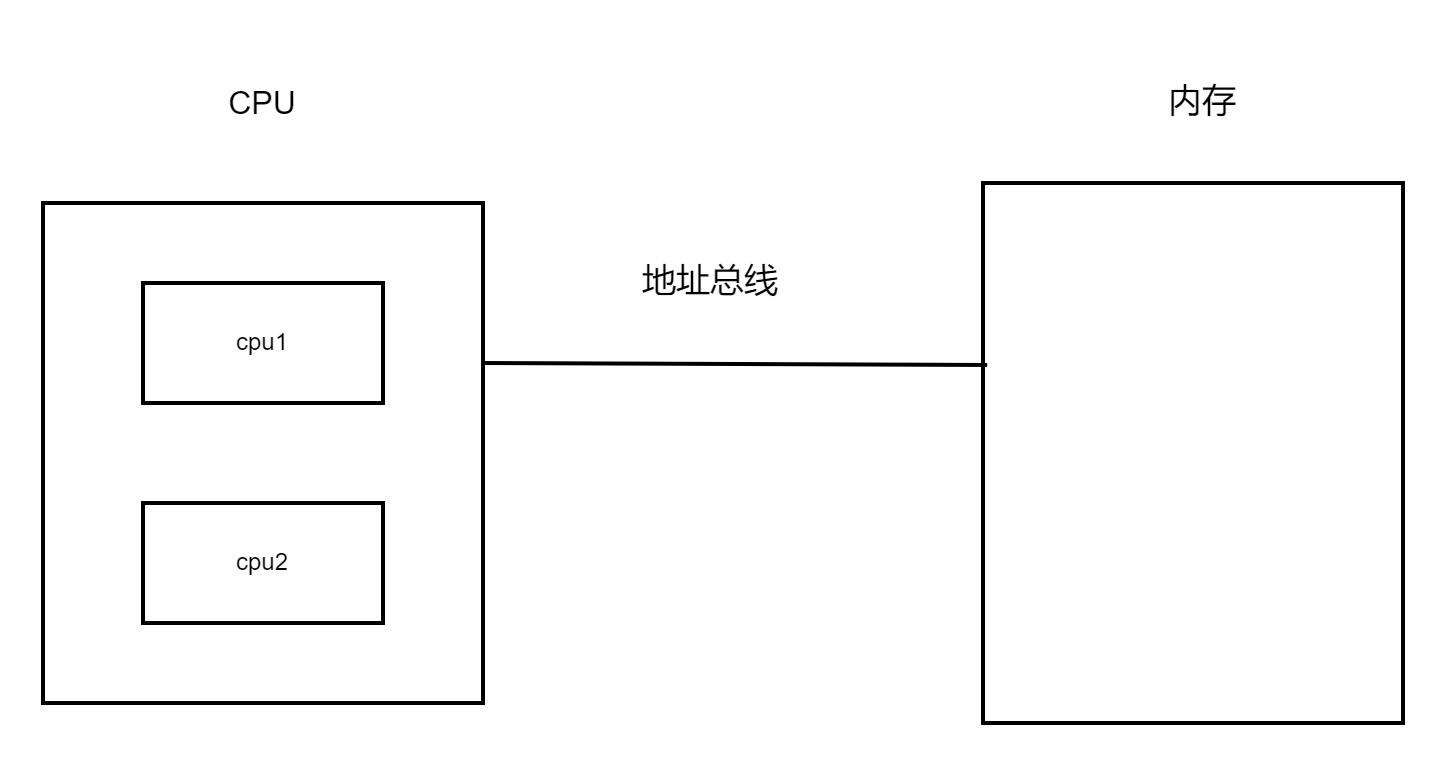
大概的图就是这个样子, 也就是说 这里的JVM 虚拟机实现的内存屏障,实际上是靠锁住地址总线来实现的,那么我的多线程就变成了单线程,性能降低了, 但是这里不用线程上下文切换,还是比较好。
我是如何得知这里是用的lock呢,我是把执行的代码汇编给打印出来了
源码
汇编

lock addl ... 后面的指令,实际上是往寄存器上加了一个0,实际上是一个空操作。
总结
volatile的内存屏障,实际上是通过汇编的lock来执行,lock 锁住了内存地址总线.
这个是我自己的理解,如果有不对的地方,请指出来,我做修改.
希望朋友看了这篇文章,能自己明白volatile,在面试的时候有更好的发挥
打广告
另外给自己打个广告,如果有重庆小伙伴需要招java的,可以联系我, 我微信290857007















 346
346











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









